 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSInsight: A local-global attribution framework for interpretability in time-series data
Apr 06, 2020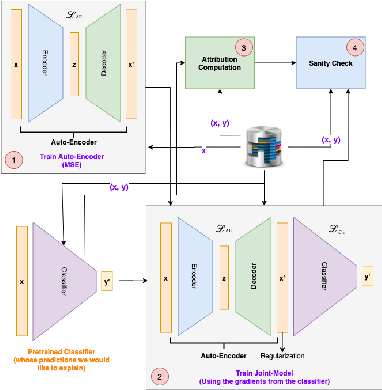
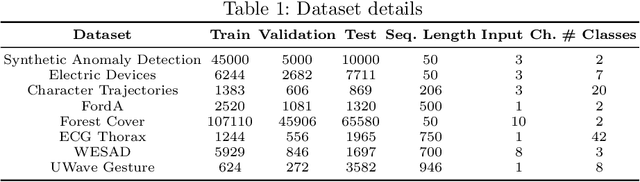
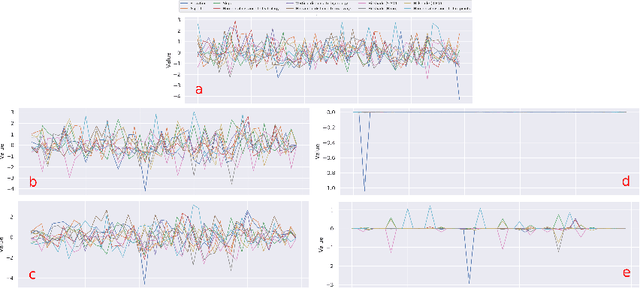
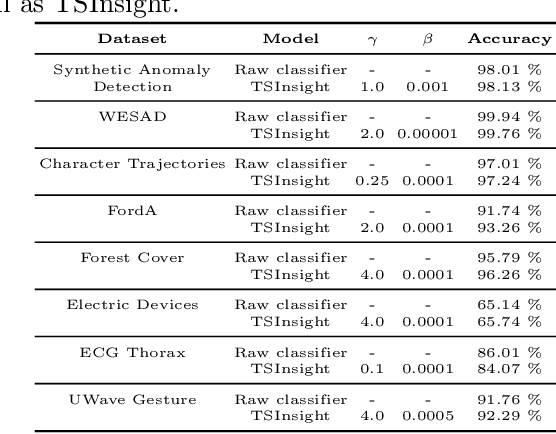
With the rise in the employment of deep learning methods in safety-critical scenarios, interpretability is more essential than ever before. Although many different directions regarding interpretability have been explored for visual modalities, time-series data has been neglected with only a handful of methods tested due to their poor intelligibility. We approach the problem of interpretability in a novel way by proposing TSInsight where we attach an auto-encoder to the classifier with a sparsity-inducing norm on its output and fine-tune it based on the gradients from the classifier and a reconstruction penalty. TSInsight learns to preserve features that are important for prediction by the classifier and suppresses those that are irrelevant i.e. serves as a feature attribution method to boost interpretability. In contrast to most other attribution frameworks, TSInsight is capable of generating both instance-based and model-based explanations. We evaluated TSInsight along with 9 other commonly used attribution methods on 8 different time-series datasets to validate its efficacy. Evaluation results show that TSInsight naturally achieves output space contraction, therefore, is an effective tool for the interpretability of deep time-series models.
