 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Lexical Ambiguity in Tensor Regression Models of Meaning
Aug 26, 2014
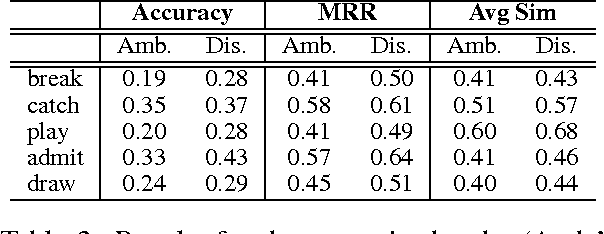
This paper provides a method for improving tensor-based compositional distributional models of meaning by the addition of an explicit disambiguation step prior to composition. In contrast with previous research where this hypothesis has been successfully tested against relatively simple compositional models, in our work we use a robust model trained with linear regression. The results we get in two experiments show the superiority of the prior disambiguation method and suggest that the effectiveness of this approach is model-independent.
Evaluating Neural Word Representations in Tensor-Based Compositional Settings
Aug 26, 2014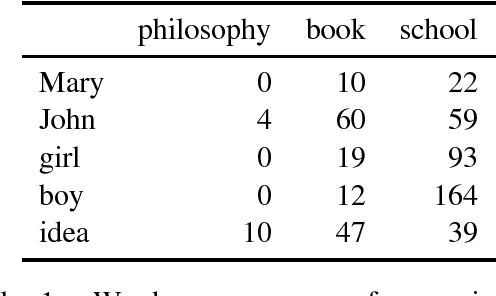

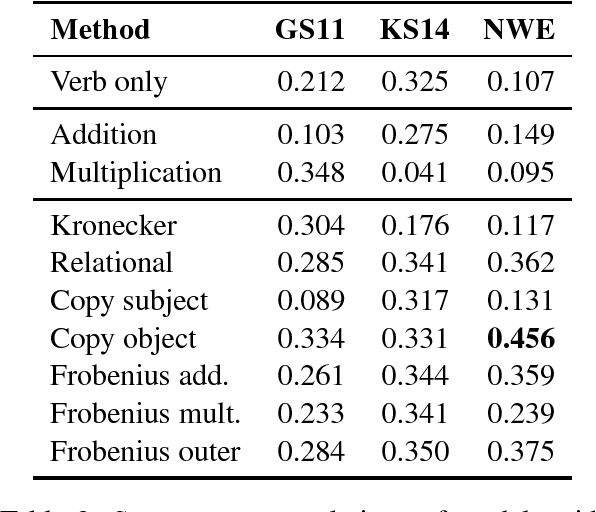
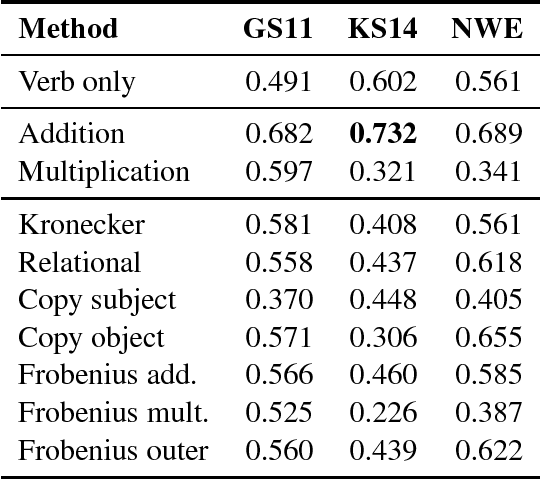
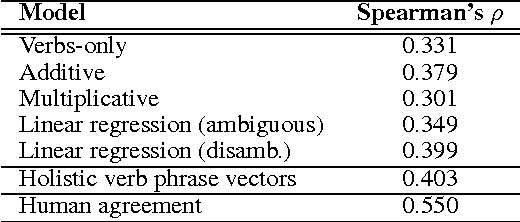
We provide a comparative study between neural word representations and traditional vector spaces based on co-occurrence counts, in a number of compositional tasks. We use three different semantic spaces and implement seven tensor-based compositional models, which we then test (together with simpler additive and multiplicative approaches) in tasks involving verb disambiguation and sentence similarity. To check their scalability, we additionally evaluate the spaces using simple compositional methods on larger-scale tasks with less constrained language: paraphrase detection and dialogue act tagging. In the more constrained tasks, co-occurrence vectors are competitive, although choice of compositional method is important; on the larger-scale tasks, they are outperformed by neural word embeddings, which show robust, stable performance across the tasks.
Reasoning about Meaning in Natural Language with Compact Closed Categories and Frobenius Algebras
Jan 23, 2014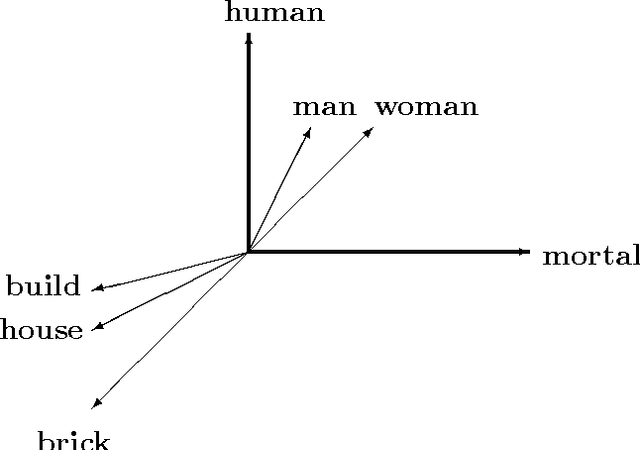

