 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefuse: Harnessing Unrestricted Adversarial Examples for Debugging Models Beyond Test Accuracy
Feb 11, 2021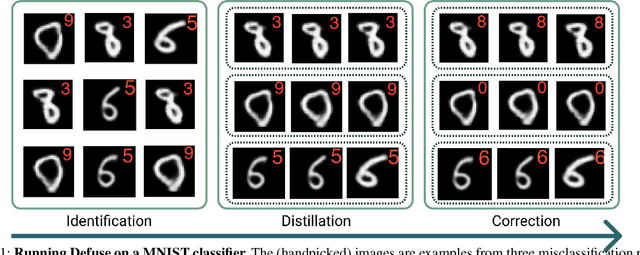
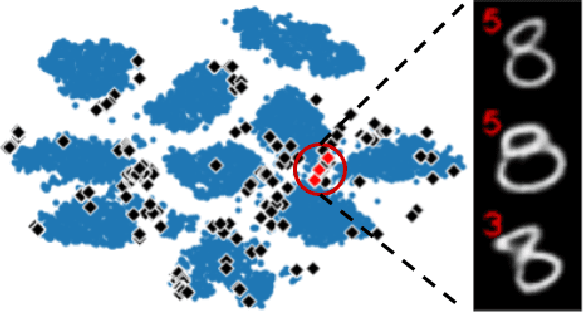

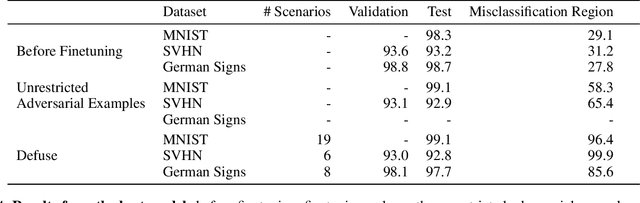
We typically compute aggregate statistics on held-out test data to assess the generalization of machine learning models. However, statistics on test data often overstate model generalization, and thus, the performance of deployed machine learning models can be variable and untrustworthy. Motivated by these concerns, we develop methods to automatically discover and correct model errors beyond those available in the data. We propose Defuse, a method that generates novel model misclassifications, categorizes these errors into high-level model bugs, and efficiently labels and fine-tunes on the errors to correct them. To generate misclassified data, we propose an algorithm inspired by adversarial machine learning techniques that uses a generative model to find naturally occurring instances misclassified by a model. Further, we observe that the generative models have regions in their latent space with higher concentrations of misclassifications. We call these regions misclassification regions and find they have several useful properties. Each region contains a specific type of model bug; for instance, a misclassification region for an MNIST classifier contains a style of skinny 6 that the model mistakes as a 1. We can also assign a single label to each region, facilitating low-cost labeling. We propose a method to learn the misclassification regions and use this insight to both categorize errors and correct them. In practice, Defuse finds and corrects novel errors in classifiers. For example, Defuse shows that a high-performance traffic sign classifier mistakes certain 50km/h signs as 80km/h. Defuse corrects the error after fine-tuning while maintaining generalization on the test set.
Differentially Private Language Models Benefit from Public Pre-training
Sep 13, 2020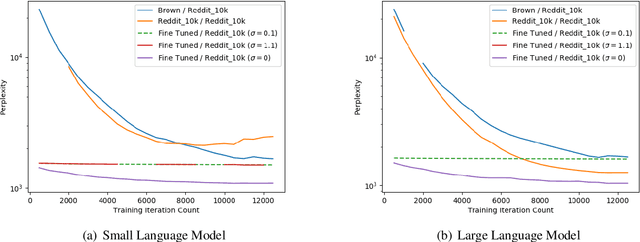
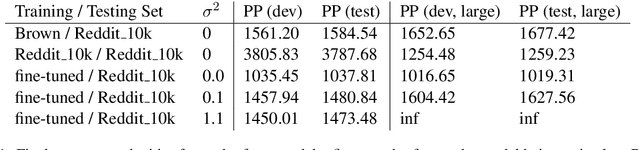
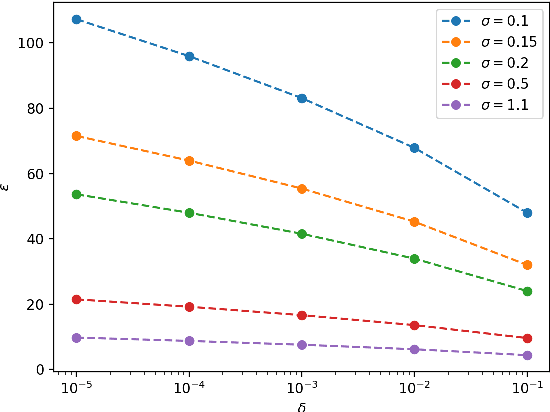
Language modeling is a keystone task in natural language processing. When training a language model on sensitive information, differential privacy (DP) allows us to quantify the degree to which our private data is protected. However, training algorithms which enforce differential privacy often lead to degradation in model quality. We study the feasibility of learning a language model which is simultaneously high-quality and privacy preserving by tuning a public base model on a private corpus. We find that DP fine-tuning boosts the performance of language models in the private domain, making the training of such models possible.
How Much Should I Trust You? Modeling Uncertainty of Black Box Explanations
Aug 11, 2020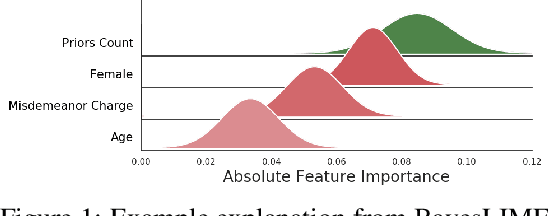

