 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of Small Language Models to Fine-tuning Data Contamination
Nov 10, 2025Small Language Models (SLMs) are increasingly being deployed in resource-constrained environments, yet their behavioral robustness to data contamination during instruction tuning remains poorly understood. We systematically investigate the contamination sensitivity of 23 SLMs (270M to 4B parameters) across multiple model families by measuring susceptibility to syntactic and semantic transformation types during instruction tuning: syntactic transformations (character and word reversal) and semantic transformations (irrelevant and counterfactual responses), each applied at contamination levels of 25\%, 50\%, 75\%, and 100\%. Our results reveal fundamental asymmetries in vulnerability patterns: syntactic transformations cause catastrophic performance degradation, with character reversal producing near-complete failure across all models regardless of size or family, while semantic transformations demonstrate distinct threshold behaviors and greater resilience in core linguistic capabilities. Critically, we discover a ``\textit{capability curse}" where larger, more capable models become more susceptible to learning semantic corruptions, effectively following harmful instructions more readily, while our analysis of base versus instruction-tuned variants reveals that alignment provides inconsistent robustness benefits, sometimes even reducing resilience. Our work establishes three core contributions: (1) empirical evidence of SLMs' disproportionate vulnerability to syntactic pattern contamination, (2) identification of asymmetric sensitivity patterns between syntactic and semantic transformations, and (3) systematic evaluation protocols for contamination robustness assessment. These findings have immediate deployment implications, suggesting that current robustness assumptions may not hold for smaller models and highlighting the need for contamination-aware training protocols.
Dissecting Physics Reasoning in Small Language Models: A Multi-Dimensional Analysis from an Educational Perspective
May 27, 2025Small Language Models (SLMs) offer computational efficiency and accessibility, making them promising for educational applications. However, their capacity for complex reasoning, particularly in domains such as physics, remains underexplored. This study investigates the high school physics reasoning capabilities of state-of-the-art SLMs (under 4 billion parameters), including instruct versions of Llama 3.2, Phi 4 Mini, Gemma 3, and Qwen series. We developed a comprehensive physics dataset from the OpenStax High School Physics textbook, annotated according to Bloom's Taxonomy, with LaTeX and plaintext mathematical notations. A novel cultural contextualization approach was applied to a subset, creating culturally adapted problems for Asian, African, and South American/Australian contexts while preserving core physics principles. Using an LLM-as-a-judge framework with Google's Gemini 2.5 Flash, we evaluated answer and reasoning chain correctness, along with calculation accuracy. The results reveal significant differences between the SLMs. Qwen 3 1.7B achieved high `answer accuracy' (85%), but `fully correct reasoning' was substantially low (38%). The format of the mathematical notation had a negligible impact on performance. SLMs exhibited varied performance across the physics topics and showed a decline in reasoning quality with increasing cognitive and knowledge complexity. In particular, the consistency of reasoning was largely maintained in diverse cultural contexts, especially by better performing models. These findings indicate that, while SLMs can often find correct answers, their underlying reasoning is frequently flawed, suggesting an overreliance on pattern recognition. For SLMs to become reliable educational tools in physics, future development must prioritize enhancing genuine understanding and the generation of sound, verifiable reasoning chains over mere answer accuracy.
