 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIM: Mutual Information Machine
Oct 14, 2019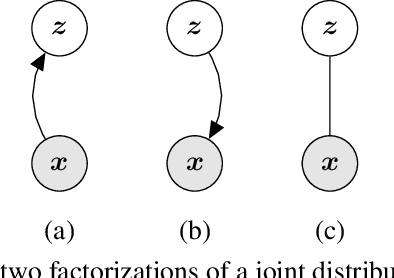
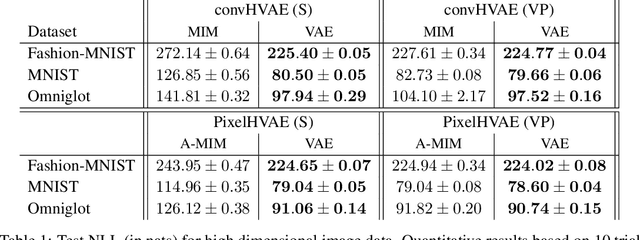
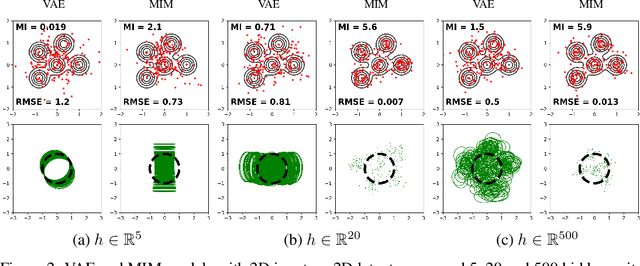

We introduce the Mutual Information Machine (MIM), an autoencoder model for learning joint distributions over observations and latent states. The model formulation reflects two key design principles: 1) symmetry, to encourage the encoder and decoder to learn consistent factorizations of the same underlying distribution; and 2) mutual information, to encourage the learning of useful representations for downstream tasks. The objective comprises the Jensen-Shannon divergence between the encoding and decoding joint distributions, plus a mutual information term. We show that this objective can be bounded by a tractable cross-entropy loss between the true model and a parameterized approximation, and relate this to maximum likelihood estimation and variational autoencoders. Experiments show that MIM is capable of learning a latent representation with high mutual information, and good unsupervised clustering, while providing data log likelihood comparable to VAE (with a sufficiently expressive architecture).
High Mutual Information in Representation Learning with Symmetric Variational Inference
Oct 04, 2019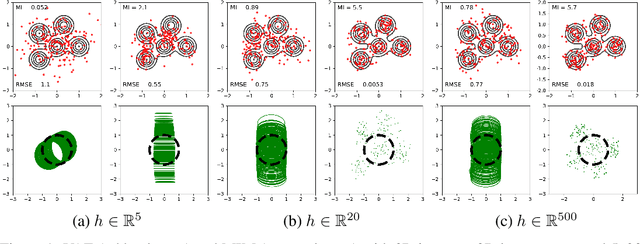

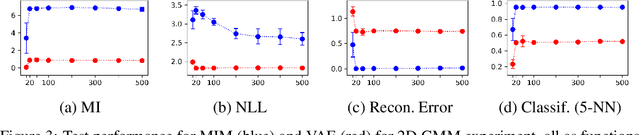

We introduce the Mutual Information Machine (MIM), a novel formulation of representation learning, using a joint distribution over the observations and latent state in an encoder/decoder framework. Our key principles are symmetry and mutual information, where symmetry encourages the encoder and decoder to learn different factorizations of the same underlying distribution, and mutual information, to encourage the learning of useful representations for downstream tasks. Our starting point is the symmetric Jensen-Shannon divergence between the encoding and decoding joint distributions, plus a mutual information encouraging regularizer. We show that this can be bounded by a tractable cross entropy loss function between the true model and a parameterized approximation, and relate this to the maximum likelihood framework. We also relate MIM to variational autoencoders (VAEs) and demonstrate that MIM is capable of learning symmetric factorizations, with high mutual information that avoids posterior collapse.
Walking on Thin Air: Environment-Free Physics-based Markerless Motion Capture
Dec 04, 2018
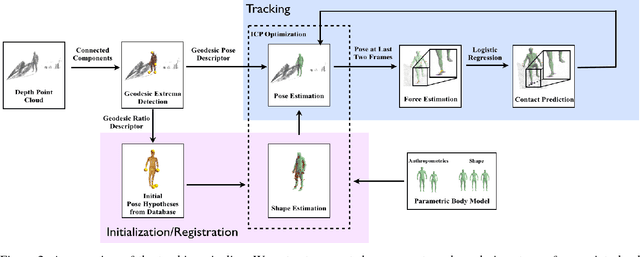
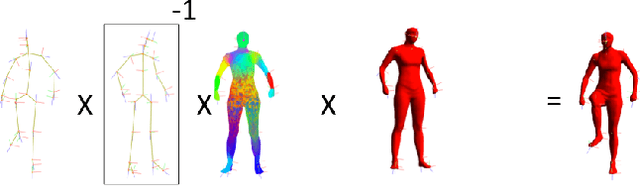

