 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning: A Survey on Privacy-Preserving Collaborative Intelligence
Apr 24, 2025Federated Learning (FL) has emerged as a transformative paradigm in the field of distributed machine learning, enabling multiple clients such as mobile devices, edge nodes, or organizations to collaboratively train a shared global model without the need to centralize sensitive data. This decentralized approach addresses growing concerns around data privacy, security, and regulatory compliance, making it particularly attractive in domains such as healthcare, finance, and smart IoT systems. This survey provides a concise yet comprehensive overview of Federated Learning, beginning with its core architecture and communication protocol. We discuss the standard FL lifecycle, including local training, model aggregation, and global updates. A particular emphasis is placed on key technical challenges such as handling non-IID (non-independent and identically distributed) data, mitigating system and hardware heterogeneity, reducing communication overhead, and ensuring privacy through mechanisms like differential privacy and secure aggregation. Furthermore, we examine emerging trends in FL research, including personalized FL, cross-device versus cross-silo settings, and integration with other paradigms such as reinforcement learning and quantum computing. We also highlight real-world applications and summarize benchmark datasets and evaluation metrics commonly used in FL research. Finally, we outline open research problems and future directions to guide the development of scalable, efficient, and trustworthy FL systems.
LIDA: Lightweight Interactive Dialogue Annotator
Nov 05, 2019
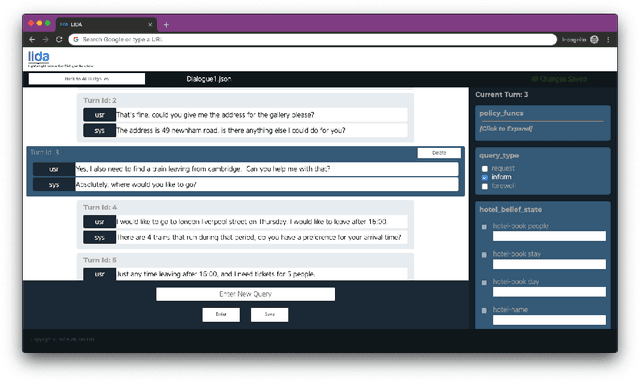
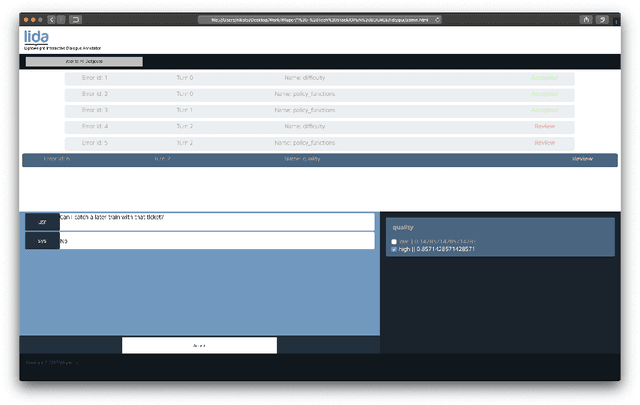
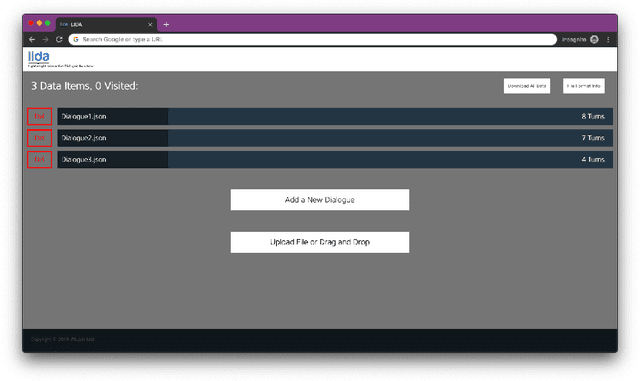
