 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Heuristic Evaluation: A Comparison between AI- and Human-Powered Usability Evaluation
Jul 03, 2025Usability evaluation is crucial in human-centered design but can be costly, requiring expert time and user compensation. In this work, we developed a method for synthetic heuristic evaluation using multimodal LLMs' ability to analyze images and provide design feedback. Comparing our synthetic evaluations to those by experienced UX practitioners across two apps, we found our evaluation identified 73% and 77% of usability issues, which exceeded the performance of 5 experienced human evaluators (57% and 63%). Compared to human evaluators, the synthetic evaluation's performance maintained consistent performance across tasks and excelled in detecting layout issues, highlighting potential attentional and perceptual strengths of synthetic evaluation. However, synthetic evaluation struggled with recognizing some UI components and design conventions, as well as identifying across screen violations. Additionally, testing synthetic evaluations over time and accounts revealed stable performance. Overall, our work highlights the performance differences between human and LLM-driven evaluations, informing the design of synthetic heuristic evaluations.
Levels of Autonomy for AI Agents
Jun 14, 2025Autonomy is a double-edged sword for AI agents, simultaneously unlocking transformative possibilities and serious risks. How can agent developers calibrate the appropriate levels of autonomy at which their agents should operate? We argue that an agent's level of autonomy can be treated as a deliberate design decision, separate from its capability and operational environment. In this work, we define five levels of escalating agent autonomy, characterized by the roles a user can take when interacting with an agent: operator, collaborator, consultant, approver, and observer. Within each level, we describe the ways by which a user can exert control over the agent and open questions for how to design the nature of user-agent interaction. We then highlight a potential application of our framework towards AI autonomy certificates to govern agent behavior in single- and multi-agent systems. We conclude by proposing early ideas for evaluating agents' autonomy. Our work aims to contribute meaningful, practical steps towards responsibly deployed and useful AI agents in the real world.
Dissecting a Social Botnet: Growth, Content and Influence in Twitter
Apr 13, 2016

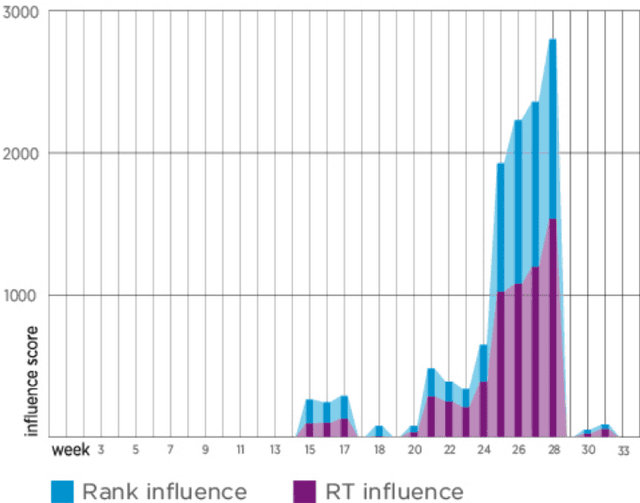

Social botnets have become an important phenomenon on social media. There are many ways in which social bots can disrupt or influence online discourse, such as, spam hashtags, scam twitter users, and astroturfing. In this paper we considered one specific social botnet in Twitter to understand how it grows over time, how the content of tweets by the social botnet differ from regular users in the same dataset, and lastly, how the social botnet may have influenced the relevant discussions. Our analysis is based on a qualitative coding for approximately 3000 tweets in Arabic and English from the Syrian social bot that was active for 35 weeks on Twitter before it was shutdown. We find that the growth, behavior and content of this particular botnet did not specifically align with common conceptions of botnets. Further we identify interesting aspects of the botnet that distinguish it from regular users.