 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPTQuant -- A Novel Mixed Precision Post-Training Quantization Techniques for Large Language Models
Dec 03, 2024Large language models have transformed the comprehension and generation of natural language tasks, but they come with substantial memory and computational requirements. Quantization techniques have emerged as a promising avenue for addressing these challenges while preserving accuracy and making energy efficient. We propose CPTQuant, a comprehensive strategy that introduces correlation-based (CMPQ), pruning-based (PMPQ), and Taylor decomposition-based (TDMPQ) mixed precision techniques. CMPQ adapts the precision level based on canonical correlation analysis of different layers. PMPQ optimizes precision layer-wise based on their sensitivity to sparsity. TDMPQ modifies precision using Taylor decomposition to assess each layer's sensitivity to input perturbation. These strategies allocate higher precision to more sensitive layers while diminishing precision to robust layers. CPTQuant assesses the performance across BERT, OPT-125M, OPT-350M, OPT-1.3B, and OPT-2.7B. We demonstrate up to 4x compression and a 2x-fold increase in efficiency with minimal accuracy drop compared to Hugging Face FP16. PMPQ stands out for achieving a considerably higher model compression. Sensitivity analyses across various LLMs show that the initial and final 30% of layers exhibit higher sensitivities than the remaining layers. PMPQ demonstrates an 11% higher compression ratio than other methods for classification tasks, while TDMPQ achieves a 30% greater compression ratio for language modeling tasks.
NeuCASL: From Logic Design to System Simulation of Neuromorphic Engines
Aug 06, 2022With Moore's law saturating and Dennard scaling hitting its wall, traditional Von Neuman systems cannot offer the GFlops/watt for compute-intensive algorithms such as CNN. Recent trends in unconventional computing approaches give us hope to design highly energy-efficient computing systems for such algorithms. Neuromorphic computing is a promising such approach with its brain-inspired circuitry, use of emerging technologies, and low-power nature. Researchers use a variety of novel technologies such as memristors, silicon photonics, FinFET, and carbon nanotubes to demonstrate a neuromorphic computer. However, a flexible CAD tool to start from neuromorphic logic design and go up to architectural simulation is yet to be demonstrated to support the rise of this promising paradigm. In this project, we aim to build NeuCASL, an opensource python-based full system CAD framework for neuromorphic logic design, circuit simulation, and system performance and reliability estimation. This is a first of its kind to the best of our knowledge.
LiteCON: An All-Photonic Neuromorphic Accelerator for Energy-efficient Deep Learning (Preprint)
Jun 28, 2022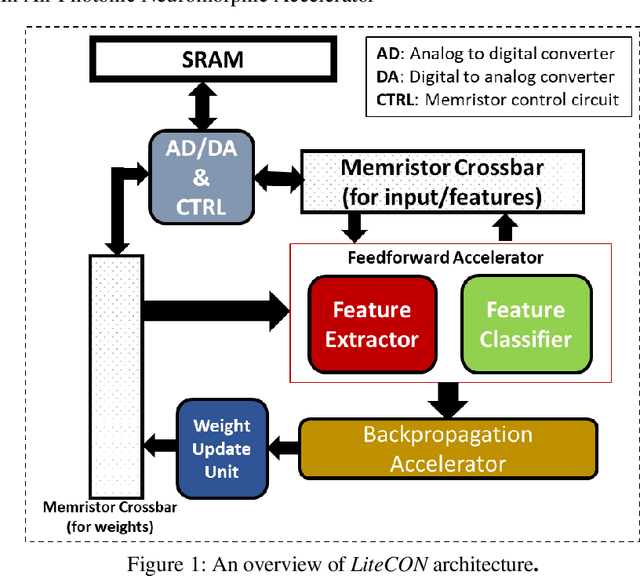
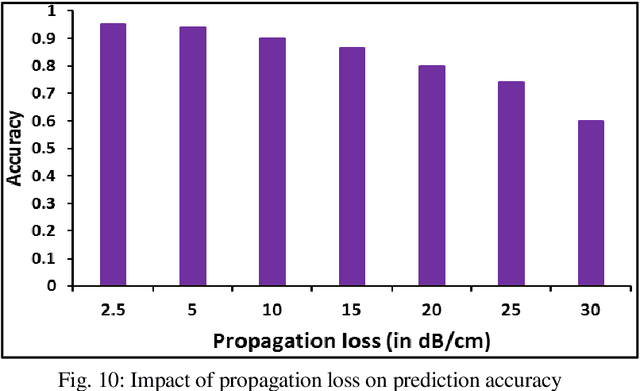
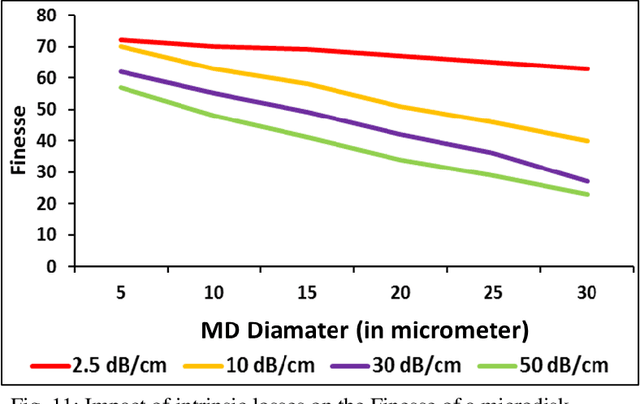
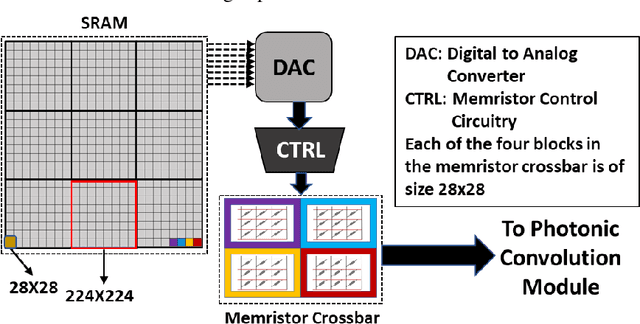
Deep learning is highly pervasive in today's data-intensive era. In particular, convolutional neural networks (CNNs) are being widely adopted in a variety of fields for superior accuracy. However, computing deep CNNs on traditional CPUs and GPUs brings several performance and energy pitfalls. Several novel approaches based on ASIC, FPGA, and resistive-memory devices have been recently demonstrated with promising results. Most of them target only the inference (testing) phase of deep learning. There have been very limited attempts to design a full-fledged deep learning accelerator capable of both training and inference. It is due to the highly compute and memory-intensive nature of the training phase. In this paper, we propose LiteCON, a novel analog photonics CNN accelerator. LiteCON uses silicon microdisk-based convolution, memristor-based memory, and dense-wavelength-division-multiplexing for energy-efficient and ultrafast deep learning. We evaluate LiteCON using a commercial CAD framework (IPKISS) on deep learning benchmark models including LeNet and VGG-Net. Compared to the state-of-the-art, LiteCON improves the CNN throughput, energy efficiency, and computational efficiency by up to 32x, 37x, and 5x respectively with trivial accuracy degradation.