 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cognition-Emotion-Personality Framework for Modeling Human-Like Awareness and Behavior in Emergency Evacuations
Jun 28, 2026Agent-based evacuation simulations are widely used to study crowd behavior during emergencies, but many models rely on assumptions such as perfect event awareness, complete exit knowledge, and fully rational decision-making. This paper presents an extended evacuation framework that integrates cognitive, emotional, social, and personality-related mechanisms into a unified model of human behavior under uncertainty. The framework incorporates a dynamic event-awareness mechanism based on a continuous Event Certainty Level, a memory-based representation of exit knowledge subject to acquisition, forgetting, and recall, a continuous fear model in which panic emerges as a high-intensity state, and an OCEAN-based personality representation. Neuroticism is explicitly integrated into the emotional model, influencing fear generation, escalation, social contagion, and recovery. Behavioral heterogeneity is further captured through individualized decision thresholds that affect responses to perceived risk. The framework is evaluated through simulation experiments examining the effects of spatial familiarity, memory robustness, decision sensitivity, emotional dynamics, and personality variation. Results show that cognitive, emotional, and personality-driven processes substantially influence evacuation dynamics, reducing evacuation efficiency and generating realistic crowd phenomena such as delays, confusion, injuries, and socially influenced behaviors. The proposed framework provides a more realistic representation of human behavior in emergency evacuations and supports systematic investigation of the interactions between cognition, emotion, personality, and crowd dynamics.
Managing Uncertainty in LLM-Generated Procedural Knowledge for Virtual Laboratory Planning
May 25, 2026Educational virtual laboratories can make experimental training more scala-ble, adaptive, and accessible, especially when students have limited access to physical laboratory facilities. However, authoring new simulated laboratory procedures remains costly: educators must describe new equipment, define how instruments and materials interact, and specify valid procedural flows that can be executed or assessed inside the virtual environment. Large lan-guage models can assist in this authoring process by generating detailed ex-perimental procedures, but their output should not be treated as directly exe-cutable plans. They may omit necessary actions, arrange steps in the wrong order, or produce instructions that are logically incorrect or incompatible with the laboratory equipment. This paper presents a prototype framework for managing uncertainty in LLM-generated procedural knowledge for virtu-al laboratory planning. The framework aims to reduce procedural uncertainty by using structured domain representations and uncertain LLM-generated state-transition samples to extract candidate procedural rules, transform them into explicit and inspectable constraints, and use them to repair uncertain procedural steps. Although the motivating domain refers to educational vir-tual laboratories, the underlying problem is more general: managing uncer-tain procedural knowledge for action planning in structured interactive envi-ronments. We illustrate the approach in a virtual laboratory domain involving laboratory instruments, containers, tools, and material-transfer actions.
Artificial Intelligence and Cost Reduction in Public Higher Education: A Scoping Review of Emerging Evidence
Apr 06, 2026Public higher education systems face increasing financial pressures from expanding student populations, rising operational costs, and persistent demands for equitable access. Artificial Intelligence (AI), including generative tools such as ChatGPT, learning analytics, intelligent tutoring systems, and predictive models, has been proposed as a means of enhancing efficiency and reducing costs. This study conducts a scoping review of the literature on AI applications in public higher education, based on systematic searches in Scopus and IEEE Xplore that identified 241 records, of which 21 empirical studies met predefined eligibility criteria and were thematically analyzed. The findings show that AI enables cost savings by automating administrative tasks, optimizing resource allocation, supporting personalized learning at scale, and applying predictive analytics to improve student retention and institutional planning. At the same time, concerns emerge regarding implementation costs, unequal access across institutions, and risks of widening digital divides. Overall, the thematic analysis highlights both the promises and limitations of AI-driven cost reduction in higher education, offering insights for policymakers, university administrators, and educators on the economic implications of AI adoption, while also pointing to gaps that warrant further empirical research.
Governance by Evidence: Regulated Predictors in Decision-Tree Models
Dec 17, 2025Decision-tree methods are widely used on structured tabular data and are valued for interpretability across many sectors. However, published studies often list the predictors they use (for example age, diagnosis codes, location). Privacy laws increasingly regulate such data types. We use published decision-tree papers as a proxy for real-world use of legally governed data. We compile a corpus of decision-tree studies and assign each reported predictor to a regulated data category (for example health data, biometric identifiers, children's data, financial attributes, location traces, and government IDs). We then link each category to specific excerpts in European Union and United States privacy laws. We find that many reported predictors fall into regulated categories, with the largest shares in healthcare and clear differences across industries. We analyze prevalence, industry composition, and temporal patterns, and summarize regulation-aligned timing using each framework's reference year. Our evidence supports privacy-preserving methods and governance checks, and can inform ML practice beyond decision trees.
