 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalliope -- A Polyphonic Music Transformer
Jul 08, 2021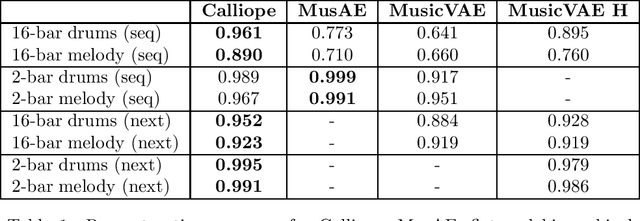
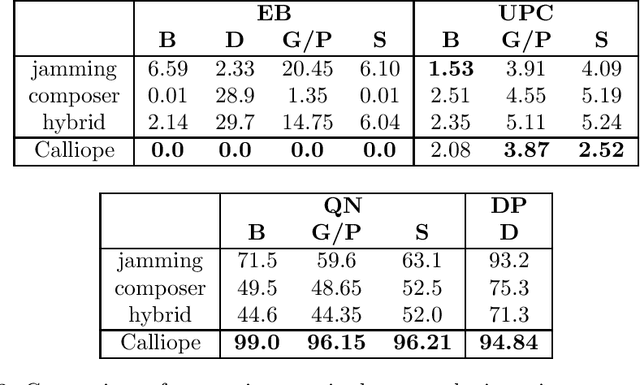
The polyphonic nature of music makes the application of deep learning to music modelling a challenging task. On the other hand, the Transformer architecture seems to be a good fit for this kind of data. In this work, we present Calliope, a novel autoencoder model based on Transformers for the efficient modelling of multi-track sequences of polyphonic music. The experiments show that our model is able to improve the state of the art on musical sequence reconstruction and generation, with remarkably good results especially on long sequences.
Continual Learning with Echo State Networks
May 17, 2021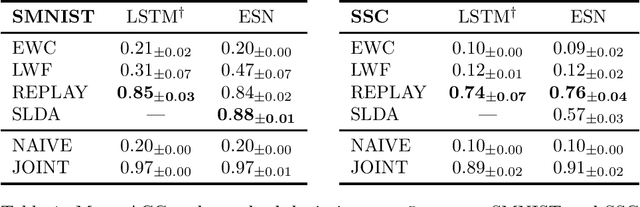
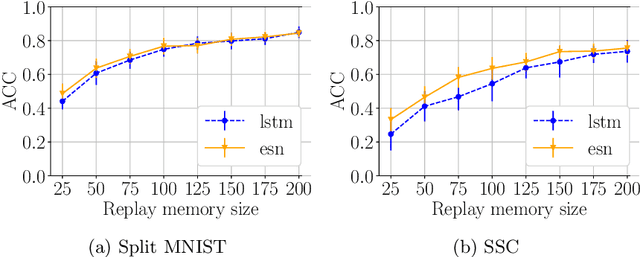
Continual Learning (CL) refers to a learning setup where data is non stationary and the model has to learn without forgetting existing knowledge. The study of CL for sequential patterns revolves around trained recurrent networks. In this work, instead, we introduce CL in the context of Echo State Networks (ESNs), where the recurrent component is kept fixed. We provide the first evaluation of catastrophic forgetting in ESNs and we highlight the benefits in using CL strategies which are not applicable to trained recurrent models. Our results confirm the ESN as a promising model for CL and open to its use in streaming scenarios.