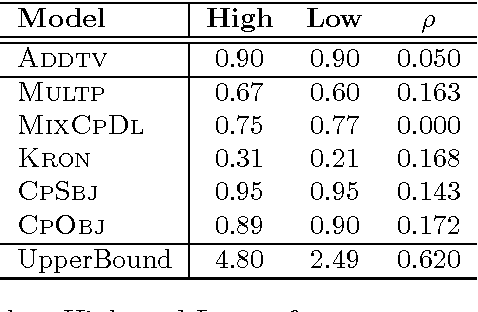
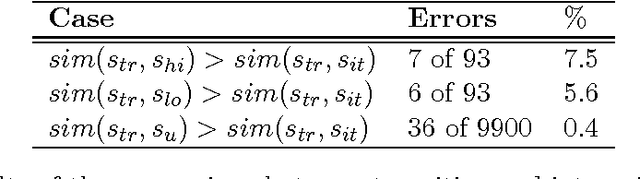
Compact closed categories have found applications in modeling quantum information protocols by Abramsky-Coecke. They also provide semantics for Lambek's pregroup algebras, applied to formalizing the grammatical structure of natural language, and are implicit in a distributional model of word meaning based on vector spaces. Specifically, in previous work Coecke-Clark-Sadrzadeh used the product category of pregroups with vector spaces and provided a distributional model of meaning for sentences. We recast this theory in terms of strongly monoidal functors and advance it via Frobenius algebras over vector spaces. The former are used to formalize topological quantum field theories by Atiyah and Baez-Dolan, and the latter are used to model classical data in quantum protocols by Coecke-Pavlovic-Vicary. The Frobenius algebras enable us to work in a single space in which meanings of words, phrases, and sentences of any structure live. Hence we can compare meanings of different language constructs and enhance the applicability of the theory. We report on experimental results on a number of language tasks and verify the theoretical predictions.
Compositional Operators in Distributional Semantics
Jan 21, 2014

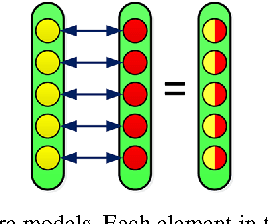
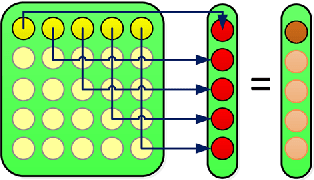
This survey presents in some detail the main advances that have been recently taking place in Computational Linguistics towards the unification of the two prominent semantic paradigms: the compositional formal semantics view and the distributional models of meaning based on vector spaces. After an introduction to these two approaches, I review the most important models that aim to provide compositionality in distributional semantics. Then I proceed and present in more detail a particular framework by Coecke, Sadrzadeh and Clark (2010) based on the abstract mathematical setting of category theory, as a more complete example capable to demonstrate the diversity of techniques and scientific disciplines that this kind of research can draw from. This paper concludes with a discussion about important open issues that need to be addressed by the researchers in the future.