A biologically Inspired Trust Model for Open Multi-Agent Systems that is Resilient to Rapid Performance Fluctuations
Apr 17, 2025Trust management provides an alternative solution for securing open, dynamic, and distributed multi-agent systems, where conventional cryptographic methods prove to be impractical. However, existing trust models face challenges related to agent mobility, changing behaviors, and the cold start problem. To address these issues we introduced a biologically inspired trust model in which trustees assess their own capabilities and store trust data locally. This design improves mobility support, reduces communication overhead, resists disinformation, and preserves privacy. Despite these advantages, prior evaluations revealed limitations of our model in adapting to provider population changes and continuous performance fluctuations. This study proposes a novel algorithm, incorporating a self-classification mechanism for providers to detect performance drops potentially harmful for the service consumers. Simulation results demonstrate that the new algorithm outperforms its original version and FIRE, a well-known trust and reputation model, particularly in handling dynamic trustee behavior. While FIRE remains competitive under extreme environmental changes, the proposed algorithm demonstrates greater adaptability across various conditions. In contrast to existing trust modeling research, this study conducts a comprehensive evaluation of our model using widely recognized trust model criteria, assessing its resilience against common trust-related attacks while identifying strengths, weaknesses, and potential countermeasures. Finally, several key directions for future research are proposed.
Off-the-Shelf Neural Network Architectures for Forex Time Series Prediction come at a Cost
May 17, 2024Our study focuses on comparing the performance and resource requirements between different Long Short-Term Memory (LSTM) neural network architectures and an ANN specialized architecture for forex market prediction. We analyze the execution time of the models as well as the resources consumed, such as memory and computational power. Our aim is to demonstrate that the specialized architecture not only achieves better results in forex market prediction but also executes using fewer resources and in a shorter time frame compared to LSTM architectures. This comparative analysis will provide significant insights into the suitability of these two types of architectures for time series prediction in the forex market environment.
Comparative analysis of neural network architectures for short-term FOREX forecasting
May 13, 2024The present document delineates the analysis, design, implementation, and benchmarking of various neural network architectures within a short-term frequency prediction system for the foreign exchange market (FOREX). Our aim is to simulate the judgment of the human expert (technical analyst) using a system that responds promptly to changes in market conditions, thus enabling the optimization of short-term trading strategies. We designed and implemented a series of LSTM neural network architectures which are taken as input the exchange rate values and generate the short-term market trend forecasting signal and an ANN custom architecture based on technical analysis indicator simulators We performed a comparative analysis of the results and came to useful conclusions regarding the suitability of each architecture and the cost in terms of time and computational power to implement them. The ANN custom architecture produces better prediction quality with higher sensitivity using fewer resources and spending less time than LSTM architectures. The ANN custom architecture appears to be ideal for use in low-power computing systems and for use cases that need fast decisions with the least possible computational cost.
Using Deep Q-Learning to Dynamically Toggle between Push/Pull Actions in Computational Trust Mechanisms
Apr 28, 2024



Recent work on decentralized computational trust models for open Multi Agent Systems has resulted in the development of CA, a biologically inspired model which focuses on the trustee's perspective. This new model addresses a serious unresolved problem in existing trust and reputation models, namely the inability to handle constantly changing behaviors and agents' continuous entry and exit from the system. In previous work, we compared CA to FIRE, a well-known trust and reputation model, and found that CA is superior when the trustor population changes, whereas FIRE is more resilient to the trustee population changes. Thus, in this paper, we investigate how the trustors can detect the presence of several dynamic factors in their environment and then decide which trust model to employ in order to maximize utility. We frame this problem as a machine learning problem in a partially observable environment, where the presence of several dynamic factors is not known to the trustor and we describe how an adaptable trustor can rely on a few measurable features so as to assess the current state of the environment and then use Deep Q Learning (DQN), in a single-agent Reinforcement Learning setting, to learn how to adapt to a changing environment. We ran a series of simulation experiments to compare the performance of the adaptable trustor with the performance of trustors using only one model (FIRE or CA) and we show that an adaptable agent is indeed capable of learning when to use each model and, thus, perform consistently in dynamic environments.
A biologically inspired computational trust model for open multi-agent systems which is resilient to trustor population changes
Apr 13, 2024



Current trust and reputation models continue to have significant limitations, such as the inability to deal with agents constantly entering or exiting open multi-agent systems (open MAS), as well as continuously changing behaviors. Our study is based on CA, a previously proposed decentralized computational trust model from the trustee's point of view, inspired by synaptic plasticity and the formation of assemblies in the human brain. It is designed to meet the requirements of highly dynamic and open MAS, and its main difference with most conventional trust and reputation models is that the trustor does not select a trustee to delegate a task; instead, the trustee determines whether it is qualified to successfully execute it. We ran a series of simulations to compare CA model to FIRE, a well-established, decentralized trust and reputation model for open MAS under conditions of continuous trustee and trustor population replacement, as well as continuous change of trustees' abilities to perform tasks. The main finding is that FIRE is superior to changes in the trustee population, whereas CA is resilient to the trustor population changes. When the trustees switch performance profiles FIRE clearly outperforms despite the fact that both models' performances are significantly impacted by this environmental change. Findings lead us to conclude that learning to use the appropriate trust model, according to the dynamic conditions in effect could maximize the trustor's benefits.