SentiCite: An Approach for Publication Sentiment Analysis
Oct 07, 2019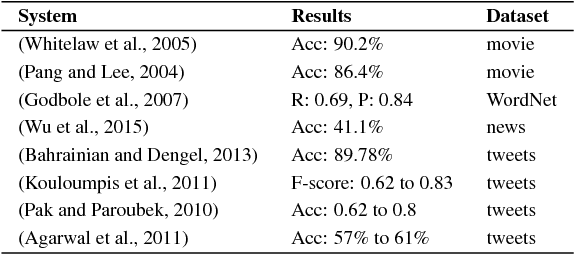
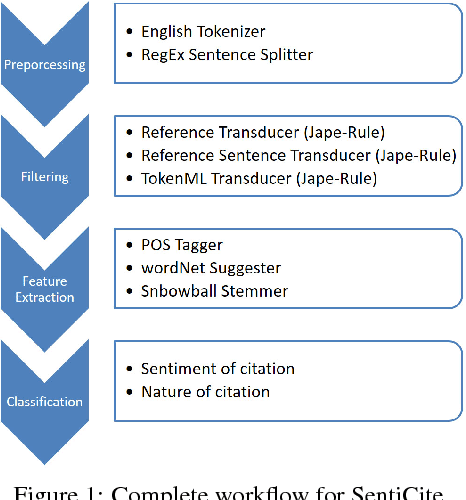
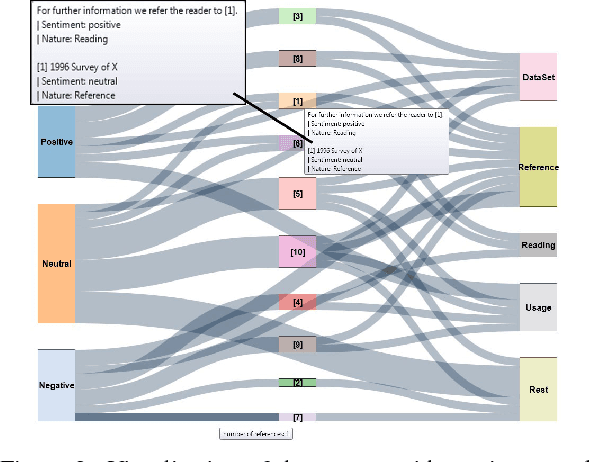

With the rapid growth in the number of scientific publications, year after year, it is becoming increasingly difficult to identify quality authoritative work on a single topic. Though there is an availability of scientometric measures which promise to offer a solution to this problem, these measures are mostly quantitative and rely, for instance, only on the number of times an article is cited. With this approach, it becomes irrelevant if an article is cited 10 times in a positive, negative or neutral way. In this context, it is quite important to study the qualitative aspect of a citation to understand its significance. This paper presents a novel system for sentiment analysis of citations in scientific documents (SentiCite) and is also capable of detecting nature of citations by targeting the motivation behind a citation, e.g., reference to a dataset, reading reference. Furthermore, the paper also presents two datasets (SentiCiteDB and IntentCiteDB) containing about 2,600 citations with their ground truth for sentiment and nature of citation. SentiCite along with other state-of-the-art methods for sentiment analysis are evaluated on the presented datasets. Evaluation results reveal that SentiCite outperforms state-of-the-art methods for sentiment analysis in scientific publications by achieving a F1-measure of 0.71.
TSXplain: Demystification of DNN Decisions for Time-Series using Natural Language and Statistical Features
May 15, 2019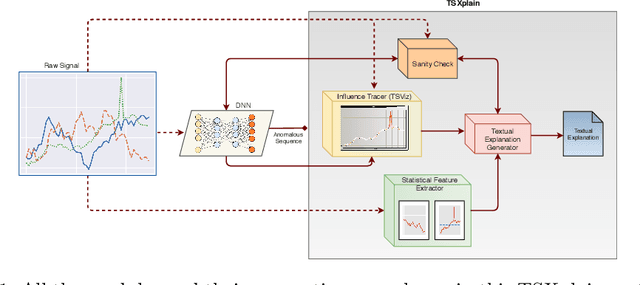


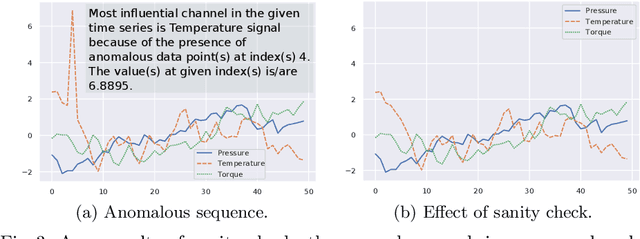
Neural networks (NN) are considered as black-boxes due to the lack of explainability and transparency of their decisions. This significantly hampers their deployment in environments where explainability is essential along with the accuracy of the system. Recently, significant efforts have been made for the interpretability of these deep networks with the aim to open up the black-box. However, most of these approaches are specifically developed for visual modalities. In addition, the interpretations provided by these systems require expert knowledge and understanding for intelligibility. This indicates a vital gap between the explainability provided by the systems and the novice user. To bridge this gap, we present a novel framework i.e. Time-Series eXplanation (TSXplain) system which produces a natural language based explanation of the decision taken by a NN. It uses the extracted statistical features to describe the decision of a NN, merging the deep learning world with that of statistics. The two-level explanation provides ample description of the decision made by the network to aid an expert as well as a novice user alike. Our survey and reliability assessment test confirm that the generated explanations are meaningful and correct. We believe that generating natural language based descriptions of the network's decisions is a big step towards opening up the black-box.