 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the Most Unusual Part of a Digital Image
Oct 19, 2008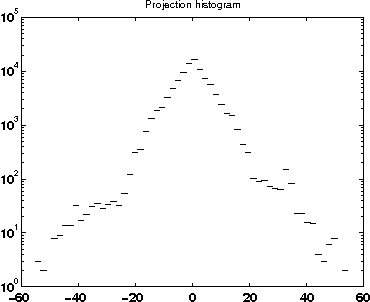
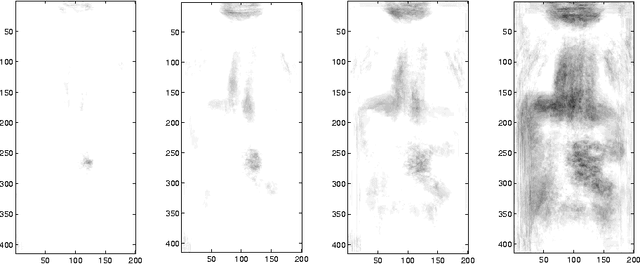
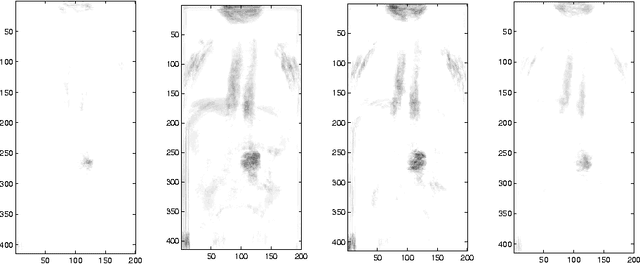
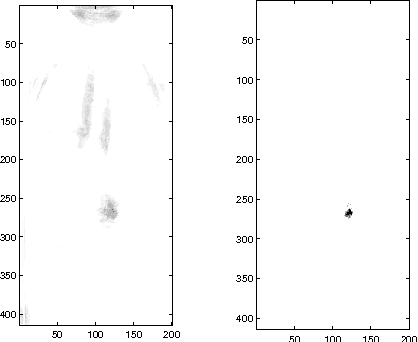
The purpose of this paper is to introduce an algorithm that can detect the most unusual part of a digital image. The most unusual part of a given shape is defined as a part of the image that has the maximal distance to all non intersecting shapes with the same form. The method can be used to scan image databases with no clear model of the interesting part or large image databases, as for example medical databases.
Text as Statistical Mechanics Object
Oct 19, 2008In this article we present a model of human written text based on statistical mechanics approach by deriving the potential energy for different parts of the text using large text corpus. We have checked the results numerically and found that the specific heat parameter effectively separates the closed class words from the specific terms used in the text.