 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Optical Flow Estimation Using a Deep Neural Network with a Soft Mask
May 09, 2018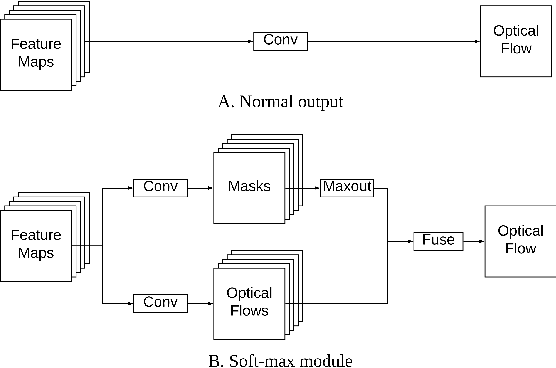
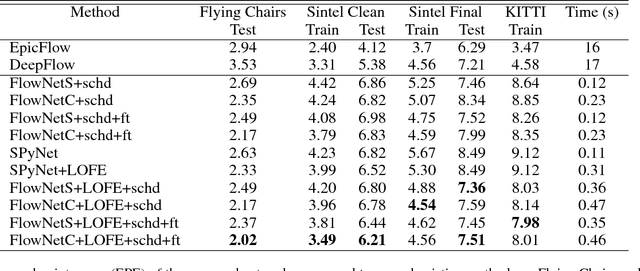
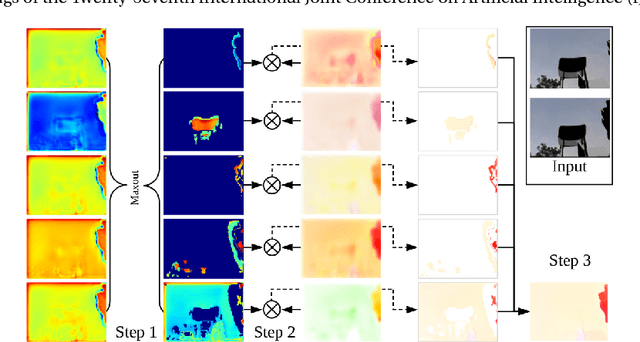
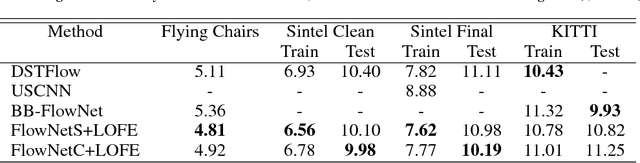
Using a layered representation for motion estimation has the advantage of being able to cope with discontinuities and occlusions. In this paper, we learn to estimate optical flow by combining a layered motion representation with deep learning. Instead of pre-segmenting the image to layers, the proposed approach automatically generates a layered representation of optical flow using the proposed soft-mask module. The essential components of the soft-mask module are maxout and fuse operations, which enable a disjoint layered representation of optical flow and more accurate flow estimation. We show that by using masks the motion estimate results in a quadratic function of input features in the output layer. The proposed soft-mask module can be added to any existing optical flow estimation networks by replacing their flow output layer. In this work, we use FlowNet as the base network to which we add the soft-mask module. The resulting network is tested on three well-known benchmarks with both supervised and unsupervised flow estimation tasks. Evaluation results show that the proposed network achieve better results compared with the original FlowNet.
Lecture video indexing using boosted margin maximizing neural networks
Dec 02, 2017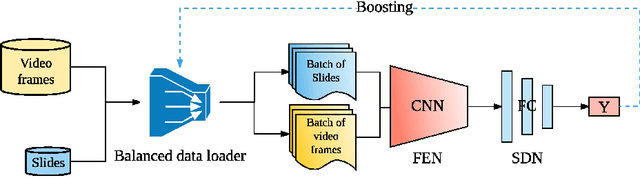

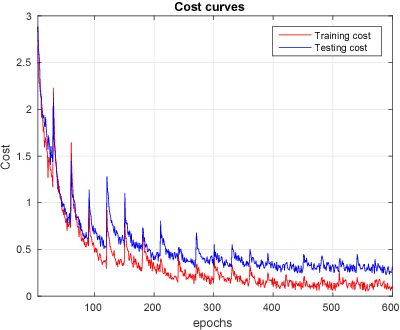

This paper presents a novel approach for lecture video indexing using a boosted deep convolutional neural network system. The indexing is performed by matching high quality slide images, for which text is either known or extracted, to lower resolution video frames with possible noise, perspective distortion, and occlusions. We propose a deep neural network integrated with a boosting framework composed of two sub-networks targeting feature extraction and similarity determination to perform the matching. The trained network is given as input a pair of slide image and a candidate video frame image and produces the similarity between them. A boosting framework is integrated into our proposed network during the training process. Experimental results show that the proposed approach is much more capable of handling occlusion, spatial transformations, and other types of noises when compared with known approaches.