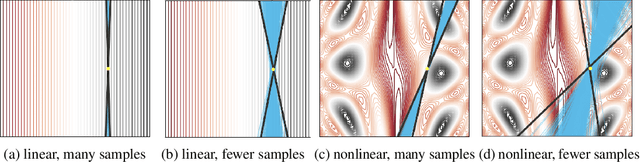

As local explanations of black box models are increasingly being employed to establish model credibility in high stakes settings, it is important to ensure that these explanations are accurate and reliable. However, local explanations generated by existing techniques are often prone to high variance. Further, these techniques are computationally inefficient, require significant hyper-parameter tuning, and provide little insight into the quality of the resulting explanations. By identifying lack of uncertainty modeling as the main cause of these challenges, we propose a novel Bayesian framework that produces explanations that go beyond point-wise estimates of feature importance. We instantiate this framework to generate Bayesian versions of LIME and KernelSHAP. In particular, we estimate credible intervals (CIs) that capture the uncertainty associated with each feature importance in local explanations. These credible intervals are tight when we have high confidence in the feature importances of a local explanation. The CIs are also informative both for estimating how many perturbations we need to sample -- sampling can proceed until the CIs are sufficiently narrow -- and where to sample -- sampling in regions with high predictive uncertainty leads to faster convergence. Experimental evaluation with multiple real world datasets and user studies demonstrate the efficacy of our framework and the resulting explanations.
