 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Conformal Prediction under Data Scarcity: Exploring the Impacts of Nonconformity Measures
Oct 13, 2024



Conformal prediction, which makes no distributional assumptions about the data, has emerged as a powerful and reliable approach to uncertainty quantification in practical applications. The nonconformity measure used in conformal prediction quantifies how a test sample differs from the training data and the effectiveness of a conformal prediction interval may depend heavily on the precise measure employed. The impact of this choice has, however, not been widely explored, especially when dealing with limited amounts of data. The primary objective of this study is to evaluate the performance of various nonconformity measures (absolute error-based, normalized absolute error-based, and quantile-based measures) in terms of validity and efficiency when used in inductive conformal prediction. The focus is on small datasets, which is still a common setting in many real-world applications. Using synthetic and real-world data, we assess how different characteristics -- such as dataset size, noise, and dimensionality -- can affect the efficiency of conformal prediction intervals. Our results show that although there are differences, no single nonconformity measure consistently outperforms the others, as the effectiveness of each nonconformity measure is heavily influenced by the specific nature of the data. Additionally, we found that increasing dataset size does not always improve efficiency, suggesting the importance of fine-tuning models and, again, the need to carefully select the nonconformity measure for different applications.
Proactive and Reactive Constraint Programming for Stochastic Project Scheduling with Maximal Time-Lags
Sep 13, 2024



This study investigates scheduling strategies for the stochastic resource-constrained project scheduling problem with maximal time lags (SRCPSP/max)). Recent advances in Constraint Programming (CP) and Temporal Networks have reinvoked interest in evaluating the advantages and drawbacks of various proactive and reactive scheduling methods. First, we present a new, CP-based fully proactive method. Second, we show how a reactive approach can be constructed using an online rescheduling procedure. A third contribution is based on partial order schedules and uses Simple Temporal Networks with Uncertainty (STNUs). Our statistical analysis shows that the STNU-based algorithm performs best in terms of solution quality, while also showing good relative offline and online computation time.
PATE: Proximity-Aware Time series anomaly Evaluation
May 20, 2024Evaluating anomaly detection algorithms in time series data is critical as inaccuracies can lead to flawed decision-making in various domains where real-time analytics and data-driven strategies are essential. Traditional performance metrics assume iid data and fail to capture the complex temporal dynamics and specific characteristics of time series anomalies, such as early and delayed detections. We introduce Proximity-Aware Time series anomaly Evaluation (PATE), a novel evaluation metric that incorporates the temporal relationship between prediction and anomaly intervals. PATE uses proximity-based weighting considering buffer zones around anomaly intervals, enabling a more detailed and informed assessment of a detection. Using these weights, PATE computes a weighted version of the area under the Precision and Recall curve. Our experiments with synthetic and real-world datasets show the superiority of PATE in providing more sensible and accurate evaluations than other evaluation metrics. We also tested several state-of-the-art anomaly detectors across various benchmark datasets using the PATE evaluation scheme. The results show that a common metric like Point-Adjusted F1 Score fails to characterize the detection performances well, and that PATE is able to provide a more fair model comparison. By introducing PATE, we redefine the understanding of model efficacy that steers future studies toward developing more effective and accurate detection models.
RESTAD: REconstruction and Similarity based Transformer for time series Anomaly Detection
May 13, 2024



Anomaly detection in time series data is crucial across various domains. The scarcity of labeled data for such tasks has increased the attention towards unsupervised learning methods. These approaches, often relying solely on reconstruction error, typically fail to detect subtle anomalies in complex datasets. To address this, we introduce RESTAD, an adaptation of the Transformer model by incorporating a layer of Radial Basis Function (RBF) neurons within its architecture. This layer fits a non-parametric density in the latent representation, such that a high RBF output indicates similarity with predominantly normal training data. RESTAD integrates the RBF similarity scores with the reconstruction errors to increase sensitivity to anomalies. Our empirical evaluations demonstrate that RESTAD outperforms various established baselines across multiple benchmark datasets.
Learning From Scenarios for Stochastic Repairable Scheduling
Dec 06, 2023


