 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Hierarchical Dependence Structures for Unsupervised Rank Fusion in Information Retrieval
Aug 10, 2022
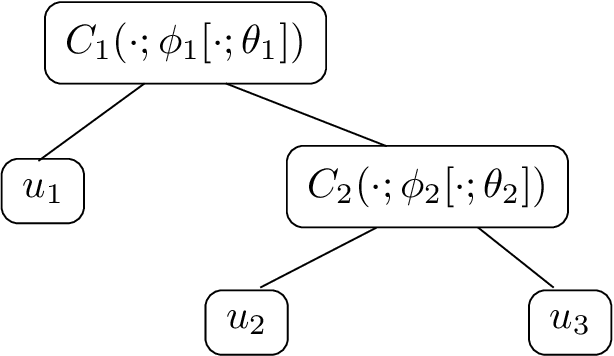
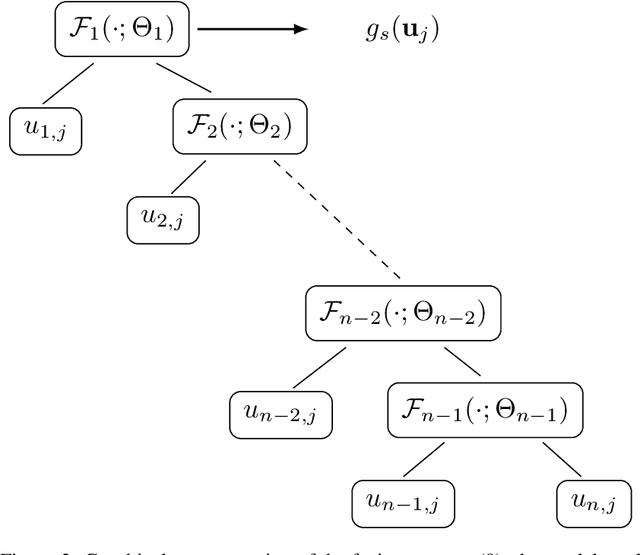
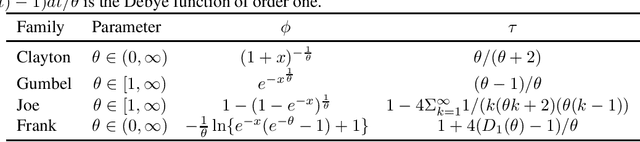
The goal of rank fusion in information retrieval (IR) is to deliver a single output list from multiple search results. Improving performance by combining the outputs of various IR systems is a challenging task. A central point is the fact that many non-obvious factors are involved in the estimation of relevance, inducing nonlinear interrelations between the data. The ability to model complex dependency relationships between random variables has become increasingly popular in the realm of information retrieval, and the need to further explore these dependencies for data fusion has been recently acknowledged. Copulas provide a framework to separate the dependence structure from the margins. Inspired by the theory of copulas, we propose a new unsupervised, dynamic, nonlinear, rank fusion method, based on a nested composition of non-algebraic function pairs. The dependence structure of the model is tailored by leveraging query-document correlations on a per-query basis. We experimented with three topic sets over CLEF corpora fusing 3 and 6 retrieval systems, comparing our method against the CombMNZ technique and other nonlinear unsupervised strategies. The experiments show that our fusion approach improves performance under explicit conditions, providing insight about the circumstances under which linear fusion techniques have comparable performance to nonlinear methods.
The Analysis of Synonymy and Antonymy in Discourse Relations: An interpretable Modeling Approach
Aug 09, 2022
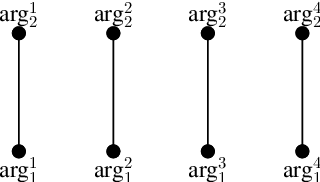

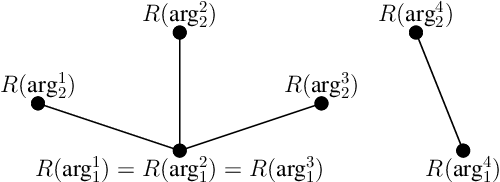
The idea that discourse relations are construed through explicit content and shared, or implicit, knowledge between producer and interpreter is ubiquitous in discourse research and linguistics. However, the actual contribution of the lexical semantics of arguments is unclear. We propose a computational approach to the analysis of contrast and concession relations in the PDTB corpus. Our work sheds light on the extent to which lexical semantics contributes to signaling explicit and implicit discourse relations and clarifies the contribution of different parts of speech in both. This study contributes to bridging the gap between corpus linguistics and computational linguistics by proposing transparent and explainable models of discourse relations based on the synonymy and antonymy of their arguments.