Fair Meta-Learning: Learning How to Learn Fairly
Nov 06, 2019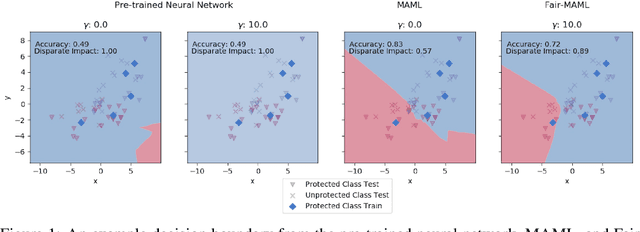
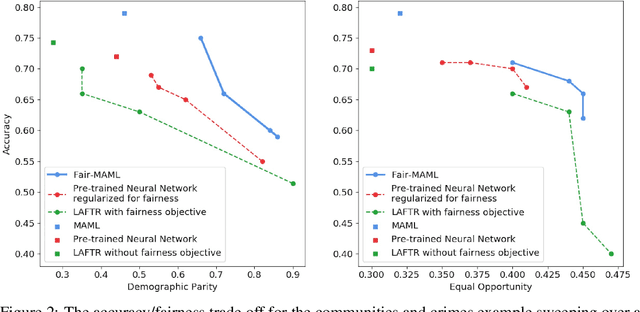
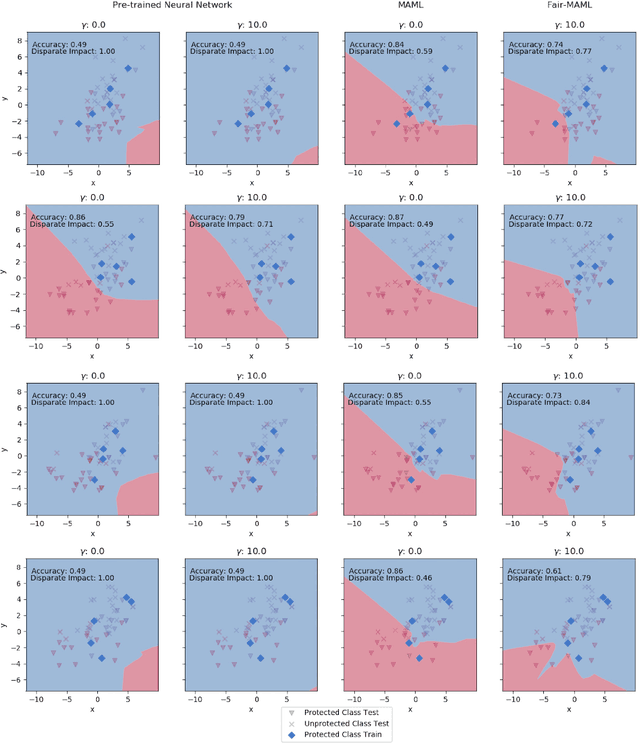
Data sets for fairness relevant tasks can lack examples or be biased according to a specific label in a sensitive attribute. We demonstrate the usefulness of weight based meta-learning approaches in such situations. For models that can be trained through gradient descent, we demonstrate that there are some parameter configurations that allow models to be optimized from a few number of gradient steps and with minimal data which are both fair and accurate. To learn such weight sets, we adapt the popular MAML algorithm to Fair-MAML by the inclusion of a fairness regularization term. In practice, Fair-MAML allows practitioners to train fair machine learning models from only a few examples when data from related tasks is available. We empirically exhibit the value of this technique by comparing to relevant baselines.
How can we fool LIME and SHAP? Adversarial Attacks on Post hoc Explanation Methods
Nov 06, 2019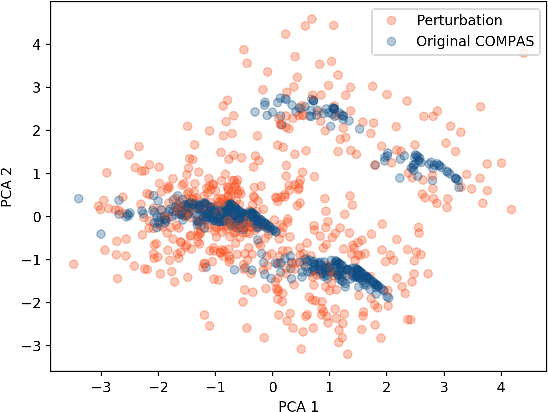

