 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitial Decoding with Minimally Augmented Language Model for Improved Lattice Rescoring in Low Resource ASR
Mar 16, 2024This paper addresses the problem of improving speech recognition accuracy with lattice rescoring in low-resource languages where the baseline language model is insufficient for generating inclusive lattices. We minimally augment the baseline language model with word unigram counts that are present in a larger text corpus of the target language but absent in the baseline. The lattices generated after decoding with such an augmented baseline language model are more comprehensive. We obtain 21.8% (Telugu) and 41.8% (Kannada) relative word error reduction with our proposed method. This reduction in word error rate is comparable to 21.5% (Telugu) and 45.9% (Kannada) relative word error reduction obtained by decoding with full Wikipedia text augmented language mode while our approach consumes only 1/8th the memory. We demonstrate that our method is comparable with various text selection-based language model augmentation and also consistent for data sets of different sizes. Our approach is applicable for training speech recognition systems under low resource conditions where speech data and compute resources are insufficient, while there is a large text corpus that is available in the target language. Our research involves addressing the issue of out-of-vocabulary words of the baseline in general and does not focus on resolving the absence of named entities. Our proposed method is simple and yet computationally less expensive.
A Hierarchical Approach to Conditional Random Fields for System Anomaly Detection
Oct 28, 2022Anomaly detection to recognize unusual events in large scale systems in a time sensitive manner is critical in many industries, eg. bank fraud, enterprise systems, medical alerts, etc. Large-scale systems often grow in size and complexity over time, and anomaly detection algorithms need to adapt to changing structures. A hierarchical approach takes advantage of the implicit relationships in complex systems and localized context. The features in complex systems may vary drastically in data distribution, capturing different aspects from multiple data sources, and when put together provide a more complete view of the system. In this paper, two datasets are considered, the 1st comprising of system metrics from machines running on a cloud service, and the 2nd of application metrics from a large-scale distributed software system with inherent hierarchies and interconnections amongst its system nodes. Comparing algorithms, across the changepoint based PELT algorithm, cognitive learning-based Hierarchical Temporal Memory algorithms, Support Vector Machines and Conditional Random Fields provides a basis for proposing a Hierarchical Global-Local Conditional Random Field approach to accurately capture anomalies in complex systems across various features. Hierarchical algorithms can learn both the intricacies of specific features, and utilize these in a global abstracted representation to detect anomalous patterns robustly across multi-source feature data and distributed systems. A graphical network analysis on complex systems can further fine-tune datasets to mine relationships based on available features, which can benefit hierarchical models. Furthermore, hierarchical solutions can adapt well to changes at a localized level, learning on new data and changing environments when parts of a system are over-hauled, and translate these learnings to a global view of the system over time.
Combining Heterogeneous Classifiers for Relational Databases
Mar 12, 2012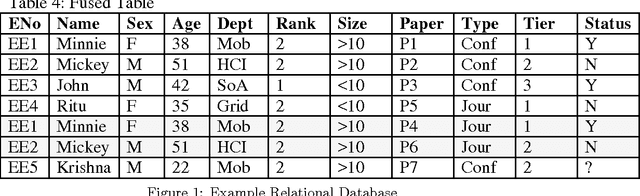
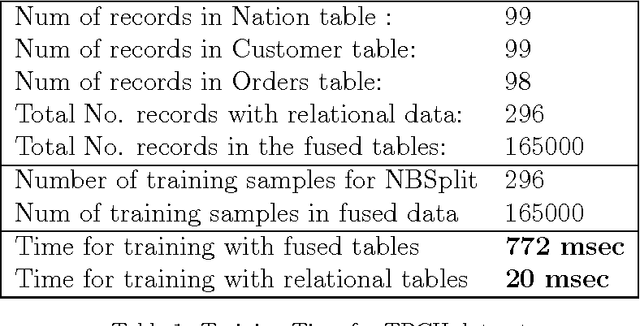
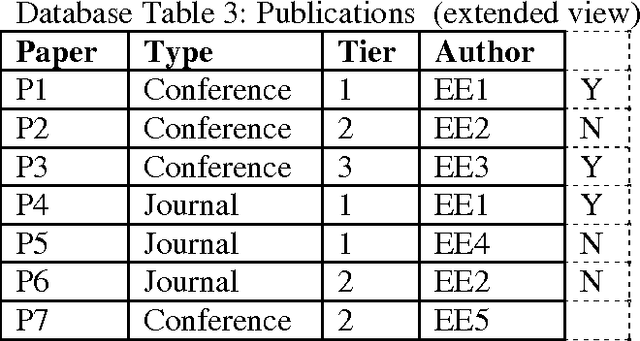

Most enterprise data is distributed in multiple relational databases with expert-designed schema. Using traditional single-table machine learning techniques over such data not only incur a computational penalty for converting to a 'flat' form (mega-join), even the human-specified semantic information present in the relations is lost. In this paper, we present a practical, two-phase hierarchical meta-classification algorithm for relational databases with a semantic divide and conquer approach. We propose a recursive, prediction aggregation technique over heterogeneous classifiers applied on individual database tables. The proposed algorithm was evaluated on three diverse datasets, namely TPCH, PKDD and UCI benchmarks and showed considerable reduction in classification time without any loss of prediction accuracy.