When optimizing problems with uncertain parameter values in a linear objective, decision-focused learning enables end-to-end learning of these values. We are interested in a stochastic scheduling problem, in which processing times are uncertain, which brings uncertain values in the constraints, and thus repair of an initial schedule may be needed. Historical realizations of the stochastic processing times are available. We show how existing decision-focused learning techniques based on stochastic smoothing can be adapted to this scheduling problem. We include an extensive experimental evaluation to investigate in which situations decision-focused learning outperforms the state of the art for such situations: scenario-based stochastic optimization.
Personalized Anomaly Detection in PPG Data using Representation Learning and Biometric Identification
Jul 12, 2023



Photoplethysmography (PPG) signals, typically acquired from wearable devices, hold significant potential for continuous fitness-health monitoring. In particular, heart conditions that manifest in rare and subtle deviating heart patterns may be interesting. However, robust and reliable anomaly detection within these data remains a challenge due to the scarcity of labeled data and high inter-subject variability. This paper introduces a two-stage framework leveraging representation learning and personalization to improve anomaly detection performance in PPG data. The proposed framework first employs representation learning to transform the original PPG signals into a more discriminative and compact representation. We then apply three different unsupervised anomaly detection methods for movement detection and biometric identification. We validate our approach using two different datasets in both generalized and personalized scenarios. The results show that representation learning significantly improves anomaly detection performance while reducing the high inter-subject variability. Personalized models further enhance anomaly detection performance, underscoring the role of personalization in PPG-based fitness-health monitoring systems. The results from biometric identification show that it's easier to distinguish a new user from one intended authorized user than from a group of users. Overall, this study provides evidence of the effectiveness of representation learning and personalization for anomaly detection in PPG data.
iPINNs: Incremental learning for Physics-informed neural networks
Apr 10, 2023



Physics-informed neural networks (PINNs) have recently become a powerful tool for solving partial differential equations (PDEs). However, finding a set of neural network parameters that lead to fulfilling a PDE can be challenging and non-unique due to the complexity of the loss landscape that needs to be traversed. Although a variety of multi-task learning and transfer learning approaches have been proposed to overcome these issues, there is no incremental training procedure for PINNs that can effectively mitigate such training challenges. We propose incremental PINNs (iPINNs) that can learn multiple tasks (equations) sequentially without additional parameters for new tasks and improve performance for every equation in the sequence. Our approach learns multiple PDEs starting from the simplest one by creating its own subnetwork for each PDE and allowing each subnetwork to overlap with previously learned subnetworks. We demonstrate that previous subnetworks are a good initialization for a new equation if PDEs share similarities. We also show that iPINNs achieve lower prediction error than regular PINNs for two different scenarios: (1) learning a family of equations (e.g., 1-D convection PDE); and (2) learning PDEs resulting from a combination of processes (e.g., 1-D reaction-diffusion PDE). The ability to learn all problems with a single network together with learning more complex PDEs with better generalization than regular PINNs will open new avenues in this field.
Self-Supervised PPG Representation Learning Shows High Inter-Subject Variability
Dec 19, 2022With the progress of sensor technology in wearables, the collection and analysis of PPG signals are gaining more interest. Using Machine Learning, the cardiac rhythm corresponding to PPG signals can be used to predict different tasks such as activity recognition, sleep stage detection, or more general health status. However, supervised learning is often limited by the amount of available labeled data, which is typically expensive to obtain. To address this problem, we propose a Self-Supervised Learning (SSL) method with a pretext task of signal reconstruction to learn an informative generalized PPG representation. The performance of the proposed SSL framework is compared with two fully supervised baselines. The results show that in a very limited label data setting (10 samples per class or less), using SSL is beneficial, and a simple classifier trained on SSL-learned representations outperforms fully supervised deep neural networks. However, the results reveal that the SSL-learned representations are too focused on encoding the subjects. Unfortunately, there is high inter-subject variability in the SSL-learned representations, which makes working with this data more challenging when labeled data is scarce. The high inter-subject variability suggests that there is still room for improvements in learning representations. In general, the results suggest that SSL may pave the way for the broader use of machine learning models on PPG data in label-scarce regimes.
A view on model misspecification in uncertainty quantification
Nov 02, 2022



