 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-Effect Graph Kernels for LLM Interpretability
May 07, 2026Mechanistic interpretability aims to reverse-engineer transformer computations by identifying causal circuits through activation patching. However, scaling these interventions across diverse prompts and task families produces high-dimensional, unstructured datasets that are difficult to compare systematically. We propose a framework that reframes mechanistic analysis as a graph machine-learning problem by representing activation-patching profiles as patch-effect graphs over model components. We introduce three graph-construction methods: direct-influence via causal mediation, partial-correlation, and co-influence and apply graph kernels to analyze the resulting structures. Evaluating this approach on GPT-2 Small using Indirect Object Identification (IOI) and related tasks, we find that patch-effect graphs preserve discriminative structural signals. Specifically, localized edge-slot features provide higher classification accuracy than global graph-shape descriptors. A screened paired-patching validation suggests that CI and PC selected candidate edges correspond to stronger activation-influence effects than random or low-rank candidates. Crucially, by evaluating these representations against rigorous prompt-only and raw patch-effect controls, we make the evidential scope of the benchmark explicit: graph features compress structured patching signal, while raw tensors and surface cues define strong baselines that any circuit-level claim should address. Ultimately, our framework provides a compression and evaluation pipeline for comparing patching-derived structures under controlled baselines, separating robust slice-discriminative evidence from stronger task-general causal-circuit claims.
KPCA Spatio-temporal trajectory point cloud classifier for recognizing human actions in a CBVR system
Mar 26, 2014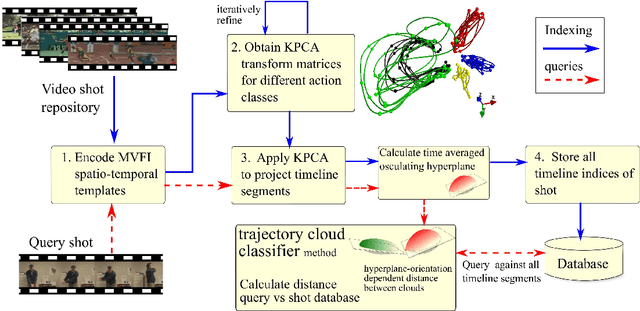

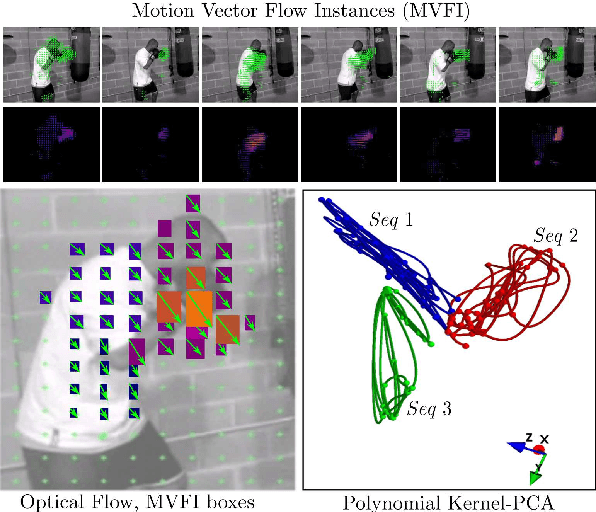

We describe a content based video retrieval (CBVR) software system for identifying specific locations of a human action within a full length film, and retrieving similar video shots from a query. For this, we introduce the concept of a trajectory point cloud for classifying unique actions, encoded in a spatio-temporal covariant eigenspace, where each point is characterized by its spatial location, local Frenet-Serret vector basis, time averaged curvature and torsion and the mean osculating hyperplane. Since each action can be distinguished by their unique trajectories within this space, the trajectory point cloud is used to define an adaptive distance metric for classifying queries against stored actions. Depending upon the distance to other trajectories, the distance metric uses either large scale structure of the trajectory point cloud, such as the mean distance between cloud centroids or the difference in hyperplane orientation, or small structure such as the time averaged curvature and torsion, to classify individual points in a fuzzy-KNN. Our system can function in real-time and has an accuracy greater than 93% for multiple action recognition within video repositories. We demonstrate the use of our CBVR system in two situations: by locating specific frame positions of trained actions in two full featured films, and video shot retrieval from a database with a web search application.