 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Turkish Subword Strategies at Scale: Systematic Evaluation of Data, Vocabulary, Morphology Interplay
Feb 06, 2026Tokenization is a pivotal design choice for neural language modeling in morphologically rich languages (MRLs) such as Turkish, where productive agglutination challenges both vocabulary efficiency and morphological fidelity. Prior studies have explored tokenizer families and vocabulary sizes but typically (i) vary vocabulary without systematically controlling the tokenizer's training corpus, (ii) provide limited intrinsic diagnostics, and (iii) evaluate a narrow slice of downstream tasks. We present the first comprehensive, principled study of Turkish subword tokenization; a "subwords manifest", that jointly varies vocabulary size and tokenizer training corpus size (data and vocabulary coupling), compares multiple tokenizer families under matched parameter budgets (WordPiece, morphology level, and character baselines), and evaluates across semantic (NLI, STS, sentiment analysis, NER), syntactic (POS, dependency parsing), and morphology-sensitive probes. To explain why tokenizers succeed or fail, we introduce a morphology-aware diagnostic toolkit that goes beyond coarse aggregates to boundary-level micro/macro F1, decoupled lemma atomicity vs. surface boundary hits, over/under-segmentation indices, character/word edit distances (CER/WER), continuation rates, and affix-type coverage and token-level atomicity. Our contributions are fourfold: (i) a systematic investigation of the vocabulary-corpus-success triad; (ii) a unified, morphology-aware evaluation framework linking intrinsic diagnostics to extrinsic outcomes; (iii) controlled comparisons identifying when character-level and morphology-level tokenization pay off; and (iv) an open-source release of evaluation code, tokenizer pipelines, and models. As the first work of its kind, this "subwords manifest" delivers actionable guidance for building effective tokenizers in MRLs and establishes a reproducible foundation for future research.
Introducing TrGLUE and SentiTurca: A Comprehensive Benchmark for Turkish General Language Understanding and Sentiment Analysis
Dec 26, 2025Evaluating the performance of various model architectures, such as transformers, large language models (LLMs), and other NLP systems, requires comprehensive benchmarks that measure performance across multiple dimensions. Among these, the evaluation of natural language understanding (NLU) is particularly critical as it serves as a fundamental criterion for assessing model capabilities. Thus, it is essential to establish benchmarks that enable thorough evaluation and analysis of NLU abilities from diverse perspectives. While the GLUE benchmark has set a standard for evaluating English NLU, similar benchmarks have been developed for other languages, such as CLUE for Chinese, FLUE for French, and JGLUE for Japanese. However, no comparable benchmark currently exists for the Turkish language. To address this gap, we introduce TrGLUE, a comprehensive benchmark encompassing a variety of NLU tasks for Turkish. In addition, we present SentiTurca, a specialized benchmark for sentiment analysis. To support researchers, we also provide fine-tuning and evaluation code for transformer-based models, facilitating the effective use of these benchmarks. TrGLUE comprises Turkish-native corpora curated to mirror the domains and task formulations of GLUE-style evaluations, with labels obtained through a semi-automated pipeline that combines strong LLM-based annotation, cross-model agreement checks, and subsequent human validation. This design prioritizes linguistic naturalness, minimizes direct translation artifacts, and yields a scalable, reproducible workflow. With TrGLUE, our goal is to establish a robust evaluation framework for Turkish NLU, empower researchers with valuable resources, and provide insights into generating high-quality semi-automated datasets.
