 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQuARM-SGD: Communication-Efficient Momentum SGD for Decentralized Optimization
May 13, 2020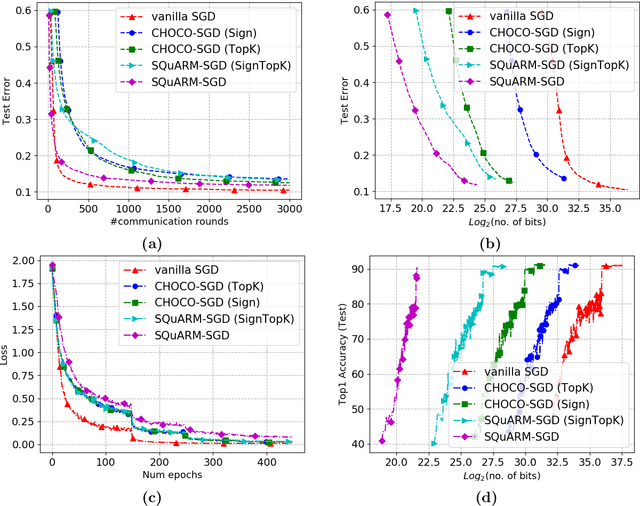
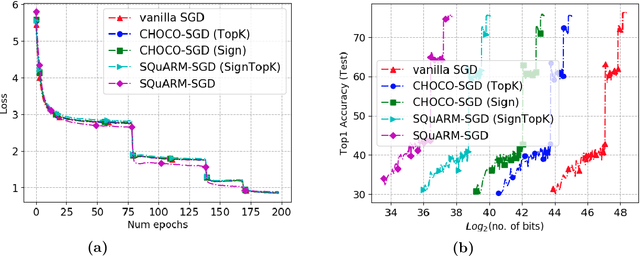
In this paper, we consider the problem of communication-efficient decentralized training of large-scale machine learning models over a network. We propose and analyze SQuARM-SGD, an algorithm for decentralized training, which employs {\em momentum} and {\em compressed communication} between nodes regulated by a locally computable triggering condition in stochastic gradient descent (SGD). In SQuARM-SGD, each node performs a fixed number of local SGD steps using Nesterov's momentum and then sends sparisified and quantized updates to its neighbors only when there is a significant change in the model parameters since the last time communication occurred. We provide convergence guarantees of our algorithm for (smooth) strongly convex and non-convex objectives, and show that SQuARM-SGD converges at a rate of $\mathcal{O}\left(\nicefrac{1}{nT}\right)$ for strongly convex objectives, while for non-convex objectives it convergences at a rate of $\mathcal{O}\left(\nicefrac{1}{\sqrt{nT}}\right)$, thus matching the convergence rate of \emph{vanilla} distributed SGD in both these settings. We corroborate our theoretical understanding with experiments and compare the performance of our algorithm with the state-of-the-art, showing that without sacrificing much on the accuracy, SQuARM-SGD converges at a similar rate while saving significantly in total communicated bits.
