 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Multitask Model for Morpho-Syntactic Parsing
Aug 19, 2025
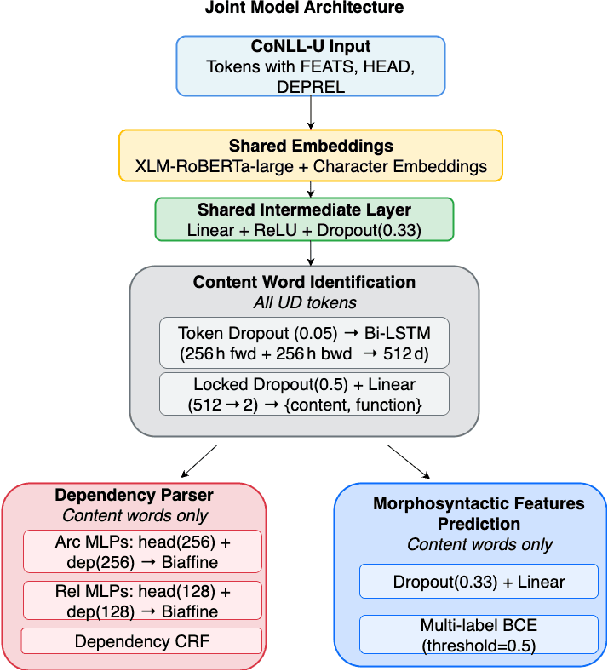
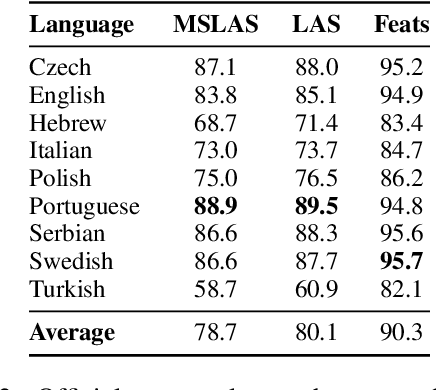
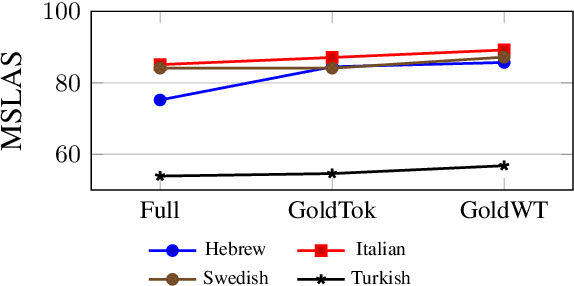
We present a joint multitask model for the UniDive 2025 Morpho-Syntactic Parsing shared task, where systems predict both morphological and syntactic analyses following novel UD annotation scheme. Our system uses a shared XLM-RoBERTa encoder with three specialized decoders for content word identification, dependency parsing, and morphosyntactic feature prediction. Our model achieves the best overall performance on the shared task's leaderboard covering nine typologically diverse languages, with an average MSLAS score of 78.7 percent, LAS of 80.1 percent, and Feats F1 of 90.3 percent. Our ablation studies show that matching the task's gold tokenization and content word identification are crucial to model performance. Error analysis reveals that our model struggles with core grammatical cases (particularly Nom-Acc) and nominal features across languages.