 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Comparability of Model Fusion to Measured Data in Confuser Rejection
May 01, 2025Data collection has always been a major issue in the modeling and training of large deep learning networks, as no dataset can account for every slight deviation we might see in live usage. Collecting samples can be especially costly for Synthetic Aperture Radar (SAR), limiting the amount of unique targets and operating conditions we are able to observe from. To counter this lack of data, simulators have been developed utilizing the shooting and bouncing ray method to allow for the generation of synthetic SAR data on 3D models. While effective, the synthetically generated data does not perfectly correlate to the measured data leading to issues when training models solely on synthetic data. We aim to use computational power as a substitution for this lack of quality measured data, by ensembling many models trained on synthetic data. Synthetic data is also not complete, as we do not know what targets might be present in a live environment. Therefore we need to have our ensembling techniques account for these unknown targets by applying confuser rejection in which our models will reject unknown targets it is presented with, and only classify those it has been trained on.
Robust SAR STAP via Kronecker Decomposition
May 05, 2016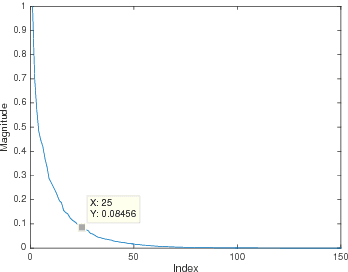
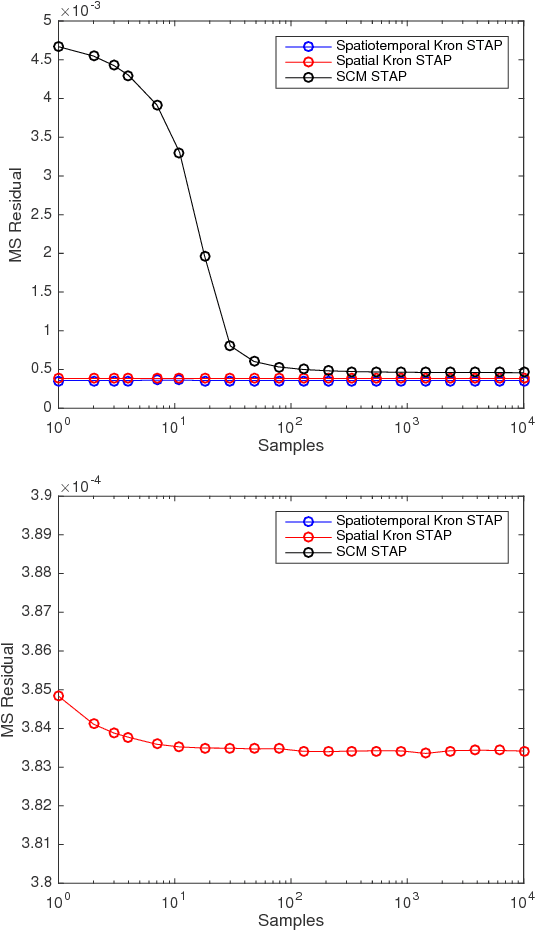
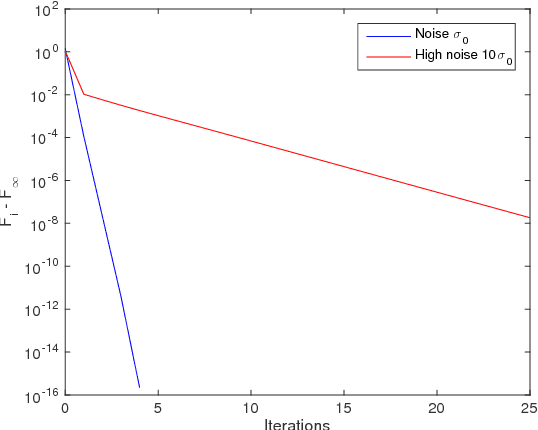
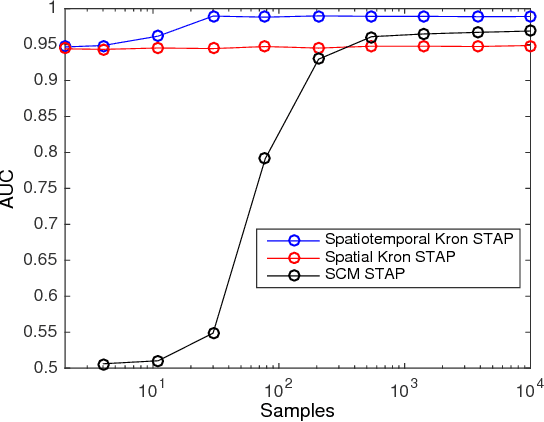
This paper proposes a spatio-temporal decomposition for the detection of moving targets in multiantenna SAR. As a high resolution radar imaging modality, SAR detects and localizes non-moving targets accurately, giving it an advantage over lower resolution GMTI radars. Moving target detection is more challenging due to target smearing and masking by clutter. Space-time adaptive processing (STAP) is often used to remove the stationary clutter and enhance the moving targets. In this work, it is shown that the performance of STAP can be improved by modeling the clutter covariance as a space vs. time Kronecker product with low rank factors. Based on this model, a low-rank Kronecker product covariance estimation algorithm is proposed, and a novel separable clutter cancelation filter based on the Kronecker covariance estimate is introduced. The proposed method provides orders of magnitude reduction in the required number of training samples, as well as improved robustness to corruption of the training data. Simulation results and experiments using the Gotcha SAR GMTI challenge dataset are presented that confirm the advantages of our approach relative to existing techniques.