Using machine learning techniques to predict hospital admission at the emergency department
Jun 28, 2021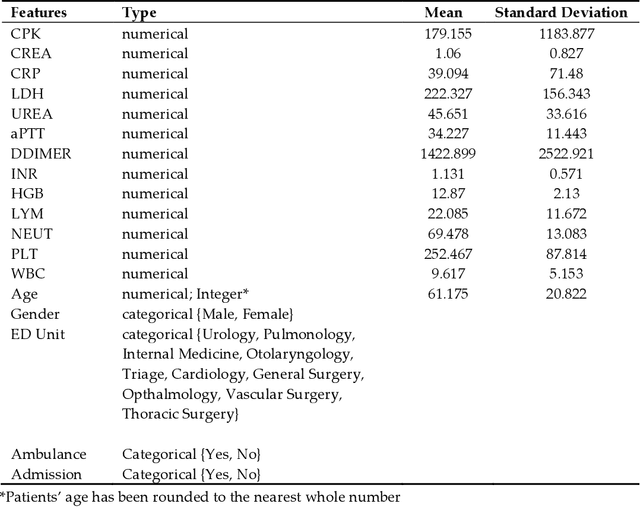
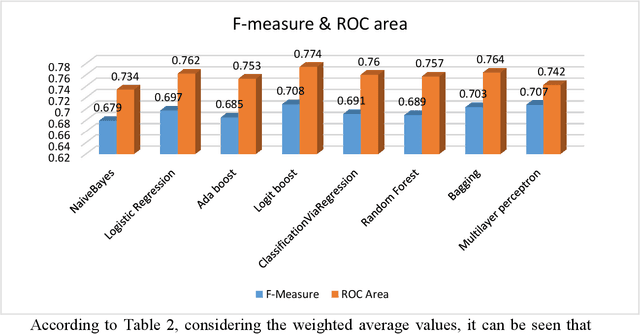
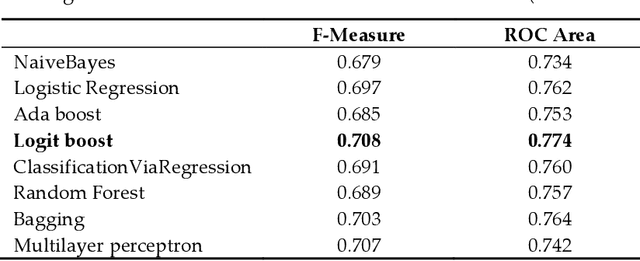
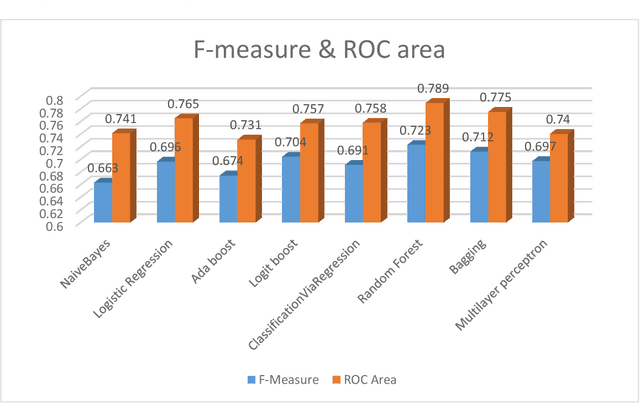
Introduction: One of the most important tasks in the Emergency Department (ED) is to promptly identify the patients who will benefit from hospital admission. Machine Learning (ML) techniques show promise as diagnostic aids in healthcare. Material and methods: We investigated the following features seeking to investigate their performance in predicting hospital admission: serum levels of Urea, Creatinine, Lactate Dehydrogenase, Creatine Kinase, C-Reactive Protein, Complete Blood Count with differential, Activated Partial Thromboplastin Time, D Dimer, International Normalized Ratio, age, gender, triage disposition to ED unit and ambulance utilization. A total of 3,204 ED visits were analyzed. Results: The proposed algorithms generated models which demonstrated acceptable performance in predicting hospital admission of ED patients. The range of F-measure and ROC Area values of all eight evaluated algorithms were [0.679-0.708] and [0.734-0.774], respectively. Discussion: The main advantages of this tool include easy access, availability, yes/no result, and low cost. The clinical implications of our approach might facilitate a shift from traditional clinical decision-making to a more sophisticated model. Conclusion: Developing robust prognostic models with the utilization of common biomarkers is a project that might shape the future of emergency medicine. Our findings warrant confirmation with implementation in pragmatic ED trials.