 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of Charniak's "Statistical Language Learning"
Jun 21, 1995This article is an in-depth review of Eugene Charniak's book, "Statistical Language Learning". The review evaluates the appropriateness of the book as an introductory text for statistical language learning for a variety of audiences. It also includes an extensive bibliography of articles and papers which might be used as a supplement to this book for learning or teaching statistical language modeling.
Statistical Decision-Tree Models for Parsing
Apr 29, 1995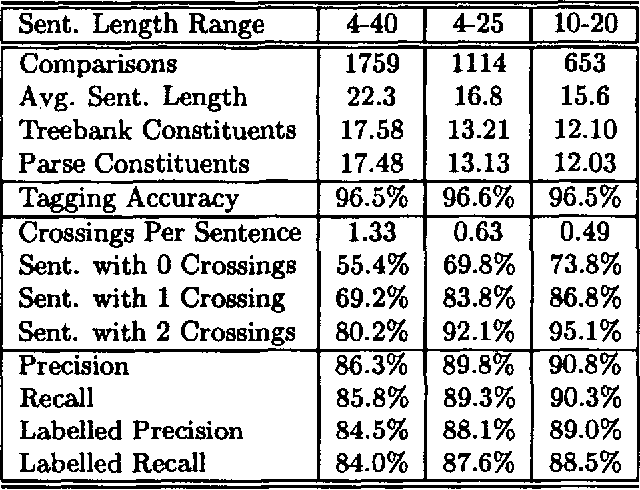
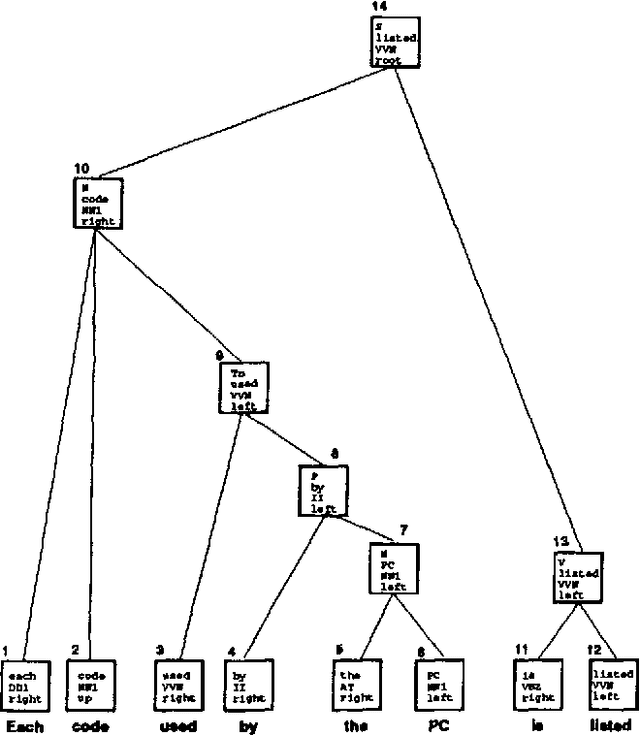
Syntactic natural language parsers have shown themselves to be inadequate for processing highly-ambiguous large-vocabulary text, as is evidenced by their poor performance on domains like the Wall Street Journal, and by the movement away from parsing-based approaches to text-processing in general. In this paper, I describe SPATTER, a statistical parser based on decision-tree learning techniques which constructs a complete parse for every sentence and achieves accuracy rates far better than any published result. This work is based on the following premises: (1) grammars are too complex and detailed to develop manually for most interesting domains; (2) parsing models must rely heavily on lexical and contextual information to analyze sentences accurately; and (3) existing {$n$}-gram modeling techniques are inadequate for parsing models. In experiments comparing SPATTER with IBM's computer manuals parser, SPATTER significantly outperforms the grammar-based parser. Evaluating SPATTER against the Penn Treebank Wall Street Journal corpus using the PARSEVAL measures, SPATTER achieves 86\% precision, 86\% recall, and 1.3 crossing brackets per sentence for sentences of 40 words or less, and 91\% precision, 90\% recall, and 0.5 crossing brackets for sentences between 10 and 20 words in length.