SPARQ-SGD: Event-Triggered and Compressed Communication in Decentralized Stochastic Optimization
Oct 31, 2019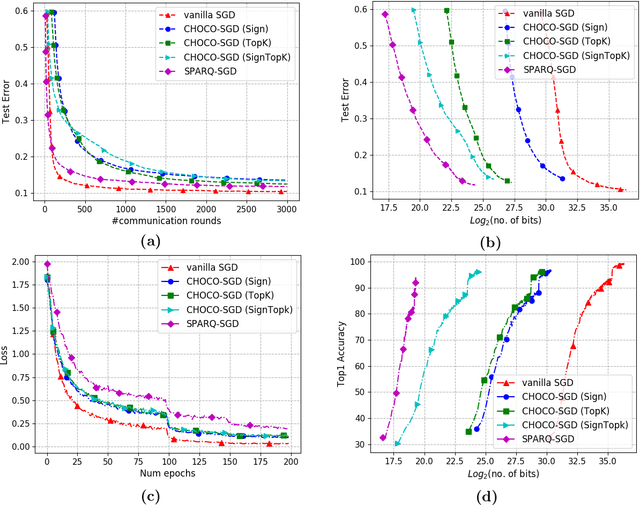
In this paper, we propose and analyze SPARQ-SGD, which is an event-triggered and compressed algorithm for decentralized training of large-scale machine learning models. Each node can locally compute a condition (event) which triggers a communication where quantized and sparsified local model parameters are sent. In SPARQ-SGD each node takes at least a fixed number ($H$) of local gradient steps and then checks if the model parameters have significantly changed compared to its last update; it communicates further compressed model parameters only when there is a significant change, as specified by a (design) criterion. We prove that the SPARQ-SGD converges as $O(\frac{1}{nT})$ and $O(\frac{1}{\sqrt{nT}})$ in the strongly-convex and non-convex settings, respectively, demonstrating that such aggressive compression, including event-triggered communication, model sparsification and quantization does not affect the overall convergence rate as compared to uncompressed decentralized training; thereby theoretically yielding communication efficiency for "free". We evaluate SPARQ-SGD over real datasets to demonstrate significant amount of savings in communication over the state-of-the-art.
Data Encoding for Byzantine-Resilient Distributed Optimization
Jul 05, 2019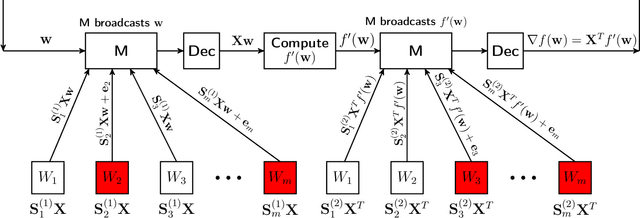
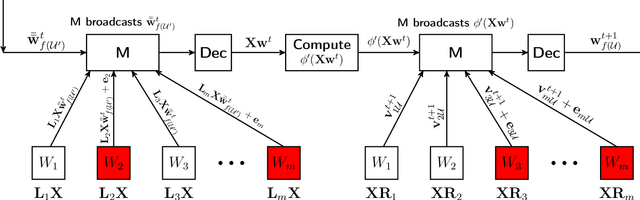
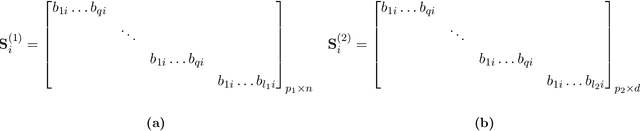
We study distributed optimization in the presence of Byzantine adversaries, where both data and computation are distributed among $m$ worker machines, $t$ of which can be corrupt and collaboratively deviate arbitrarily from their pre-specified programs, and a designated (master) node iteratively computes the model/parameter vector for {\em generalized linear models}. In this work, we primarily focus on two iterative algorithms: {\em Proximal Gradient Descent} (PGD) and {\em Coordinate Descent} (CD). Gradient descent (GD) is a special case of these algorithms. PGD is typically used in the data-parallel setting, where data is partitioned across different samples, whereas, CD is used in the model-parallelism setting, where the data is partitioned across the parameter space. In this paper, we propose a method based on data encoding and error correction over real numbers to combat adversarial attacks. We can tolerate up to $t\leq \lfloor\frac{m-1}{2}\rfloor$ corrupt worker nodes, which is information-theoretically optimal. We give deterministic guarantees, and our method does not assume any probability distribution on the data. We develop a {\em sparse} encoding scheme which enables computationally efficient data encoding and decoding. We demonstrate a trade-off between corruption threshold and the resource requirement (storage and computational/communication complexity). As an example, for $t\leq\frac{m}{3}$, our scheme incurs only a {\em constant} overhead on these resources, over that required by the plain distributed PGD/CD algorithms which provide no adversarial protection. Our encoding scheme extends {\em efficiently} to (i) the data streaming model, where data samples come in an online fashion and are encoded as they arrive, and (ii) making {\em stochastic gradient descent} (SGD) Byzantine-resilient. In the end, we give experimental results to show the efficacy of our method.
