 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Feedback Loops to Protect Text Simplification with Generative AI from Information Loss
May 22, 2025Understanding health information is essential in achieving and maintaining a healthy life. We focus on simplifying health information for better understanding. With the availability of generative AI, the simplification process has become efficient and of reasonable quality, however, the algorithms remove information that may be crucial for comprehension. In this study, we compare generative AI to detect missing information in simplified text, evaluate its importance, and fix the text with the missing information. We collected 50 health information texts and simplified them using gpt-4-0613. We compare five approaches to identify missing elements and regenerate the text by inserting the missing elements. These five approaches involve adding missing entities and missing words in various ways: 1) adding all the missing entities, 2) adding all missing words, 3) adding the top-3 entities ranked by gpt-4-0613, and 4, 5) serving as controls for comparison, adding randomly chosen entities. We use cosine similarity and ROUGE scores to evaluate the semantic similarity and content overlap between the original, simplified, and reconstructed simplified text. We do this for both summaries and full text. Overall, we find that adding missing entities improves the text. Adding all the missing entities resulted in better text regeneration, which was better than adding the top-ranked entities or words, or random words. Current tools can identify these entities, but are not valuable in ranking them.
Effects of Added Emphasis and Pause in Audio Delivery of Health Information
Apr 29, 2024



Health literacy is crucial to supporting good health and is a major national goal. Audio delivery of information is becoming more popular for informing oneself. In this study, we evaluate the effect of audio enhancements in the form of information emphasis and pauses with health texts of varying difficulty and we measure health information comprehension and retention. We produced audio snippets from difficult and easy text and conducted the study on Amazon Mechanical Turk (AMT). Our findings suggest that emphasis matters for both information comprehension and retention. When there is no added pause, emphasizing significant information can lower the perceived difficulty for difficult and easy texts. Comprehension is higher (54%) with correctly placed emphasis for the difficult texts compared to not adding emphasis (50%). Adding a pause lowers perceived difficulty and can improve retention but adversely affects information comprehension.
Text and Audio Simplification: Human vs. ChatGPT
Apr 29, 2024



Text and audio simplification to increase information comprehension are important in healthcare. With the introduction of ChatGPT, an evaluation of its simplification performance is needed. We provide a systematic comparison of human and ChatGPT simplified texts using fourteen metrics indicative of text difficulty. We briefly introduce our online editor where these simplification tools, including ChatGPT, are available. We scored twelve corpora using our metrics: six text, one audio, and five ChatGPT simplified corpora. We then compare these corpora with texts simplified and verified in a prior user study. Finally, a medical domain expert evaluated these texts and five, new ChatGPT simplified versions. We found that simple corpora show higher similarity with the human simplified texts. ChatGPT simplification moves metrics in the right direction. The medical domain expert evaluation showed a preference for the ChatGPT style, but the text itself was rated lower for content retention.
AutoMeTS: The Autocomplete for Medical Text Simplification
Oct 20, 2020
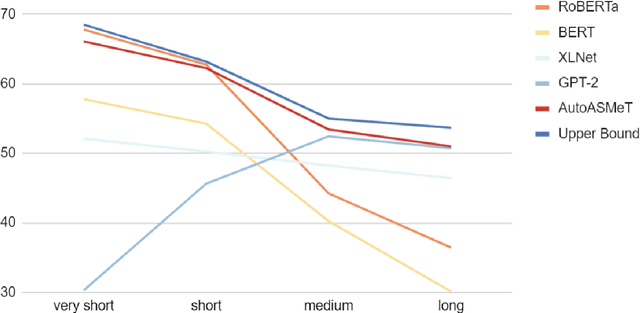
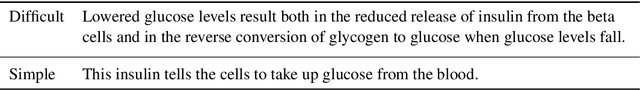
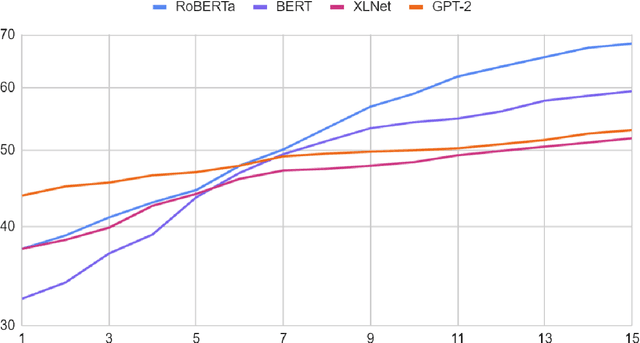
The goal of text simplification (TS) is to transform difficult text into a version that is easier to understand and more broadly accessible to a wide variety of readers. In some domains, such as healthcare, fully automated approaches cannot be used since information must be accurately preserved. Instead, semi-automated approaches can be used that assist a human writer in simplifying text faster and at a higher quality. In this paper, we examine the application of autocomplete to text simplification in the medical domain. We introduce a new parallel medical data set consisting of aligned English Wikipedia with Simple English Wikipedia sentences and examine the application of pretrained neural language models (PNLMs) on this dataset. We compare four PNLMs(BERT, RoBERTa, XLNet, and GPT-2), and show how the additional context of the sentence to be simplified can be incorporated to achieve better results (6.17% absolute improvement over the best individual model). We also introduce an ensemble model that combines the four PNLMs and outperforms the best individual model by 2.1%, resulting in an overall word prediction accuracy of 64.52%.