 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Deep Learning for Predicting Twitter Users' Location
Dec 21, 2017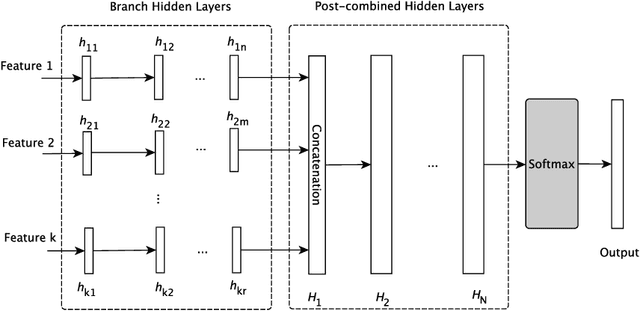

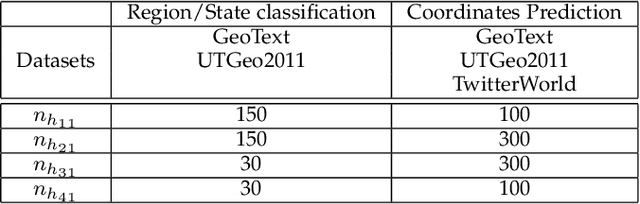
The problem of predicting the location of users on large social networks like Twitter has emerged from real-life applications such as social unrest detection and online marketing. Twitter user geolocation is a difficult and active research topic with a vast literature. Most of the proposed methods follow either a content-based or a network-based approach. The former exploits user-generated content while the latter utilizes the connection or interaction between Twitter users. In this paper, we introduce a novel method combining the strength of both approaches. Concretely, we propose a multi-entry neural network architecture named MENET leveraging the advances in deep learning and multiview learning. The generalizability of MENET enables the integration of multiple data representations. In the context of Twitter user geolocation, we realize MENET with textual, network, and metadata features. Considering the natural distribution of Twitter users across the concerned geographical area, we subdivide the surface of the earth into multi-scale cells and train MENET with the labels of the cells. We show that our method outperforms the state of the art by a large margin on three benchmark datasets.
Deep Learning Sparse Ternary Projections for Compressed Sensing of Images
Aug 28, 2017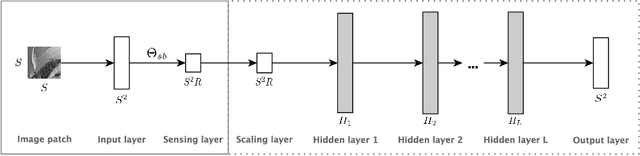
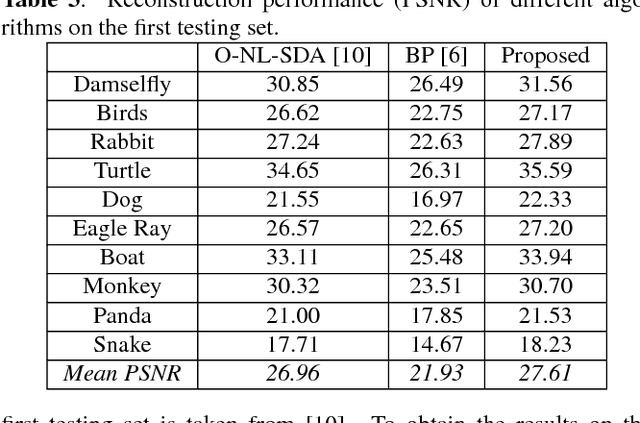
Compressed sensing (CS) is a sampling theory that allows reconstruction of sparse (or compressible) signals from an incomplete number of measurements, using of a sensing mechanism implemented by an appropriate projection matrix. The CS theory is based on random Gaussian projection matrices, which satisfy recovery guarantees with high probability; however, sparse ternary {0, -1, +1} projections are more suitable for hardware implementation. In this paper, we present a deep learning approach to obtain very sparse ternary projections for compressed sensing. Our deep learning architecture jointly learns a pair of a projection matrix and a reconstruction operator in an end-to-end fashion. The experimental results on real images demonstrate the effectiveness of the proposed approach compared to state-of-the-art methods, with significant advantage in terms of complexity.