Qsparse-local-SGD: Distributed SGD with Quantization, Sparsification, and Local Computations
Jun 06, 2019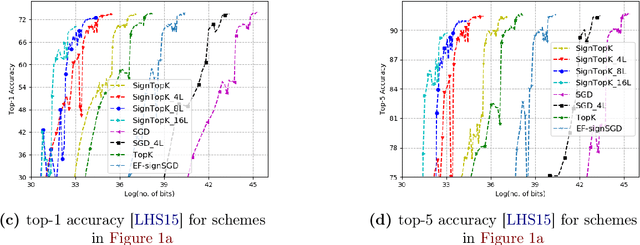
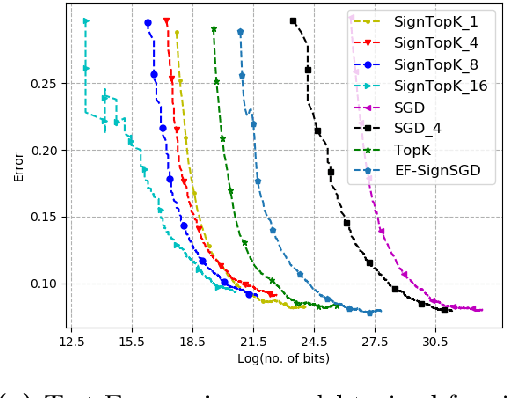
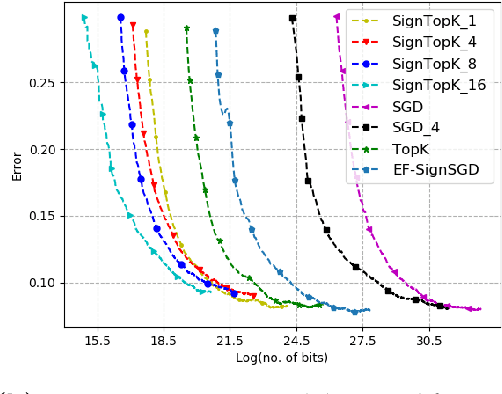
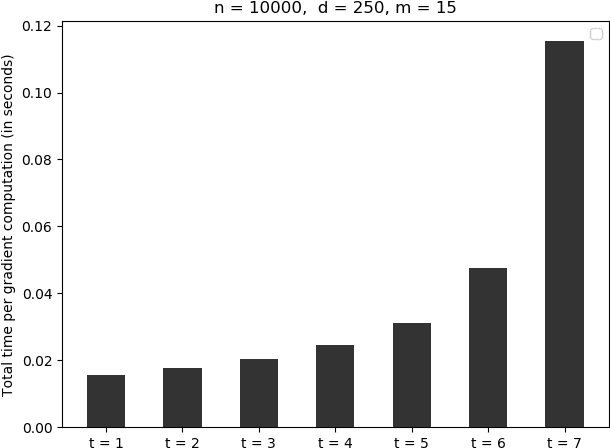
Communication bottleneck has been identified as a significant issue in distributed optimization of large-scale learning models. Recently, several approaches to mitigate this problem have been proposed, including different forms of gradient compression or computing local models and mixing them iteratively. In this paper we propose \emph{Qsparse-local-SGD} algorithm, which combines aggressive sparsification with quantization and local computation along with error compensation, by keeping track of the difference between the true and compressed gradients. We propose both synchronous and asynchronous implementations of \emph{Qsparse-local-SGD}. We analyze convergence for \emph{Qsparse-local-SGD} in the \emph{distributed} setting for smooth non-convex and convex objective functions. We demonstrate that \emph{Qsparse-local-SGD} converges at the same rate as vanilla distributed SGD for many important classes of sparsifiers and quantizers. We use \emph{Qsparse-local-SGD} to train ResNet-50 on ImageNet, and show that it results in significant savings over the state-of-the-art, in the number of bits transmitted to reach target accuracy.