* uses aclap.sty, psfig.tex (v1.9), postscript figures
Natural Language Parsing as Statistical Pattern Recognition
May 05, 1994
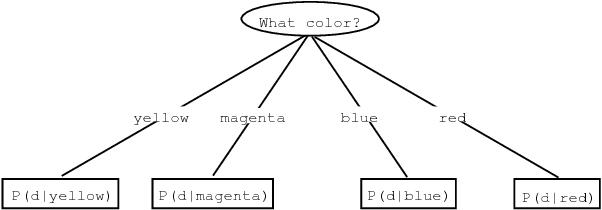
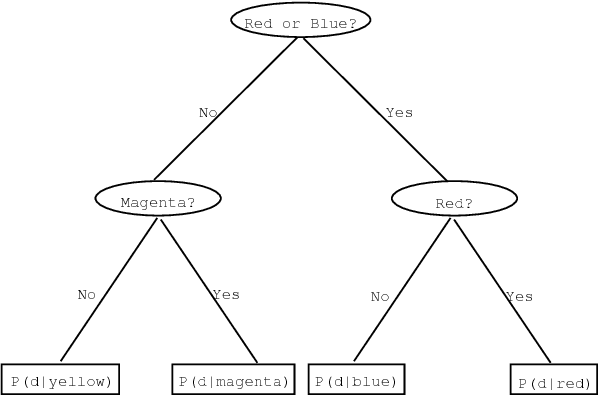

Traditional natural language parsers are based on rewrite rule systems developed in an arduous, time-consuming manner by grammarians. A majority of the grammarian's efforts are devoted to the disambiguation process, first hypothesizing rules which dictate constituent categories and relationships among words in ambiguous sentences, and then seeking exceptions and corrections to these rules. In this work, I propose an automatic method for acquiring a statistical parser from a set of parsed sentences which takes advantage of some initial linguistic input, but avoids the pitfalls of the iterative and seemingly endless grammar development process. Based on distributionally-derived and linguistically-based features of language, this parser acquires a set of statistical decision trees which assign a probability distribution on the space of parse trees given the input sentence. These decision trees take advantage of significant amount of contextual information, potentially including all of the lexical information in the sentence, to produce highly accurate statistical models of the disambiguation process. By basing the disambiguation criteria selection on entropy reduction rather than human intuition, this parser development method is able to consider more sentences than a human grammarian can when making individual disambiguation rules. In experiments between a parser, acquired using this statistical framework, and a grammarian's rule-based parser, developed over a ten-year period, both using the same training material and test sentences, the decision tree parser significantly outperformed the grammar-based parser on the accuracy measure which the grammarian was trying to maximize, achieving an accuracy of 78% compared to the grammar-based parser's 69%.
Towards History-based Grammars: Using Richer Models for Probabilistic Parsing
May 03, 1994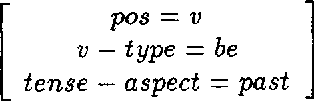
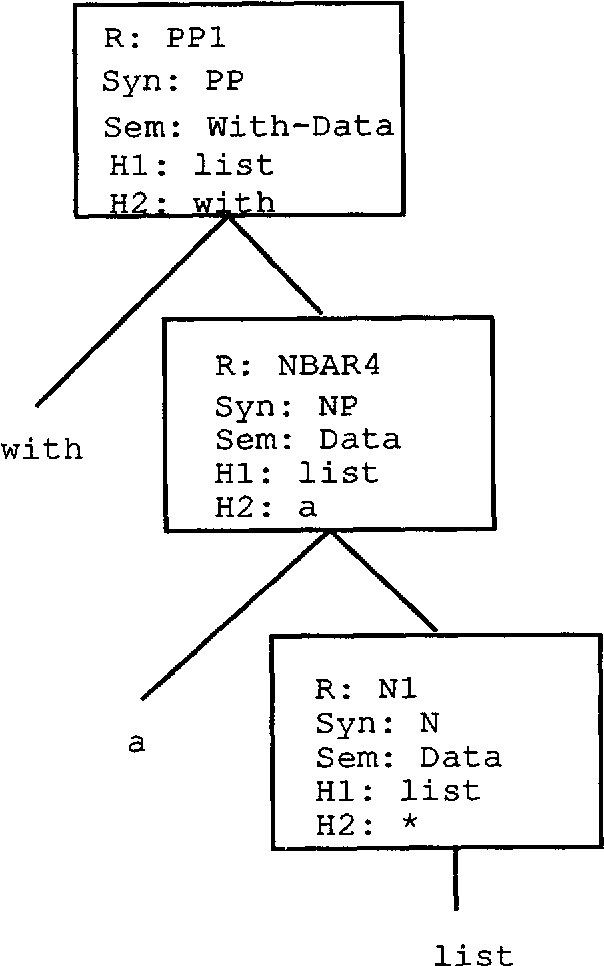
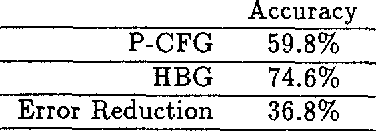
We describe a generative probabilistic model of natural language, which we call HBG, that takes advantage of detailed linguistic information to resolve ambiguity. HBG incorporates lexical, syntactic, semantic, and structural information from the parse tree into the disambiguation process in a novel way. We use a corpus of bracketed sentences, called a Treebank, in combination with decision tree building to tease out the relevant aspects of a parse tree that will determine the correct parse of a sentence. This stands in contrast to the usual approach of further grammar tailoring via the usual linguistic introspection in the hope of generating the correct parse. In head-to-head tests against one of the best existing robust probabilistic parsing models, which we call P-CFG, the HBG model significantly outperforms P-CFG, increasing the parsing accuracy rate from 60% to 75%, a 37% reduction in error.