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
May 07, 2024Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
An Ontology-Based Dialogue Management System for Banking and Finance Dialogue Systems
Apr 13, 2018

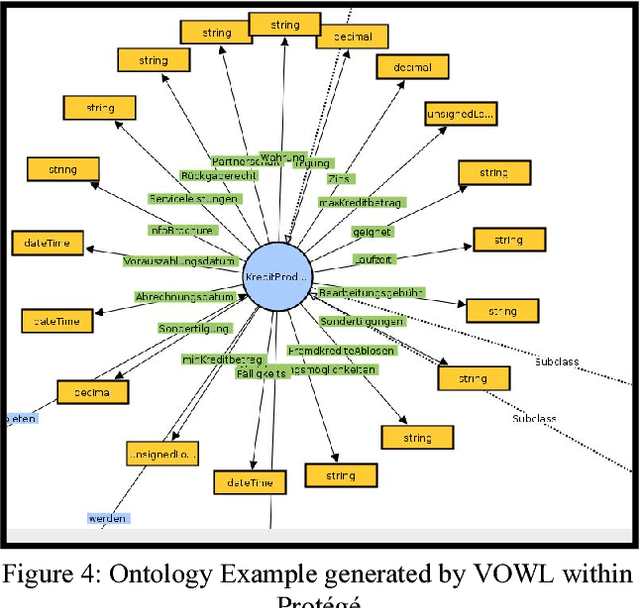
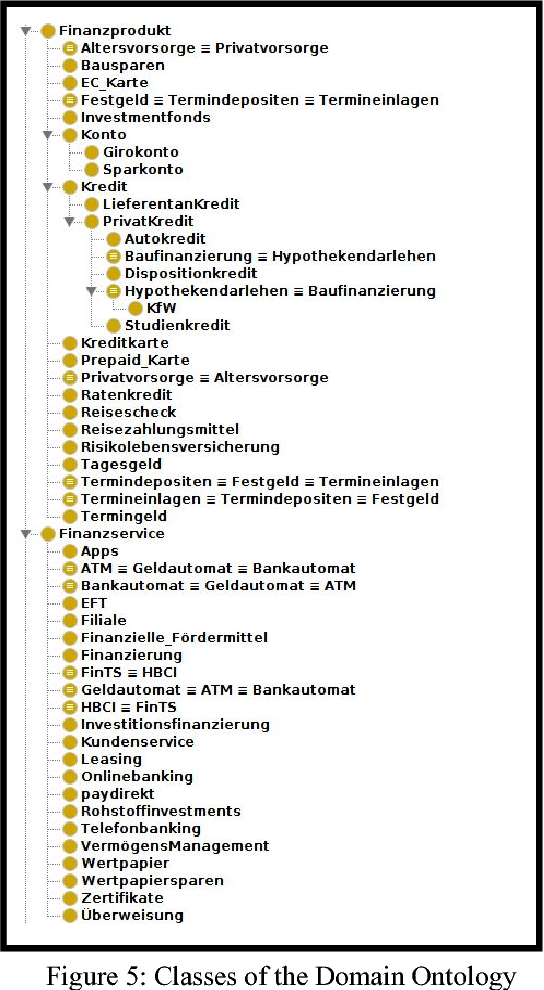
Keeping the dialogue state in dialogue systems is a notoriously difficult task. We introduce an ontology-based dialogue manage(OntoDM), a dialogue manager that keeps the state of the conversation, provides a basis for anaphora resolution and drives the conversation via domain ontologies. The banking and finance area promises great potential for disambiguating the context via a rich set of products and specificity of proper nouns, named entities and verbs. We used ontologies both as a knowledge base and a basis for the dialogue manager; the knowledge base component and dialogue manager components coalesce in a sense. Domain knowledge is used to track Entities of Interest, i.e. nodes (classes) of the ontology which happen to be products and services. In this way we also introduced conversation memory and attention in a sense. We finely blended linguistic methods, domain-driven keyword ranking and domain ontologies to create ways of domain-driven conversation. Proposed framework is used in our in-house German language banking and finance chatbots. General challenges of German language processing and finance-banking domain chatbot language models and lexicons are also introduced. This work is still in progress, hence no success metrics have been introduced yet.
DEMorphy, German Language Morphological Analyzer
Mar 02, 2018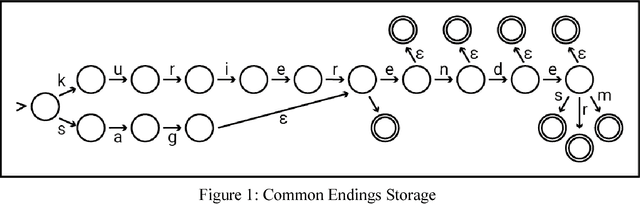
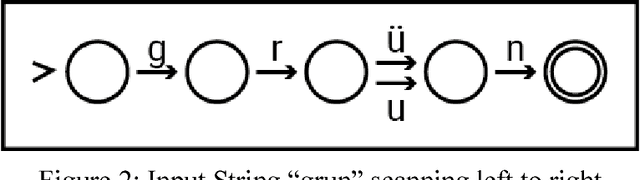
DEMorphy is a morphological analyzer for German. It is built onto large, compactified lexicons from German Morphological Dictionary. A guesser based on German declension suffixed is also provided. For German, we provided a state-of-art morphological analyzer. DEMorphy is implemented in Python with ease of usability and accompanying documentation. The package is suitable for both academic and commercial purposes wit a permissive licence.
Towards Turkish ASR: Anatomy of a rule-based Turkish g2p
Jan 15, 2016This paper describes the architecture and implementation of a rule-based grapheme to phoneme converter for Turkish. The system accepts surface form as input, outputs SAMPA mapping of the all parallel pronounciations according to the morphological analysis together with stress positions. The system has been implemented in Python