 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausely: A Causal Intelligence Layer for Enterprise AI A Benchmark Study on SRE and Reliability Workflows
May 18, 2026AI agents deployed into SRE workflows currently derive their understanding of environment state from raw observability telemetry at query time, paying a semantic-interpretation tax in tokens, latency, and inferential reliability. We propose Causely, a causal intelligence layer that maintains a structured representation of environment topology, attribute dependencies, and causal relationships that are anchroed to a ontological representation of the managed environment. Causely transforms raw telemetry into a live, queryable model providing the semantic and causal foundation AI agents require to diagnose, evaluate impact, and act safely in production. We evaluate this value proposition through a benchmark study conducted in a controlled setting with injected faults in a 24-microservice OpenTelemetry demo application. Our experiments compare four agent configurations (Claude Code, OpenAI Codex, HolmesGPT with Sonnet and Gemini backends). Experiments are run with and without access to Causely under two scenarios: an active incident and a healthy baseline. On the active-fault scenario, causal grounding reduces mean time-to-diagnosis by 63\%, mean token consumption by 60\%, and mean tool-call count by 78\%, compressing the investigation footprint by 4.8$\times$ and lowering direct API cost per run by 57\%; root-cause-diagnosis accuracy rises from 75\% to 100\%.
Towards Semantic Integration of Opinions: Unified Opinion Concepts Ontology and Extraction Task
May 24, 2025This paper introduces the Unified Opinion Concepts (UOC) ontology to integrate opinions within their semantic context. The UOC ontology bridges the gap between the semantic representation of opinion across different formulations. It is a unified conceptualisation based on the facets of opinions studied extensively in NLP and semantic structures described through symbolic descriptions. We further propose the Unified Opinion Concept Extraction (UOCE) task of extracting opinions from the text with enhanced expressivity. Additionally, we provide a manually extended and re-annotated evaluation dataset for this task and tailored evaluation metrics to assess the adherence of extracted opinions to UOC semantics. Finally, we establish baseline performance for the UOCE task using state-of-the-art generative models.
Mitigating Content Effects on Reasoning in Language Models through Fine-Grained Activation Steering
May 18, 2025Large language models (LLMs) frequently demonstrate reasoning limitations, often conflating content plausibility (i.e., material inference) with logical validity (i.e., formal inference). This can result in biased inferences, where plausible arguments are incorrectly deemed logically valid or vice versa. Mitigating this limitation is critical, as it undermines the trustworthiness and generalizability of LLMs in applications that demand rigorous logical consistency. This paper investigates the problem of mitigating content biases on formal reasoning through activation steering. Specifically, we curate a controlled syllogistic reasoning dataset to disentangle formal validity from content plausibility. After localising the layers responsible for formal and material inference, we investigate contrastive activation steering methods for test-time interventions. An extensive empirical analysis on different LLMs reveals that contrastive steering consistently supports linear control over content biases. However, we observe that a static approach is insufficient for improving all the tested models. We then leverage the possibility to control content effects by dynamically determining the value of the steering parameters via fine-grained conditional methods. We found that conditional steering is effective on unresponsive models, achieving up to 15% absolute improvement in formal reasoning accuracy with a newly introduced kNN-based method (K-CAST). Finally, additional experiments reveal that steering for content effects is robust to prompt variations, incurs minimal side effects on language modeling capabilities, and can partially generalize to out-of-distribution reasoning tasks. Practically, this paper demonstrates that activation-level interventions can offer a scalable strategy for enhancing the robustness of LLMs, contributing towards more systematic and unbiased formal reasoning.
PEIRCE: Unifying Material and Formal Reasoning via LLM-Driven Neuro-Symbolic Refinement
Apr 05, 2025A persistent challenge in AI is the effective integration of material and formal inference - the former concerning the plausibility and contextual relevance of arguments, while the latter focusing on their logical and structural validity. Large Language Models (LLMs), by virtue of their extensive pre-training on large textual corpora, exhibit strong capabilities in material inference. However, their reasoning often lacks formal rigour and verifiability. At the same time, LLMs' linguistic competence positions them as a promising bridge between natural and formal languages, opening up new opportunities for combining these two modes of reasoning. In this paper, we introduce PEIRCE, a neuro-symbolic framework designed to unify material and formal inference through an iterative conjecture-criticism process. Within this framework, LLMs play the central role of generating candidate solutions in natural and formal languages, which are then evaluated and refined via interaction with external critique models. These critiques include symbolic provers, which assess formal validity, as well as soft evaluators that measure the quality of the generated arguments along linguistic and epistemic dimensions such as plausibility, coherence, and parsimony. While PEIRCE is a general-purpose framework, we demonstrate its capabilities in the domain of natural language explanation generation - a setting that inherently demands both material adequacy and formal correctness.
A Semantic Search Pipeline for Causality-driven Adhoc Information Retrieval
Mar 02, 2025We present a unsupervised semantic search pipeline for the Causality-driven Adhoc Information Retrieval (CAIR-2021) shared task. The CAIR shared task expands traditional information retrieval to support the retrieval of documents containing the likely causes of a query event. A successful system must be able to distinguish between topical documents and documents containing causal descriptions of events that are causally related to the query event. Our approach involves aggregating results from multiple query strategies over a semantic and lexical index. The proposed approach leads the CAIR-2021 leaderboard and outperformed both traditional IR and pure semantic embedding-based approaches.
Inference to the Best Explanation in Large Language Models
Feb 16, 2024



While Large Language Models (LLMs) have found success in real-world applications, their underlying explanatory process is still poorly understood. This paper proposes IBE-Eval, a framework inspired by philosophical accounts on Inference to the Best Explanation (IBE) to advance the interpretation and evaluation of LLMs' explanations. IBE-Eval estimates the plausibility of natural language explanations through a combination of explicit logical and linguistic features including: consistency, parsimony, coherence, and uncertainty. Extensive experiments are conducted on Causal Question Answering (CQA), where \textit{IBE-Eval} is tasked to select the most plausible causal explanation amongst competing ones generated by LLMs (i.e., GPT 3.5 and Llama 2). The experiments reveal that IBE-Eval can successfully identify the best explanation with up to 77\% accuracy ($\approx 27\%$ above random), improving upon a GPT 3.5-as-a-Judge baseline ($\approx+17\%$) while being intrinsically more efficient and interpretable. Additional analyses suggest that, despite model-specific variances, LLM-generated explanations tend to conform to IBE criteria and that IBE-Eval is significantly correlated with human judgment, opening up opportunities for future development of automated explanation verification tools.
Evaluating Sequence-to-Sequence Learning Models for If-Then Program Synthesis
Feb 10, 2020


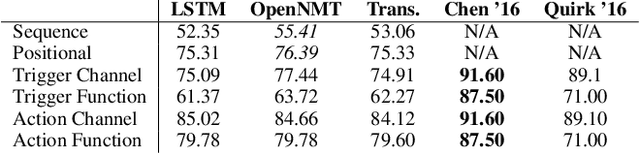
Implementing enterprise process automation often requires significant technical expertise and engineering effort. It would be beneficial for non-technical users to be able to describe a business process in natural language and have an intelligent system generate the workflow that can be automatically executed. A building block of process automations are If-Then programs. In the consumer space, sites like IFTTT and Zapier allow users to create automations by defining If-Then programs using a graphical interface. We explore the efficacy of modeling If-Then programs as a sequence learning task. We find Seq2Seq approaches have high potential (performing strongly on the Zapier recipes) and can serve as a promising approach to more complex program synthesis challenges.