 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Decision Boundaries of Trained Neural Networks
Aug 07, 2019
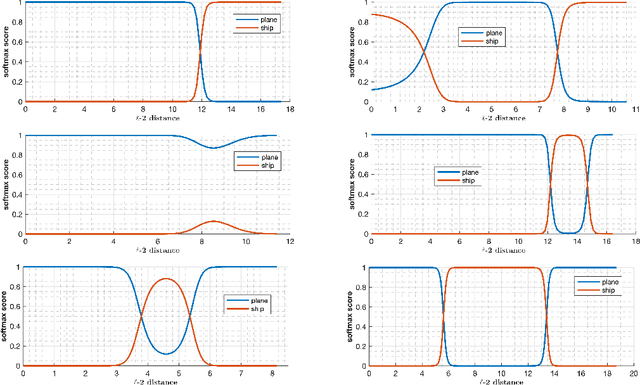
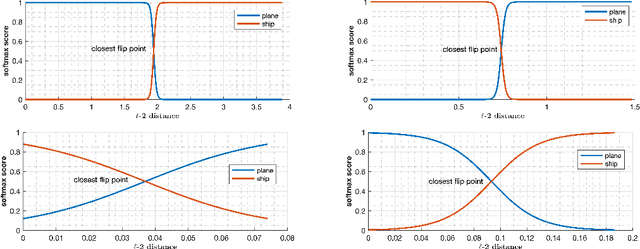
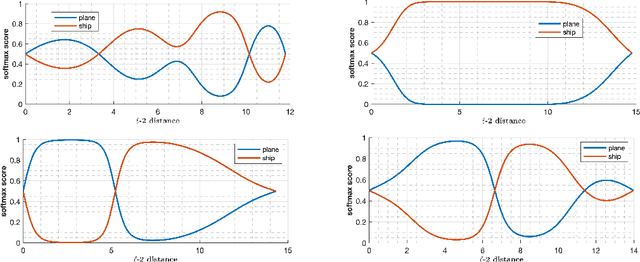
Deep learning models have been the subject of study from various perspectives, for example, their training process, interpretation, generalization error, robustness to adversarial attacks, etc. A trained model is defined by its decision boundaries, and therefore, many of the studies about deep learning models speculate about the decision boundaries, and sometimes make simplifying assumptions about them. So far, finding exact points on the decision boundaries of trained deep models has been considered an intractable problem. Here, we compute exact points on the decision boundaries of these models and provide mathematical tools to investigate the surfaces that define the decision boundaries. Through numerical results, we confirm that some of the speculations about the decision boundaries are accurate, some of the computational methods can be improved, and some of the simplifying assumptions may be unreliable, for models with nonlinear activation functions. We advocate for verification of simplifying assumptions and approximation methods, wherever they are used. Finally, we demonstrate that the computational practices used for finding adversarial examples can be improved and computing the closest point on the decision boundary reveals the weakest vulnerability of a model against adversarial attack.
Refining the Structure of Neural Networks Using Matrix Conditioning
Aug 06, 2019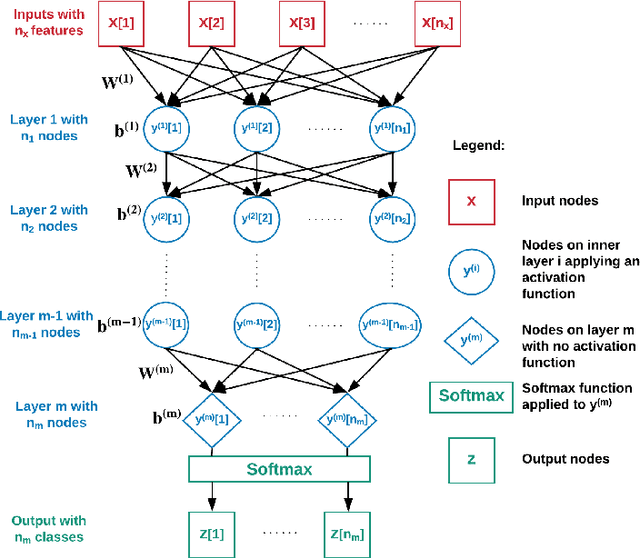
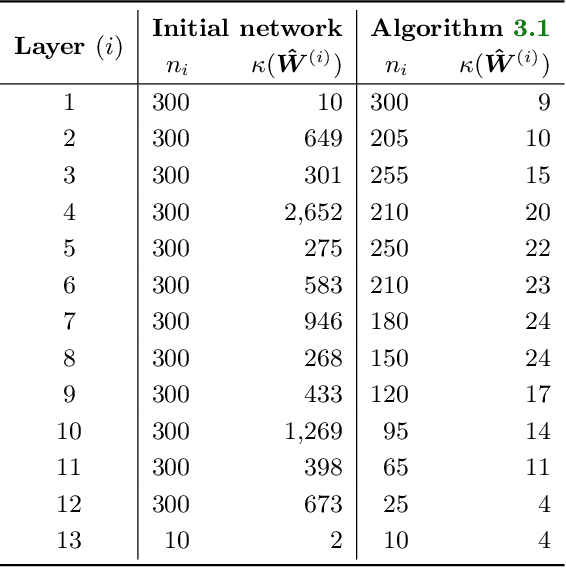
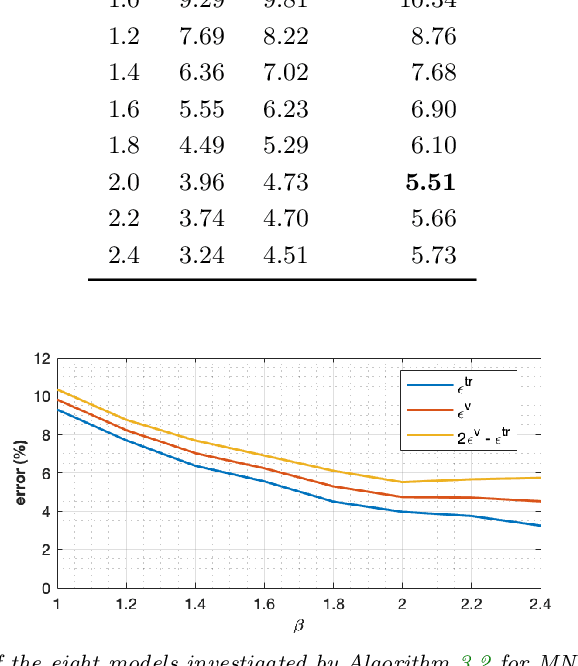

Deep learning models have proven to be exceptionally useful in performing many machine learning tasks. However, for each new dataset, choosing an effective size and structure of the model can be a time-consuming process of trial and error. While a small network with few neurons might not be able to capture the intricacies of a given task, having too many neurons can lead to overfitting and poor generalization. Here, we propose a practical method that employs matrix conditioning to automatically design the structure of layers of a feed-forward network, by first adjusting the proportion of neurons among the layers of a network and then scaling the size of network up or down. Results on sample image and non-image datasets demonstrate that our method results in small networks with high accuracies. Finally, guided by matrix conditioning, we provide a method to effectively squeeze models that are already trained. Our techniques reduce the human cost of designing deep learning models and can also reduce training time and the expense of using neural networks for applications.