Harnessing Structured Knowledge: A Concept Map-Based Approach for High-Quality Multiple Choice Question Generation with Effective Distractors
May 02, 2025Generating high-quality MCQs, especially those targeting diverse cognitive levels and incorporating common misconceptions into distractor design, is time-consuming and expertise-intensive, making manual creation impractical at scale. Current automated approaches typically generate questions at lower cognitive levels and fail to incorporate domain-specific misconceptions. This paper presents a hierarchical concept map-based framework that provides structured knowledge to guide LLMs in generating MCQs with distractors. We chose high-school physics as our test domain and began by developing a hierarchical concept map covering major Physics topics and their interconnections with an efficient database design. Next, through an automated pipeline, topic-relevant sections of these concept maps are retrieved to serve as a structured context for the LLM to generate questions and distractors that specifically target common misconceptions. Lastly, an automated validation is completed to ensure that the generated MCQs meet the requirements provided. We evaluate our framework against two baseline approaches: a base LLM and a RAG-based generation. We conducted expert evaluations and student assessments of the generated MCQs. Expert evaluation shows that our method significantly outperforms the baseline approaches, achieving a success rate of 75.20% in meeting all quality criteria compared to approximately 37% for both baseline methods. Student assessment data reveal that our concept map-driven approach achieved a significantly lower guess success rate of 28.05% compared to 37.10% for the baselines, indicating a more effective assessment of conceptual understanding. The results demonstrate that our concept map-based approach enables robust assessment across cognitive levels and instant identification of conceptual gaps, facilitating faster feedback loops and targeted interventions at scale.
A physics-informed transformer neural operator for learning generalized solutions of initial boundary value problems
Dec 12, 2024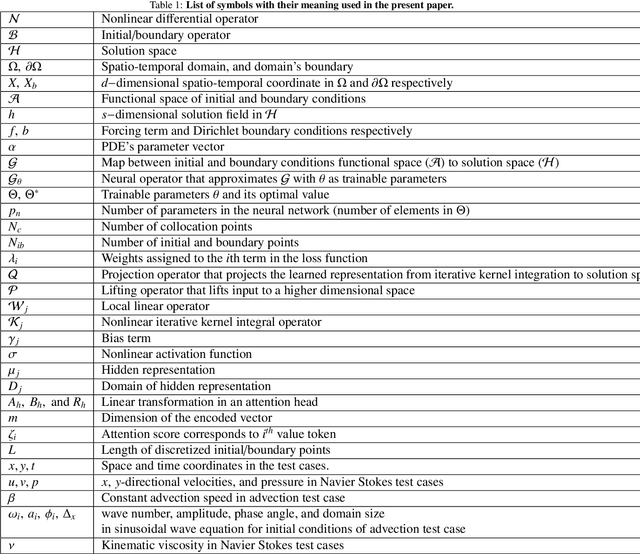
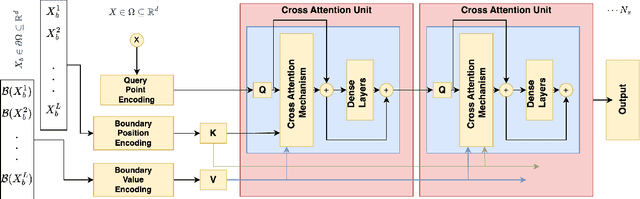
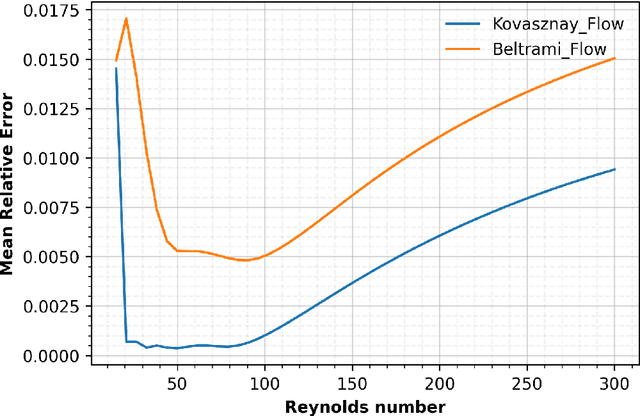
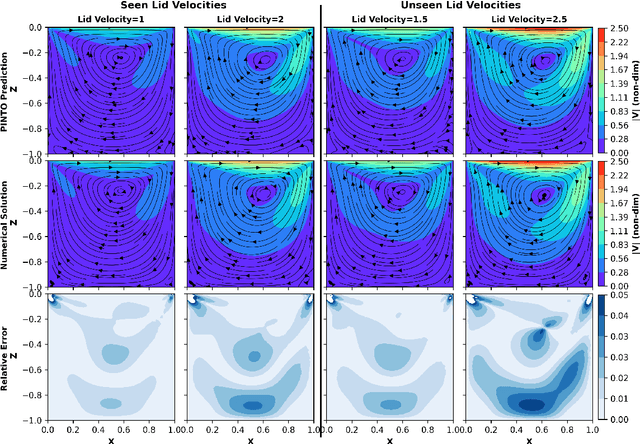
Initial boundary value problems arise commonly in applications with engineering and natural systems governed by nonlinear partial differential equations (PDEs). Operator learning is an emerging field for solving these equations by using a neural network to learn a map between infinite dimensional input and output function spaces. These neural operators are trained using a combination of data (observations or simulations) and PDE-residuals (physics-loss). A major drawback of existing neural approaches is the requirement to retrain with new initial/boundary conditions, and the necessity for a large amount of simulation data for training. We develop a