A causal learning framework for the analysis and interpretation of COVID-19 clinical data
May 14, 2021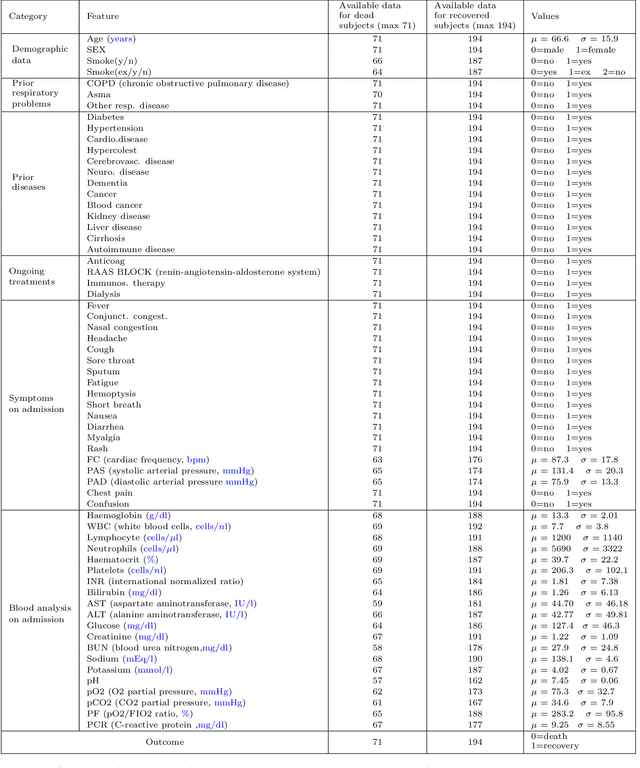
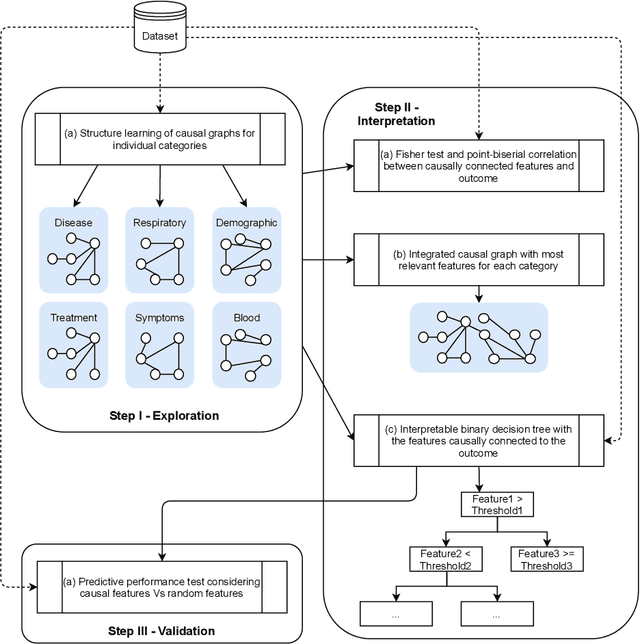
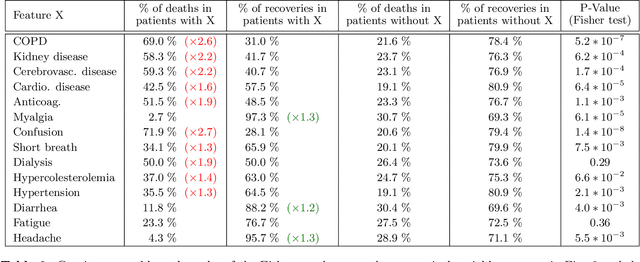
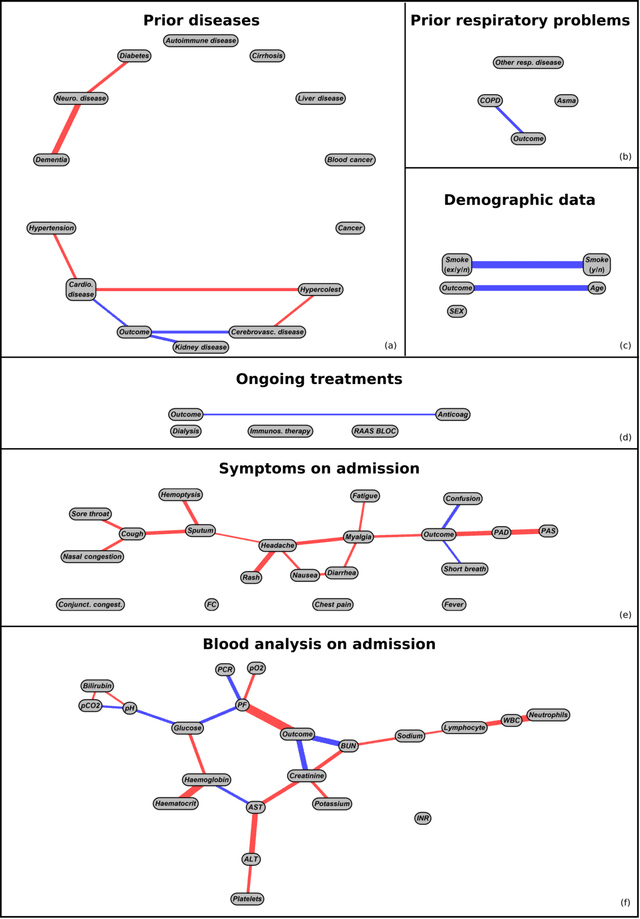
We present a workflow for clinical data analysis that relies on Bayesian Structure Learning (BSL), an unsupervised learning approach, robust to noise and biases, that allows to incorporate prior medical knowledge into the learning process and that provides explainable results in the form of a graph showing the causal connections among the analyzed features. The workflow consists in a multi-step approach that goes from identifying the main causes of patient's outcome through BSL, to the realization of a tool suitable for clinical practice, based on a Binary Decision Tree (BDT), to recognize patients at high-risk with information available already at hospital admission time. We evaluate our approach on a feature-rich COVID-19 dataset, showing that the proposed framework provides a schematic overview of the multi-factorial processes that jointly contribute to the outcome. We discuss how these computational findings are confirmed by current understanding of the COVID-19 pathogenesis. Further, our approach yields to a highly interpretable tool correctly predicting the outcome of 85% of subjects based exclusively on 3 features: age, a previous history of chronic obstructive pulmonary disease and the PaO2/FiO2 ratio at the time of arrival to the hospital. The inclusion of additional information from 4 routine blood tests (Creatinine, Glucose, pO2 and Sodium) increases predictive accuracy to 94.5%.