* 6 pages
Efficiency, Robustness, and Accuracy in Picky Chart Parsing
May 03, 1994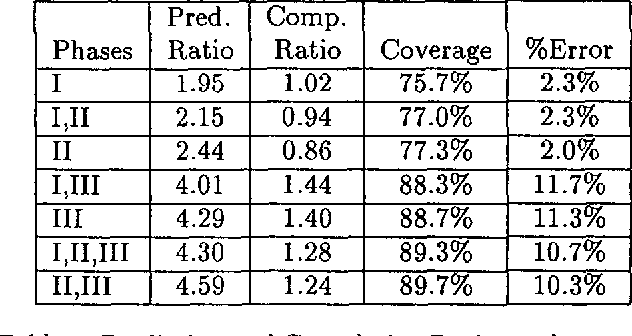
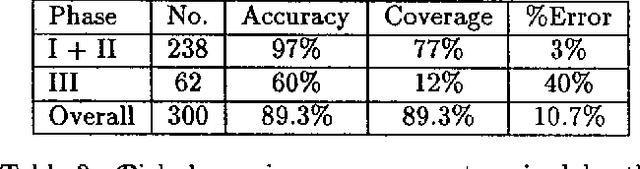
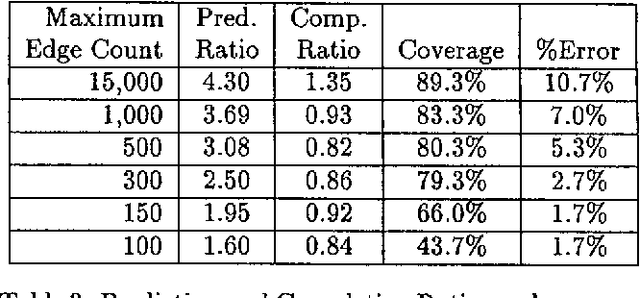
This paper describes Picky, a probabilistic agenda-based chart parsing algorithm which uses a technique called {\em probabilistic prediction} to predict which grammar rules are likely to lead to an acceptable parse of the input. Using a suboptimal search method, Picky significantly reduces the number of edges produced by CKY-like chart parsing algorithms, while maintaining the robustness of pure bottom-up parsers and the accuracy of existing probabilistic parsers. Experiments using Picky demonstrate how probabilistic modelling can impact upon the efficiency, robustness and accuracy of a parser.
* 8 pages
Pearl: A Probabilistic Chart Parser
May 03, 1994
This paper describes a natural language parsing algorithm for unrestricted text which uses a probability-based scoring function to select the "best" parse of a sentence. The parser, Pearl, is a time-asynchronous bottom-up chart parser with Earley-type top-down prediction which pursues the highest-scoring theory in the chart, where the score of a theory represents the extent to which the context of the sentence predicts that interpretation. This parser differs from previous attempts at stochastic parsers in that it uses a richer form of conditional probabilities based on context to predict likelihood. Pearl also provides a framework for incorporating the results of previous work in part-of-speech assignment, unknown word models, and other probabilistic models of linguistic features into one parsing tool, interleaving these techniques instead of using the traditional pipeline architecture. In preliminary tests, Pearl has been successful at resolving part-of-speech and word (in speech processing) ambiguity, determining categories for unknown words, and selecting correct parses first using a very loosely fitting covering grammar.
* 7 pages