 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling systematic uncertainties in Simulation-Based Inference with Factorizable Normalizing Flows
Feb 13, 2026Unbinned likelihood fits aim at maximizing the information one can extract from experimental data, yet their application in realistic statistical analyses is often hindered by the computational cost of profiling systematic uncertainties. Additionally, current machine learning-based inference methods are typically limited to estimating scalar parameters in a multidimensional space rather than full differential distributions. We propose a general framework for Simulation-Based Inference (SBI) that efficiently profiles nuisance parameters while measuring multivariate Distributions of Interest (DoI), defined as learnable invertible transformations of the feature space. We introduce Factorizable Normalizing Flows to model systematic variations as parametric deformations of a nominal density, preserving tractability without combinatorial explosion. Crucially, we develop an amortized training strategy that learns the conditional dependence of the DoI on nuisance parameters in a single optimization process, bypassing the need for repetitive training during the likelihood scan. This allows for the simultaneous extraction of the underlying distribution and the robust profiling of nuisances. The method is validated on a synthetic dataset emulating a high-energy physics measurement with multiple systematic sources, demonstrating its potential for unbinned, functional measurements in complex analyses.
One flow to correct them all: improving simulations in high-energy physics with a single normalising flow and a switch
Mar 27, 2024Simulated events are key ingredients in almost all high-energy physics analyses. However, imperfections in the simulation can lead to sizeable differences between the observed data and simulated events. The effects of such mismodelling on relevant observables must be corrected either effectively via scale factors, with weights or by modifying the distributions of the observables and their correlations. We introduce a correction method that transforms one multidimensional distribution (simulation) into another one (data) using a simple architecture based on a single normalising flow with a boolean condition. We demonstrate the effectiveness of the method on a physics-inspired toy dataset with non-trivial mismodelling of several observables and their correlations.
Deep learning techniques for energy clustering in the CMS ECAL
Apr 21, 2022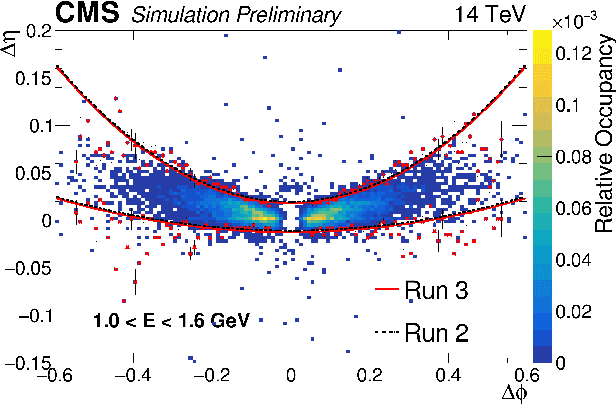
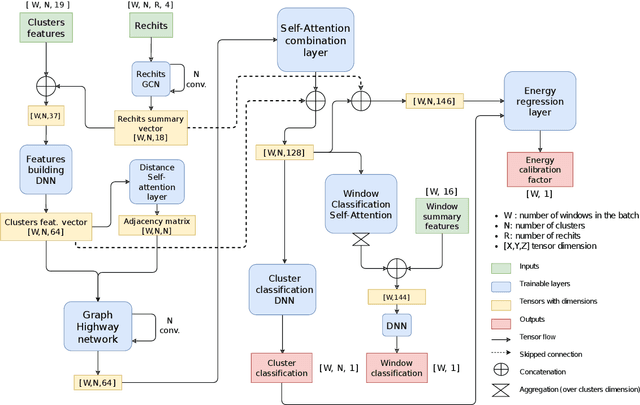
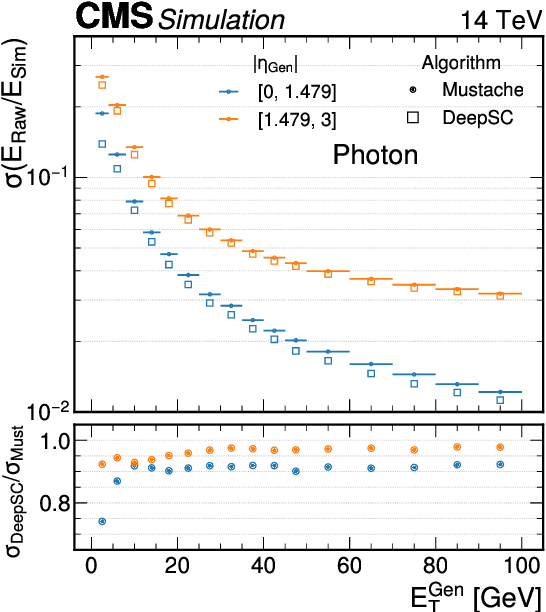
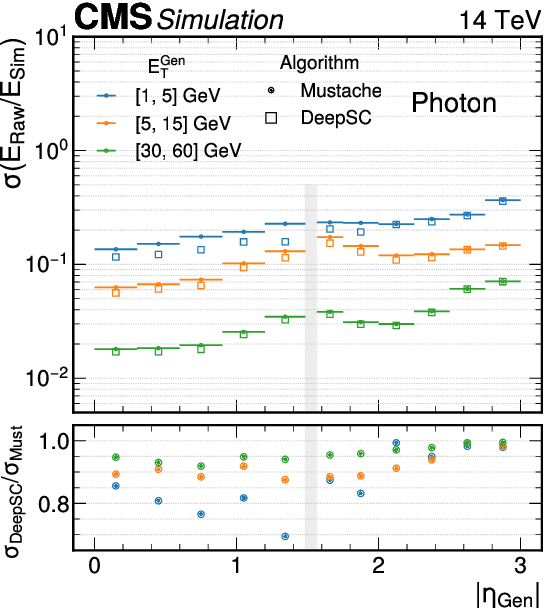
The reconstruction of electrons and photons in CMS depends on topological clustering of the energy deposited by an incident particle in different crystals of the electromagnetic calorimeter (ECAL). These clusters are formed by aggregating neighbouring crystals according to the expected topology of an electromagnetic shower in the ECAL. The presence of upstream material (beampipe, tracker and support structures) causes electrons and photons to start showering before reaching the calorimeter. This effect, combined with the 3.8T CMS magnetic field, leads to energy being spread in several clusters around the primary one. It is essential to recover the energy contained in these satellite clusters in order to achieve the best possible energy resolution for physics analyses. Historically satellite clusters have been associated to the primary cluster using a purely topological algorithm which does not attempt to remove spurious energy deposits from additional pileup interactions (PU). The performance of this algorithm is expected to degrade during LHC Run 3 (2022+) because of the larger average PU levels and the increasing levels of noise due to the ageing of the ECAL detector. New methods are being investigated that exploit state-of-the-art deep learning architectures like Graph Neural Networks (GNN) and self-attention algorithms. These more sophisticated models improve the energy collection and are more resilient to PU and noise, helping to preserve the electron and photon energy resolution achieved during LHC Runs 1 and 2. This work will cover the challenges of training the models as well the opportunity that this new approach offers to unify the ECAL energy measurement with the particle identification steps used in the global CMS photon and electron reconstruction.