CGMOS: Certainty Guided Minority OverSampling
Jul 21, 2016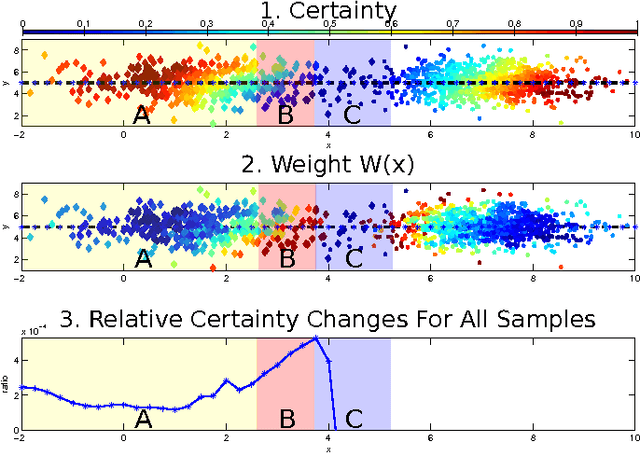
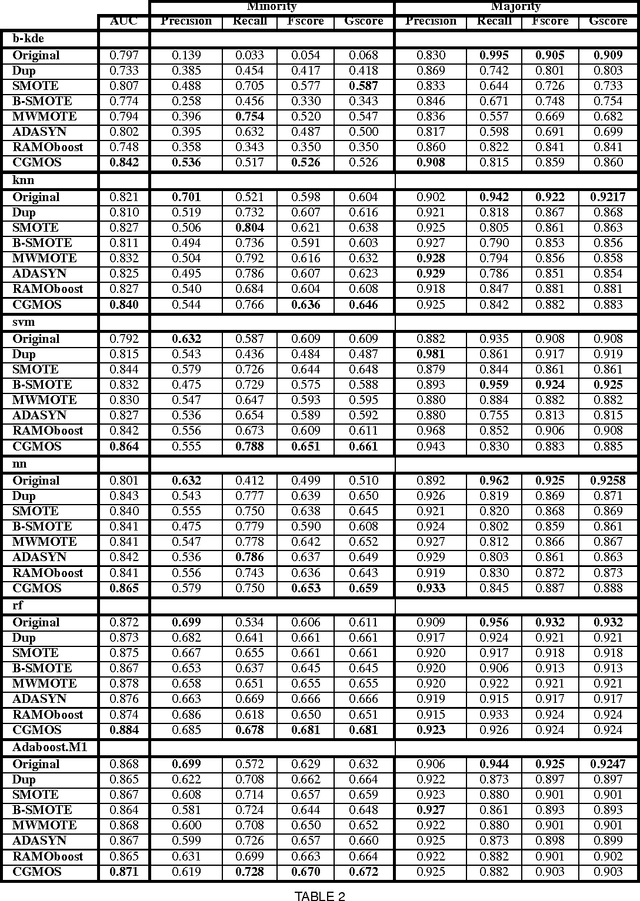
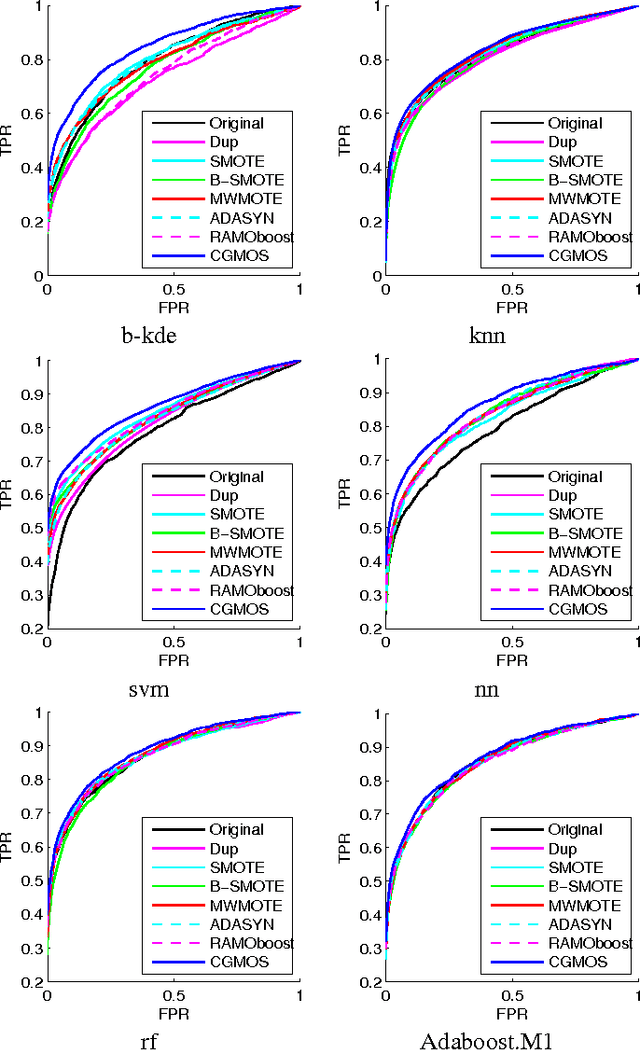
Handling imbalanced datasets is a challenging problem that if not treated correctly results in reduced classification performance. Imbalanced datasets are commonly handled using minority oversampling, whereas the SMOTE algorithm is a successful oversampling algorithm with numerous extensions. SMOTE extensions do not have a theoretical guarantee during training to work better than SMOTE and in many instances their performance is data dependent. In this paper we propose a novel extension to the SMOTE algorithm with a theoretical guarantee for improved classification performance. The proposed approach considers the classification performance of both the majority and minority classes. In the proposed approach CGMOS (Certainty Guided Minority OverSampling) new data points are added by considering certainty changes in the dataset. The paper provides a proof that the proposed algorithm is guaranteed to work better than SMOTE for training data. Further experimental results on 30 real-world datasets show that CGMOS works better than existing algorithms when using 6 different classifiers.