Addressing Fairness, Bias and Class Imbalance in Machine Learning: the FBI-loss
May 13, 2021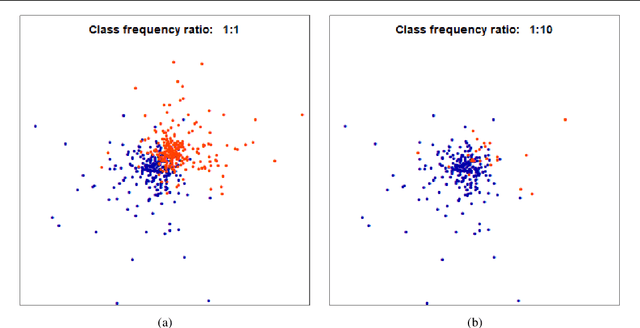
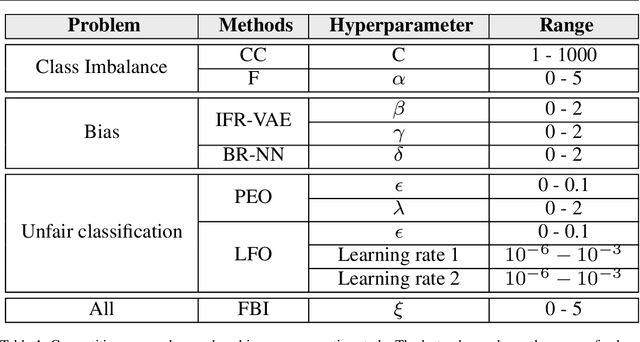
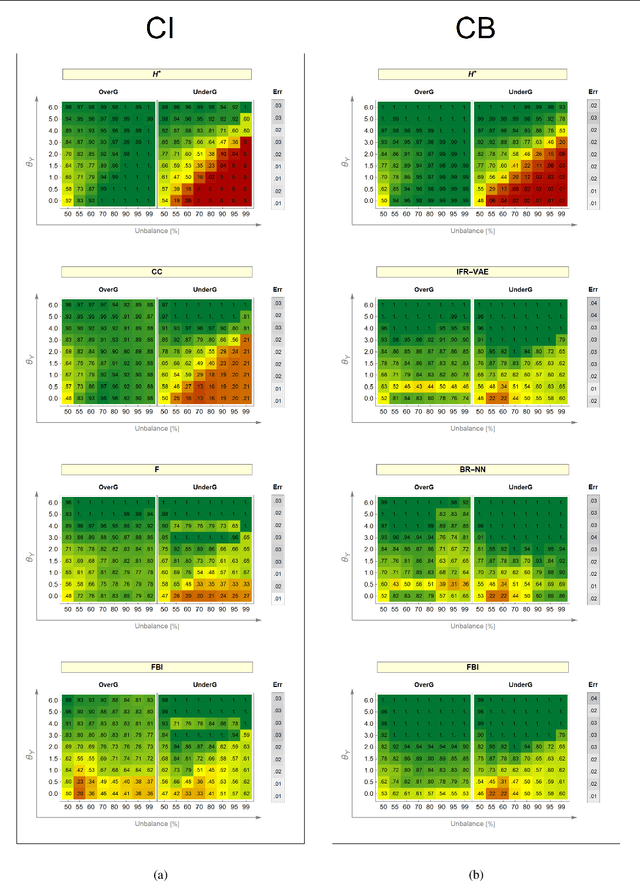
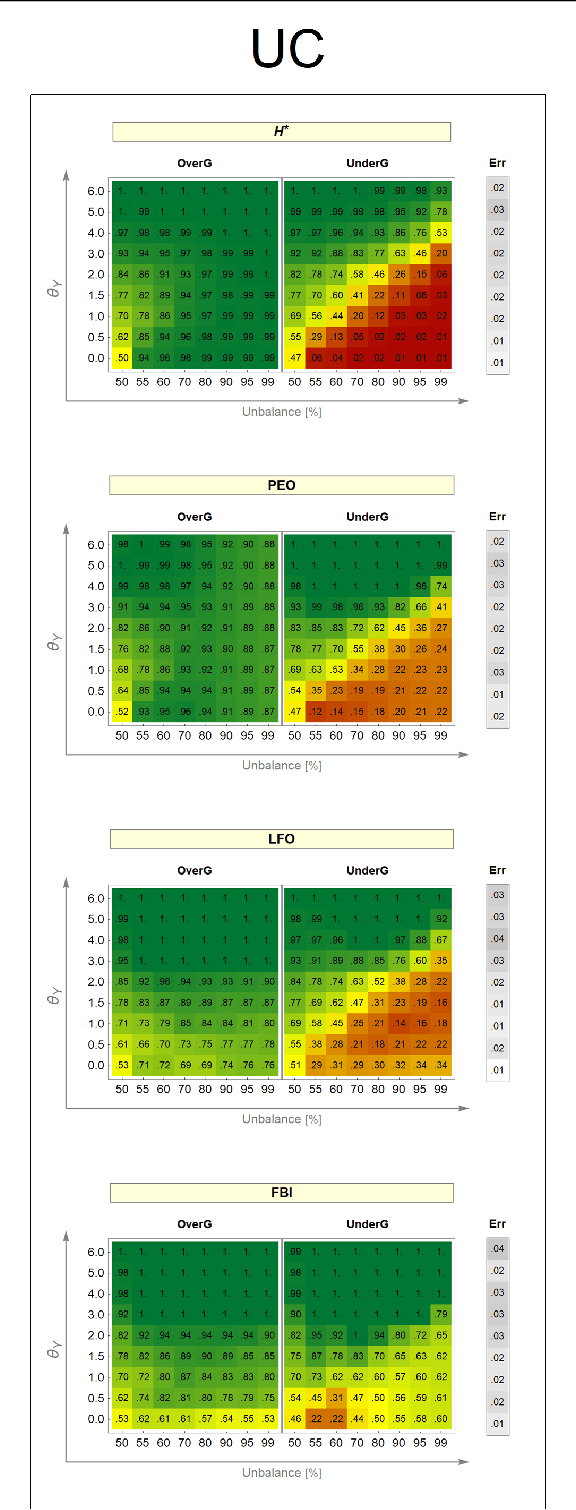
Resilience to class imbalance and confounding biases, together with the assurance of fairness guarantees are highly desirable properties of autonomous decision-making systems with real-life impact. Many different targeted solutions have been proposed to address separately these three problems, however a unifying perspective seems to be missing. With this work, we provide a general formalization, showing that they are different expressions of unbalance. Following this intuition, we formulate a unified loss correction to address issues related to Fairness, Biases and Imbalances (FBI-loss). The correction capabilities of the proposed approach are assessed on three real-world benchmarks, each associated to one of the issues under consideration, and on a family of synthetic data in order to better investigate the effectiveness of our loss on tasks with different complexities. The empirical results highlight that the flexible formulation of the FBI-loss leads also to competitive performances with respect to literature solutions specialised for the single problems.