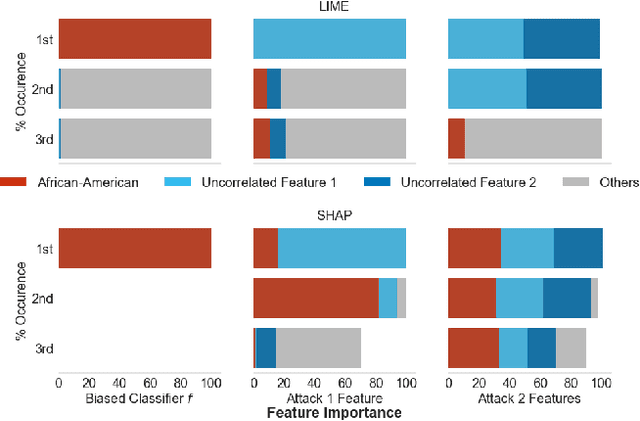

As machine learning black boxes are increasingly being deployed in domains such as healthcare and criminal justice, there is growing emphasis on building tools and techniques for explaining these black boxes in an interpretable manner. Such explanations are being leveraged by domain experts to diagnose systematic errors and underlying biases of black boxes. In this paper, we demonstrate that post hoc explanations techniques that rely on input perturbations, such as LIME and SHAP, are not reliable. Specifically, we propose a novel scaffolding technique that effectively hides the biases of any given classifier by allowing an adversarial entity to craft an arbitrary desired explanation. Our approach can be used to scaffold any biased classifier in such a way that its predictions on the input data distribution still remain biased, but the post hoc explanations of the scaffolded classifier look innocuous. Using extensive evaluation with multiple real-world datasets (including COMPAS), we demonstrate how extremely biased (racist) classifiers crafted by our framework can easily fool popular explanation techniques such as LIME and SHAP into generating innocuous explanations which do not reflect the underlying biases.
Fairness Warnings and Fair-MAML: Learning Fairly with Minimal Data
Aug 24, 2019
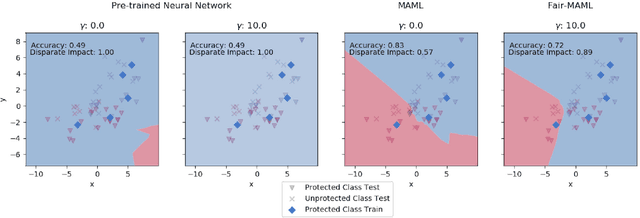
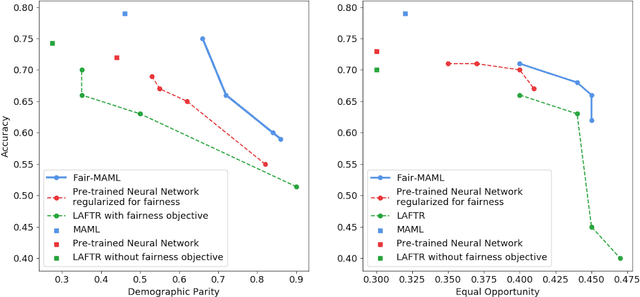

In this paper, we advocate for the study of fairness techniques in low data situations. We propose two algorithms Fairness Warnings and Fair-MAML. The first is a model-agnostic algorithm that provides interpretable boundary conditions for when a fairly trained model may not behave fairly on similar but slightly different tasks within a given domain. The second is a fair meta-learning approach to train models that can be trained through gradient descent with the objective of "learning how to learn fairly". This method encodes more general notions of fairness and accuracy into the model so that it can learn new tasks within a domain both quickly and fairly from only a few training points. We demonstrate experimentally the individual utility of each model using relevant baselines for comparison and provide the first experiment to our knowledge of K-shot fairness, i.e. training a fair model on a new task with only K data points. Then, we illustrate the usefulness of both algorithms as a combined method for training models from a few data points on new tasks while using Fairness Warnings as interpretable boundary conditions under which the newly trained model may not be fair.
Assessing the Local Interpretability of Machine Learning Models
Feb 09, 2019
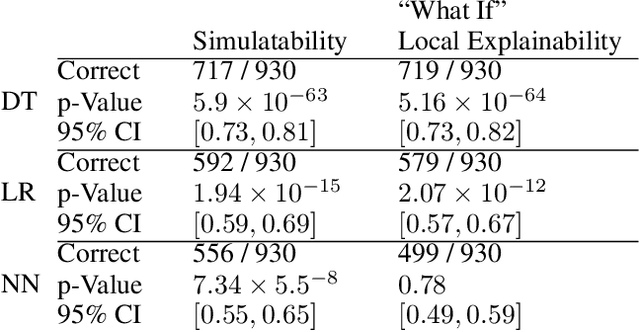


The increasing adoption of machine learning tools has led to calls for accountability via model interpretability. But what does it mean for a machine learning model to be interpretable by humans, and how can this be assessed? We focus on two definitions of interpretability that have been introduced in the machine learning literature: simulatability (a user's ability to run a model on a given input) and "what if" local explainability (a user's ability to correctly indicate the outcome to a model under local changes to the input). Through a user study with 1000 participants, we test whether humans perform well on tasks that mimic the definitions of simulatability and "what if" local explainability on models that are typically considered locally interpretable. We find evidence consistent with the common intuition that decision trees and logistic regression models are interpretable and are more interpretable than neural networks. We propose a metric - the runtime operation count on the simulatability task - to indicate the relative interpretability of models and show that as the number of operations increases the users' accuracy on the local interpretability tasks decreases.