 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpec-Driven Development:From Code to Contract in the Age of AI Coding Assistants
Jan 30, 2026The rise of AI coding assistants has reignited interest in an old idea: what if specifications-not code-were the primary artifact of software development? Spec-driven development (SDD) inverts the traditional workflow by treating specifications as the source of truth and code as a generated or verified secondary artifact. This paper provides practitioners with a comprehensive guide to SDD, covering its principles, workflow patterns, and supporting tools. We present three levels of specification rigor-spec-first, spec-anchored, and spec-as-source-with clear guidance on when each applies. Through analysis of tools ranging from Behavior-Driven Development frameworks to modern AI-assisted toolkits like GitHub Spec Kit, we demonstrate how the spec-first philosophy maps to real implementations. We present case studies from API development, enterprise systems, and embedded software, illustrating how different domains apply SDD. We conclude with a decision framework helping practitioners determine when SDD provides value and when simpler approaches suffice.
PROFASR-BENCH: A Benchmark for Context-Conditioned ASR in High-Stakes Professional Speech
Dec 29, 2025Automatic Speech Recognition (ASR) in professional settings faces challenges that existing benchmarks underplay: dense domain terminology, formal register variation, and near-zero tolerance for critical entity errors. We present ProfASR-Bench, a professional-talk evaluation suite for high-stakes applications across finance, medicine, legal, and technology. Each example pairs a natural-language prompt (domain cue and/or speaker profile) with an entity-rich target utterance, enabling controlled measurement of context-conditioned recognition. The corpus supports conventional ASR metrics alongside entity-aware scores and slice-wise reporting by accent and gender. Using representative families Whisper (encoder-decoder ASR) and Qwen-Omni (audio language models) under matched no-context, profile, domain+profile, oracle, and adversarial conditions, we find a consistent pattern: lightweight textual context produces little to no change in average word error rate (WER), even with oracle prompts, and adversarial prompts do not reliably degrade performance. We term this the context-utilization gap (CUG): current systems are nominally promptable yet underuse readily available side information. ProfASR-Bench provides a standardized context ladder, entity- and slice-aware reporting with confidence intervals, and a reproducible testbed for comparing fusion strategies across model families. Dataset: https://huggingface.co/datasets/prdeepakbabu/ProfASR-Bench Code: https://github.com/prdeepakbabu/ProfASR-Bench
Dynamic LLM Routing and Selection based on User Preferences: Balancing Performance, Cost, and Ethics
Feb 23, 2025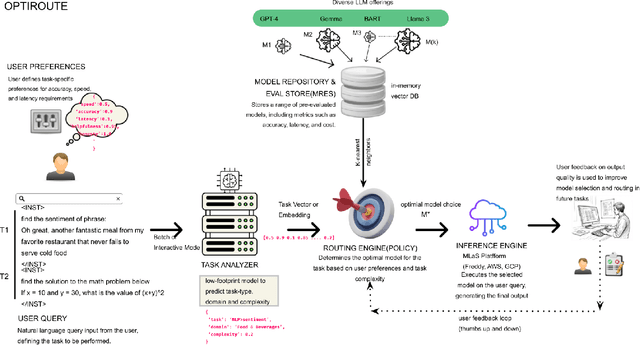

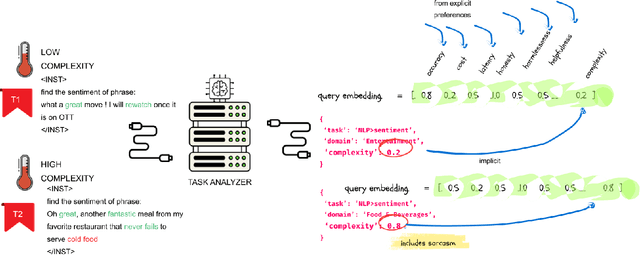
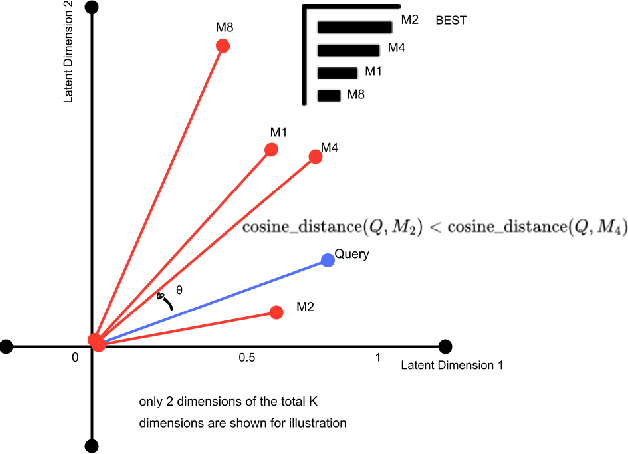
With the widespread deployment of large language models (LLMs) such as GPT4, BART, and LLaMA, the need for a system that can intelligently select the most suitable model for specific tasks while balancing cost, latency, accuracy, and ethical considerations has become increasingly important. Recognizing that not all tasks necessitate models with over 100 billion parameters, we introduce OptiRoute, an advanced model routing engine designed to dynamically select and route tasks to the optimal LLM based on detailed user-defined requirements. OptiRoute captures both functional (e.g., accuracy, speed, cost) and non-functional (e.g., helpfulness, harmlessness, honesty) criteria, leveraging lightweight task analysis and complexity estimation to efficiently match tasks with the best-fit models from a diverse array of LLMs. By employing a hybrid approach combining k-nearest neighbors (kNN) search and hierarchical filtering, OptiRoute optimizes for user priorities while minimizing computational overhead. This makes it ideal for real-time applications in cloud-based ML platforms, personalized AI services, and regulated industries.