 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive Dementia Screening via Facial Temporal Micro-Dynamics Analysis of In-the-Wild Talking-Head Video
Nov 17, 2025



We target passive dementia screening from short camera-facing talking head video, developing a facial temporal micro dynamics analysis for language free detection of early neuro cognitive change. This enables unscripted, in the wild video analysis at scale to capture natural facial behaviors, transferrable across devices, topics, and cultures without active intervention by clinicians or researchers during recording. Most existing resources prioritize speech or scripted interviews, limiting use outside clinics and coupling predictions to language and transcription. In contrast, we identify and analyze whether temporal facial kinematics, including blink dynamics, small mouth jaw motions, gaze variability, and subtle head adjustments, are sufficient for dementia screening without speech or text. By stabilizing facial signals, we convert these micro movements into interpretable facial microdynamic time series, smooth them, and summarize short windows into compact clip level statistics for screening. Each window is encoded by its activity mix (the relative share of motion across streams), thus the predictor analyzes the distribution of motion across streams rather than its magnitude, making per channel effects transparent. We also introduce YT DemTalk, a new dataset curated from publicly available, in the wild camera facing videos. It contains 300 clips (150 with self reported dementia, 150 controls) to test our model and offer a first benchmarking of the corpus. On YT DemTalk, ablations identify gaze lability and mouth/jaw dynamics as the most informative cues, and light weighted shallow classifiers could attain a dementia prediction performance of (AUROC) 0.953, 0.961 Average Precision (AP), 0.851 F1-score, and 0.857 accuracy.
Deep Learning for Domain Adaption: Engagement Recognition
Aug 07, 2018
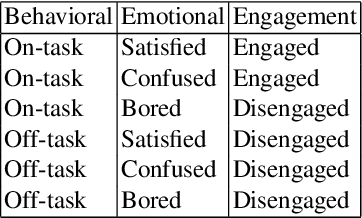

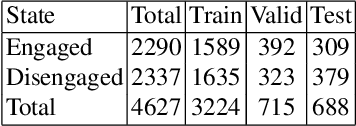
Engagement is a key indicator of the quality of learning experience, and one that plays a major role in developing intelligent educational interfaces. Any such interface requires the ability to recognise the level of engagement in order to respond appropriately; however, there is very little existing data to learn from, and new data is expensive and difficult to acquire. This paper presents a deep learning model to improve engagement recognition from face images captured `in the wild' that overcomes the data sparsity challenge by pre-training on readily available basic facial expression data, before training on specialised engagement data. In the first of two steps, a state-of-the-art facial expression recognition model is trained to provide a rich face representation using deep learning. In the second step, we use the model's weights to initialize our deep learning based model to recognize engagement; we term this the Transfer model. We train the model on our new engagement recognition (ER) dataset with 4627 engaged and disengaged samples. We find that our Transfer architecture outperforms standard deep learning architectures that we apply for the first time to engagement recognition, as well as approaches using HOG features and SVMs. The model achieves a classification accuracy of 72.38%, which is 6.1% better than the best baseline model on the test set of the ER dataset. Using the F1 measure and the area under the ROC curve, our Transfer model achieves 73.90% and 73.74%, exceeding the best baseline model by 3.49% and 5.33% respectively.