MEG: Generating Molecular Counterfactual Explanations for Deep Graph Networks
Apr 16, 2021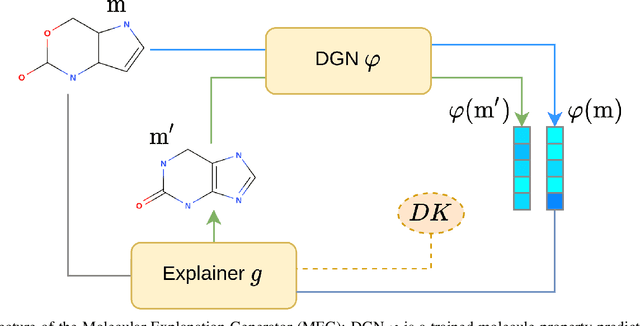
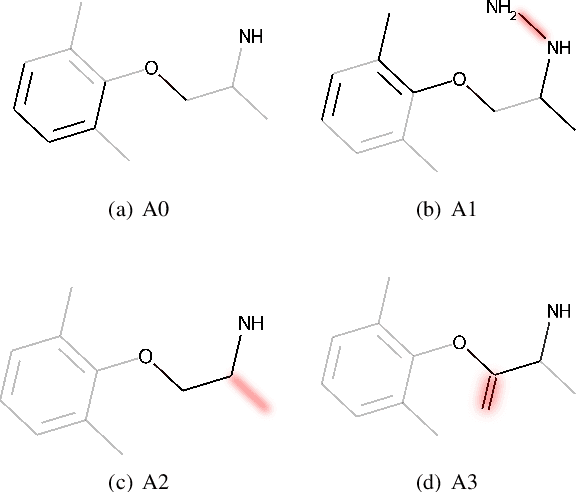
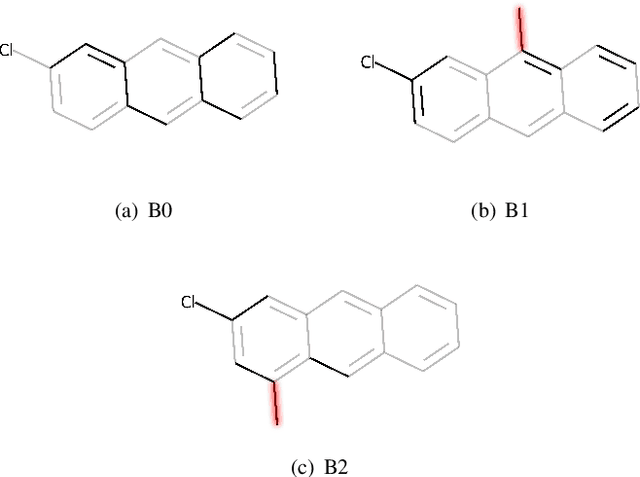
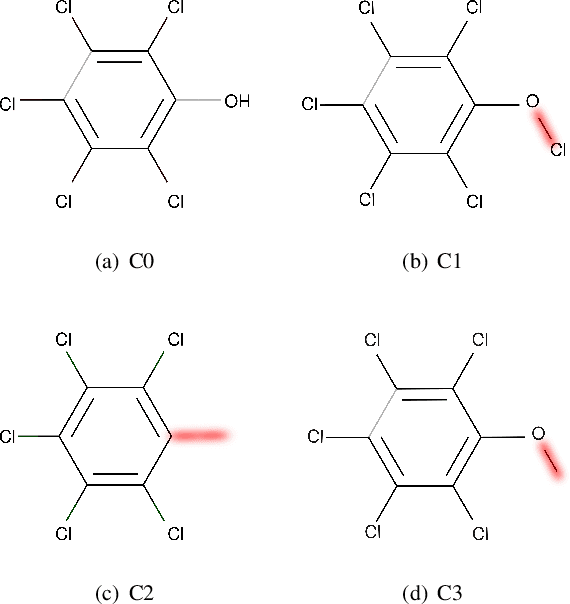
Explainable AI (XAI) is a research area whose objective is to increase trustworthiness and to enlighten the hidden mechanism of opaque machine learning techniques. This becomes increasingly important in case such models are applied to the chemistry domain, for its potential impact on humans' health, e.g, toxicity analysis in pharmacology. In this paper, we present a novel approach to tackle explainability of deep graph networks in the context of molecule property prediction t asks, named MEG (Molecular Explanation Generator). We generate informative counterfactual explanations for a specific prediction under the form of (valid) compounds with high structural similarity and different predicted properties. Given a trained DGN, we train a reinforcement learning based generator to output counterfactual explanations. At each step, MEG feeds the current candidate counterfactual into the DGN, collects the prediction and uses it to reward the RL agent to guide the exploration. Furthermore, we restrict the action space of the agent in order to only keep actions that maintain the molecule in a valid state. We discuss the results showing how the model can convey non-ML experts with key insights into the learning model focus in the neighbourhood of a molecule.