Estimating uncertainty of machine learning models is essential to assess the quality of the predictions that these models provide. However, there are several factors that influence the quality of uncertainty estimates, one of which is the amount of model misspecification. Model misspecification always exists as models are mere simplifications or approximations to reality. The question arises whether the estimated uncertainty under model misspecification is reliable or not. In this paper, we argue that model misspecification should receive more attention, by providing thought experiments and contextualizing these with relevant literature.
Continual Prune-and-Select: Class-incremental learning with specialized subnetworks
Aug 09, 2022
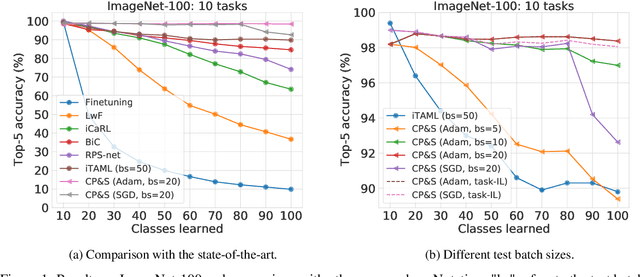
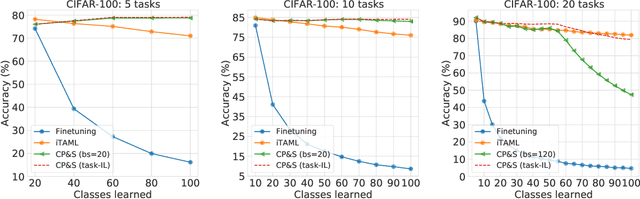
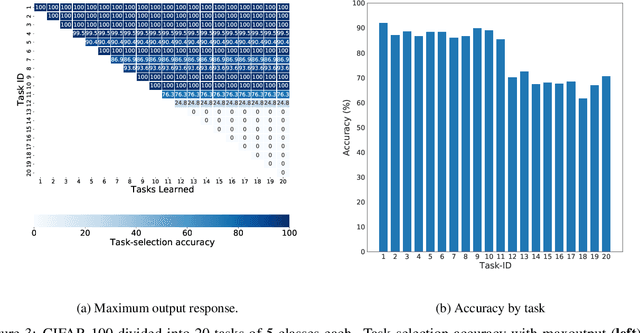
The human brain is capable of learning tasks sequentially mostly without forgetting. However, deep neural networks (DNNs) suffer from catastrophic forgetting when learning one task after another. We address this challenge considering a class-incremental learning scenario where the DNN sees test data without knowing the task from which this data originates. During training, Continual-Prune-and-Select (CP&S) finds a subnetwork within the DNN that is responsible for solving a given task. Then, during inference, CP&S selects the correct subnetwork to make predictions for that task. A new task is learned by training available neuronal connections of the DNN (previously untrained) to create a new subnetwork by pruning, which can include previously trained connections belonging to other subnetwork(s) because it does not update shared connections. This enables to eliminate catastrophic forgetting by creating specialized regions in the DNN that do not conflict with each other while still allowing knowledge transfer across them. The CP&S strategy is implemented with different subnetwork selection strategies, revealing superior performance to state-of-the-art continual learning methods tested on various datasets (CIFAR-100, CUB-200-2011, ImageNet-100 and ImageNet-1000). In particular, CP&S is capable of sequentially learning 10 tasks from ImageNet-1000 keeping an accuracy around 94% with negligible forgetting, a first-of-its-kind result in class-incremental learning. To the best of the authors' knowledge, this represents an improvement in accuracy above 20% when compared to the best alternative method.