physics-informed transformer neural operator (named PINTO) that efficiently generalizes to unseen initial and boundary conditions, trained in a simulation-free setting using only physics loss. The main innovation lies in our new iterative kernel integral operator units, implemented using cross-attention, to transform the PDE solution's domain points into an initial/boundary condition-aware representation vector, enabling efficient learning of the solution function for new scenarios. The PINTO architecture is applied to simulate the solutions of important equations used in engineering applications: advection, Burgers, and steady and unsteady Navier-Stokes equations (three flow scenarios). For these five test cases, we show that the relative errors during testing under challenging conditions of unseen initial/boundary conditions are only one-fifth to one-third of other leading physics informed operator learning methods. Moreover, our PINTO model is able to accurately solve the advection and Burgers equations at time steps that are not included in the training collocation points. The code is available at $\texttt{https://github.com/quest-lab-iisc/PINTO}$
EvalYaks: Instruction Tuning Datasets and LoRA Fine-tuned Models for Automated Scoring of CEFR B2 Speaking Assessment Transcripts
Aug 22, 2024Relying on human experts to evaluate CEFR speaking assessments in an e-learning environment creates scalability challenges, as it limits how quickly and widely assessments can be conducted. We aim to automate the evaluation of CEFR B2 English speaking assessments in e-learning environments from conversation transcripts. First, we evaluate the capability of leading open source and commercial Large Language Models (LLMs) to score a candidate's performance across various criteria in the CEFR B2 speaking exam in both global and India-specific contexts. Next, we create a new expert-validated, CEFR-aligned synthetic conversational dataset with transcripts that are rated at different assessment scores. In addition, new instruction-tuned datasets are developed from the English Vocabulary Profile (up to CEFR B2 level) and the CEFR-SP WikiAuto datasets. Finally, using these new datasets, we perform parameter efficient instruction tuning of Mistral Instruct 7B v0.2 to develop a family of models called EvalYaks. Four models in this family are for assessing the four sections of the CEFR B2 speaking exam, one for identifying the CEFR level of vocabulary and generating level-specific vocabulary, and another for detecting the CEFR level of text and generating level-specific text. EvalYaks achieved an average acceptable accuracy of 96%, a degree of variation of 0.35 levels, and performed 3 times better than the next best model. This demonstrates that a 7B parameter LLM instruction tuned with high-quality CEFR-aligned assessment data can effectively evaluate and score CEFR B2 English speaking assessments, offering a promising solution for scalable, automated language proficiency evaluation.