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021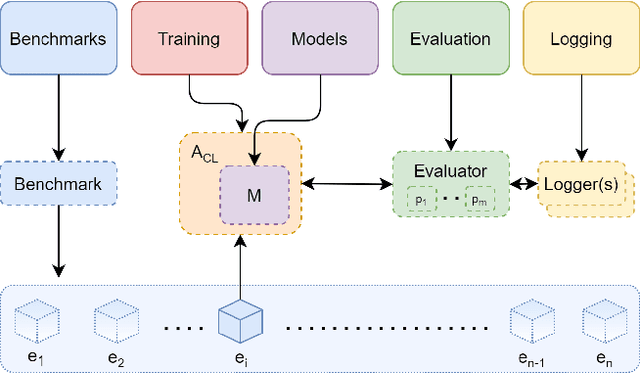

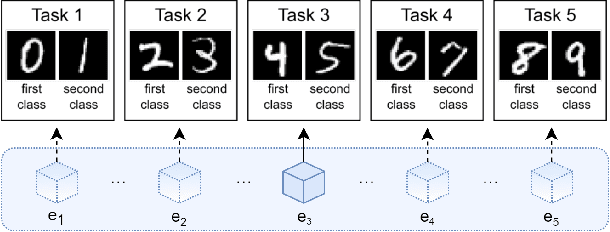

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
Distilled Replay: Overcoming Forgetting through Synthetic Samples
Mar 29, 2021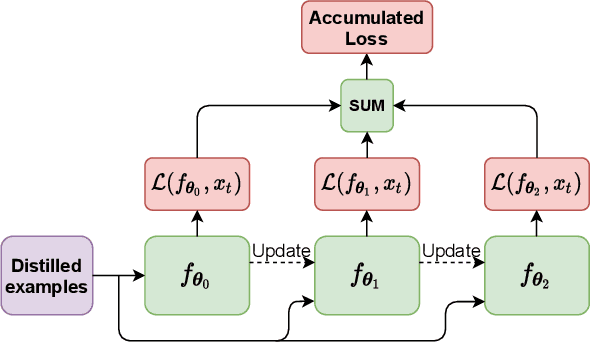

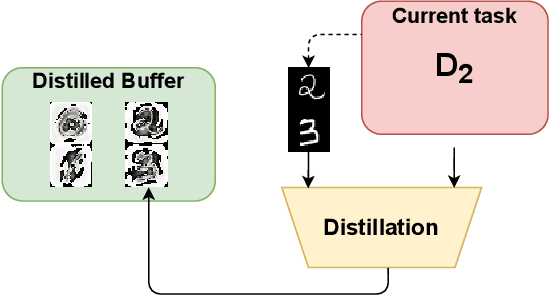
Replay strategies are Continual Learning techniques which mitigate catastrophic forgetting by keeping a buffer of patterns from previous experience, which are interleaved with new data during training. The amount of patterns stored in the buffer is a critical parameter which largely influences the final performance and the memory footprint of the approach. This work introduces Distilled Replay, a novel replay strategy for Continual Learning which is able to mitigate forgetting by keeping a very small buffer (up to $1$ pattern per class) of highly informative samples. Distilled Replay builds the buffer through a distillation process which compresses a large dataset into a tiny set of informative examples. We show the effectiveness of our Distilled Replay against naive replay, which randomly samples patterns from the dataset, on four popular Continual Learning benchmarks.