Dialogue systems have the potential to change how people interact with machines but are highly dependent on the quality of the data used to train them. It is therefore important to develop good dialogue annotation tools which can improve the speed and quality of dialogue data annotation. With this in mind, we introduce LIDA, an annotation tool designed specifically for conversation data. As far as we know, LIDA is the first dialogue annotation system that handles the entire dialogue annotation pipeline from raw text, as may be the output of transcription services, to structured conversation data. Furthermore it supports the integration of arbitrary machine learning models as annotation recommenders and also has a dedicated interface to resolve inter-annotator disagreements such as after crowdsourcing annotations for a dataset. LIDA is fully open source, documented and publicly available [ https://github.com/Wluper/lida ]
* 9 pages, 7 figures, 1 table, EMNLP 2019
Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks
Dec 07, 2018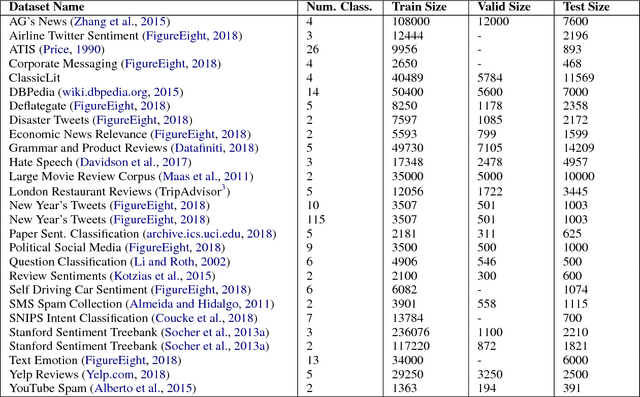
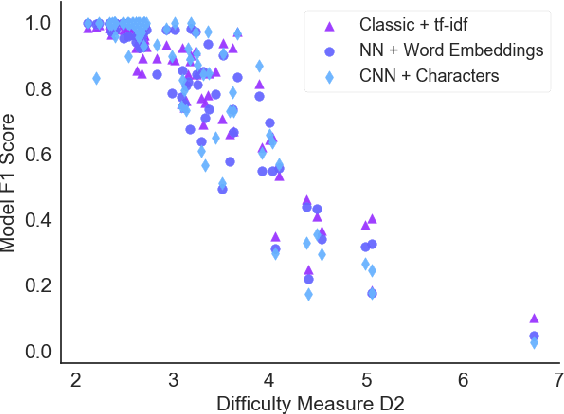

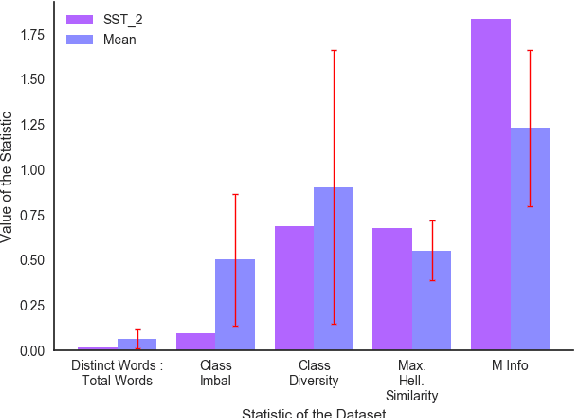
Classification tasks are usually analysed and improved through new model architectures or hyperparameter optimisation but the underlying properties of datasets are discovered on an ad-hoc basis as errors occur. However, understanding the properties of the data is crucial in perfecting models. In this paper we analyse exactly which characteristics of a dataset best determine how difficult that dataset is for the task of text classification. We then propose an intuitive measure of difficulty for text classification datasets which is simple and fast to calculate. We show that this measure generalises to unseen data by comparing it to state-of-the-art datasets and results. This measure can be used to analyse the precise source of errors in a dataset and allows fast estimation of how difficult a dataset is to learn. We searched for this measure by training 12 classical and neural network based models on 78 real-world datasets, then use a genetic algorithm to discover the best measure of difficulty. Our difficulty-calculating code ( https://github.com/Wluper/edm ) and datasets ( http://data.wluper.com ) are publicly available.
* 27 pages, 6 tables, 3 figures (submitted for publication in June 2018), CoNLL 2018