Automated Educational Question Generation at Different Bloom's Skill Levels using Large Language Models: Strategies and Evaluation
Aug 08, 2024Developing questions that are pedagogically sound, relevant, and promote learning is a challenging and time-consuming task for educators. Modern-day large language models (LLMs) generate high-quality content across multiple domains, potentially helping educators to develop high-quality questions. Automated educational question generation (AEQG) is important in scaling online education catering to a diverse student population. Past attempts at AEQG have shown limited abilities to generate questions at higher cognitive levels. In this study, we examine the ability of five state-of-the-art LLMs of different sizes to generate diverse and high-quality questions of different cognitive levels, as defined by Bloom's taxonomy. We use advanced prompting techniques with varying complexity for AEQG. We conducted expert and LLM-based evaluations to assess the linguistic and pedagogical relevance and quality of the questions. Our findings suggest that LLms can generate relevant and high-quality educational questions of different cognitive levels when prompted with adequate information, although there is a significant variance in the performance of the five LLms considered. We also show that automated evaluation is not on par with human evaluation.
Can Small Language Models Learn, Unlearn, and Retain Noise Patterns?
Jul 01, 2024Small Language Models (SLMs) are generally considered to be more compact versions of large language models (LLMs), typically having fewer than 7 billion parameters. This study investigates the ability of small language models to learn, retain, and subsequently eliminate noise that is typically not found on the internet, where most pretraining datasets are sourced. For this, four pre-trained SLMs were utilized: Olmo 1B, Qwen1.5 1.8B, Gemma 2B, and Phi2 2.7B. The models were instruction-tuned without noise and tested for task execution with in-context learning. Afterward, noise patterns were introduced to evaluate the models' learning and unlearning capabilities. We evaluated the models' performance at various training levels. Phi consistently excelled with word-level noise but performed the worst with character-level noise. Despite being the smallest with approximately 1 billion parameters, Olmo performed consistently well on tasks.
Optimal Path Planning of Autonomous Marine Vehicles in Stochastic Dynamic Ocean Flows using a GPU-Accelerated Algorithm
Sep 20, 2021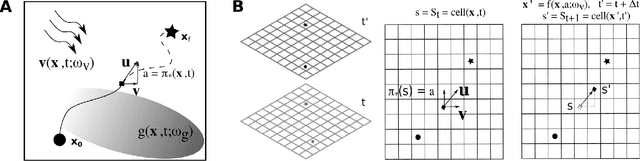
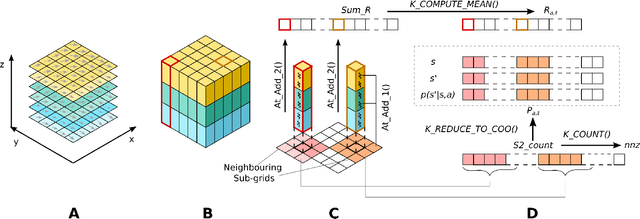
Autonomous marine vehicles play an essential role in many ocean science and engineering applications. Planning time and energy optimal paths for these vehicles to navigate in stochastic dynamic ocean environments is essential to reduce operational costs. In some missions, they must also harvest solar, wind, or wave energy (modeled as a stochastic scalar field) and move in optimal paths that minimize net energy consumption. Markov Decision Processes (MDPs) provide a natural framework for sequential decision-making for robotic agents in such environments. However, building a realistic model and solving the modeled MDP becomes computationally expensive in large-scale real-time applications, warranting the need for parallel algorithms and efficient implementation. In the present work, we introduce an efficient end-to-end GPU-accelerated algorithm that (i) builds the MDP model (computing transition probabilities and expected one-step rewards); and (ii) solves the MDP to compute an optimal policy. We develop methodical and algorithmic solutions to overcome the limited global memory of GPUs by (i) using a dynamic reduced-order representation of the ocean flows, (ii) leveraging the sparse nature of the state transition probability matrix, (iii) introducing a neighbouring sub-grid concept and (iv) proving that it is sufficient to use only the stochastic scalar field's mean to compute the expected one-step rewards for missions involving energy harvesting from the environment; thereby saving memory and reducing the computational effort. We demonstrate the algorithm on a simulated stochastic dynamic environment and highlight that it builds the MDP model and computes the optimal policy 600-1000x faster than conventional CPU implementations, making it suitable for real-time use.