Continual Learning for Recurrent Neural Networks: an Empirical Evaluation
Mar 24, 2021
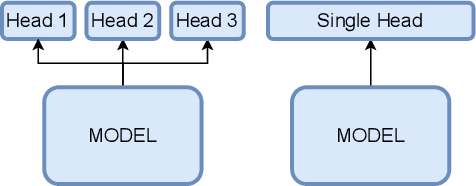
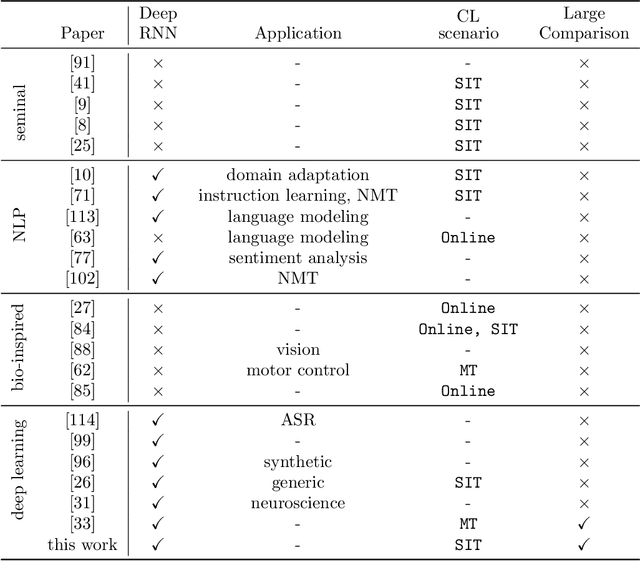
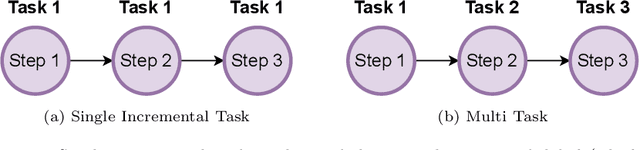
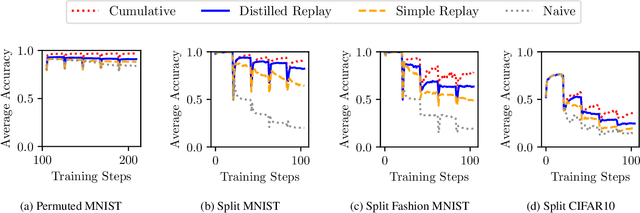
Learning continuously during all model lifetime is fundamental to deploy machine learning solutions robust to drifts in the data distribution. Advances in Continual Learning (CL) with recurrent neural networks could pave the way to a large number of applications where incoming data is non stationary, like natural language processing and robotics. However, the existing body of work on the topic is still fragmented, with approaches which are application-specific and whose assessment is based on heterogeneous learning protocols and datasets. In this paper, we organize the literature on CL for sequential data processing by providing a categorization of the contributions and a review of the benchmarks. We propose two new benchmarks for CL with sequential data based on existing datasets, whose characteristics resemble real-world applications. We also provide a broad empirical evaluation of CL and Recurrent Neural Networks in class-incremental scenario, by testing their ability to mitigate forgetting with a number of different strategies which are not specific to sequential data processing. Our results highlight the key role played by the sequence length and the importance of a clear specification of the CL scenario.
Catastrophic Forgetting in Deep Graph Networks: an Introductory Benchmark for Graph Classification
Mar 22, 2021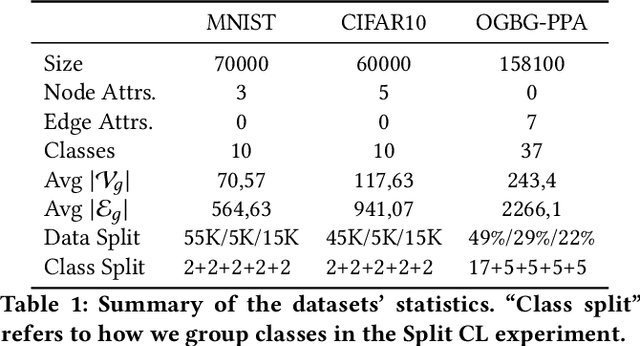
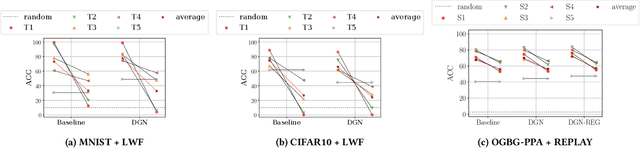
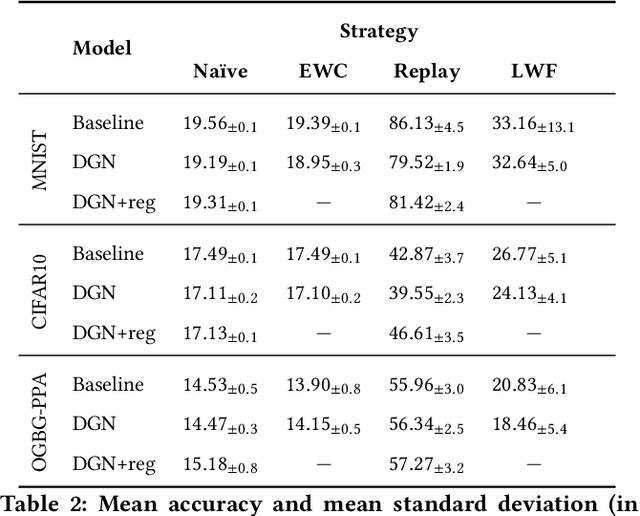
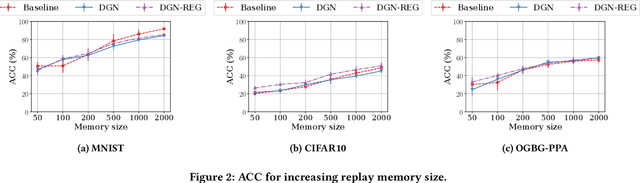
In this work, we study the phenomenon of catastrophic forgetting in the graph representation learning scenario. The primary objective of the analysis is to understand whether classical continual learning techniques for flat and sequential data have a tangible impact on performances when applied to graph data. To do so, we experiment with a structure-agnostic model and a deep graph network in a robust and controlled environment on three different datasets. The benchmark is complemented by an investigation on the effect of structure-preserving regularization techniques on catastrophic forgetting. We find that replay is the most effective strategy in so far, which also benefits the most from the use of regularization. Our findings suggest interesting future research at the intersection of the continual and graph representation learning fields. Finally, we provide researchers with a flexible software framework to reproduce our results and carry out further experiments.
Graph Mixture Density Networks
Dec 05, 2020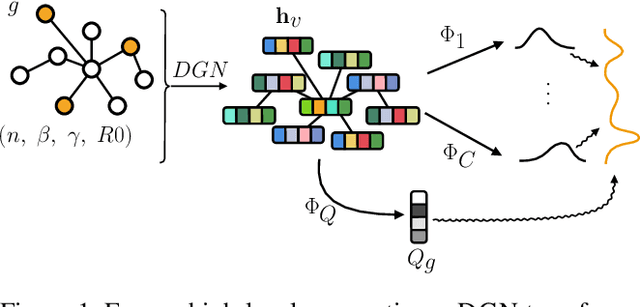
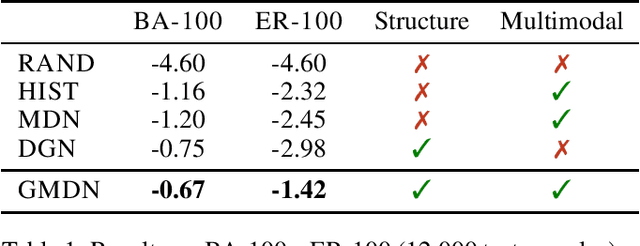
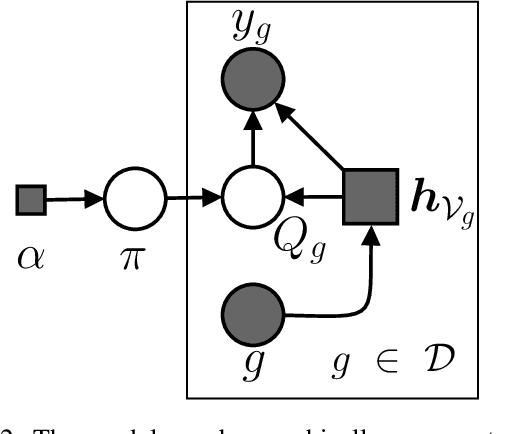
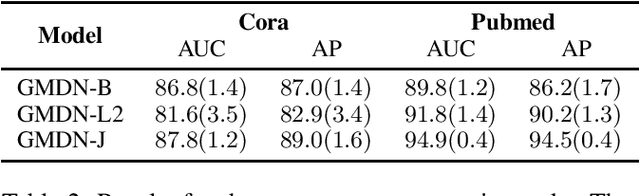
We introduce the Graph Mixture Density Network, a new family of machine learning models that can fit multimodal output distributions conditioned on arbitrary input graphs. By combining ideas from mixture models and graph representation learning, we address a broad class of challenging regression problems that rely on structured data. Our main contribution is the design and evaluation of our method on large stochastic epidemic simulations conditioned on random graphs. We show that there is a significant improvement in the likelihood of an epidemic outcome when taking into account both multimodality and structure. In addition, we investigate how to \textit{implicitly} retain structural information in node representations by computing the distance between distributions of adjacent nodes, and the technique is tested on two structure reconstruction tasks with very good accuracy. Graph Mixture Density Networks open appealing research opportunities in the study of structure-dependent phenomena that exhibit non-trivial conditional output distributions.