We propose a generative approach to physics-based motion capture. Unlike prior attempts to incorporate physics into tracking that assume the subject and scene geometry are calibrated and known a priori, our approach is automatic and online. This distinction is important since calibration of the environment is often difficult, especially for motions with props, uneven surfaces, or outdoor scenes. The use of physics in this context provides a natural framework to reason about contact and the plausibility of recovered motions. We propose a fast data-driven parametric body model, based on linear-blend skinning, which decouples deformations due to pose, anthropometrics and body shape. Pose (and shape) parameters are estimated using robust ICP optimization with physics-based dynamic priors that incorporate contact. Contact is estimated from torque trajectories and predictions of which contact points were active. To our knowledge, this is the first approach to take physics into account without explicit {\em a priori} knowledge of the environment or body dimensions. We demonstrate effective tracking from a noisy single depth camera, improving on state-of-the-art results quantitatively and producing better qualitative results, reducing visual artifacts like foot-skate and jitter.
TzK Flow - Conditional Generative Model
Nov 30, 2018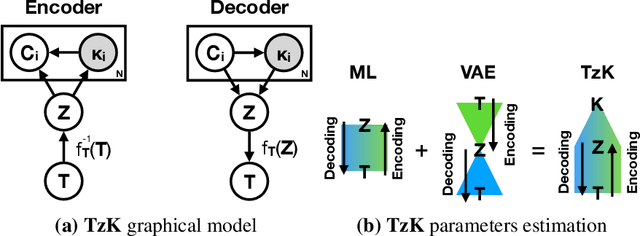
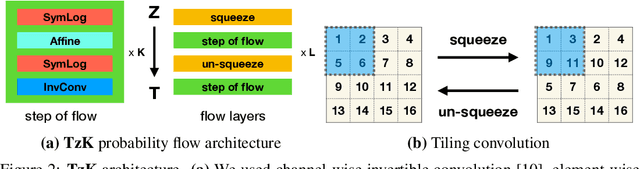


We introduce TzK (pronounced "task"), a conditional probability flow-based model that exploits attributes (e.g., style, class membership, or other side information) in order to learn tight conditional prior around manifolds of the target observations. The model is trained via approximated ML, and offers efficient approximation of arbitrary data sample distributions (similar to GAN and flow-based ML), and stable training (similar to VAE and ML), while avoiding variational approximations. TzK exploits meta-data to facilitate a bottleneck, similar to autoencoders, thereby producing a low-dimensional representation. Unlike autoencoders, the bottleneck does not limit model expressiveness, similar to flow-based ML. Supervised, unsupervised, and semi-supervised learning are supported by replacing missing observations with samples from learned priors. We demonstrate TzK by training jointly on MNIST and Omniglot datasets with minimal preprocessing, and weak supervision, with results comparable to state-of-the-art.
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
Jul 29, 2018
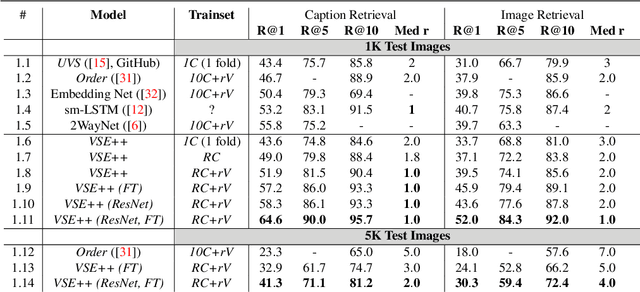
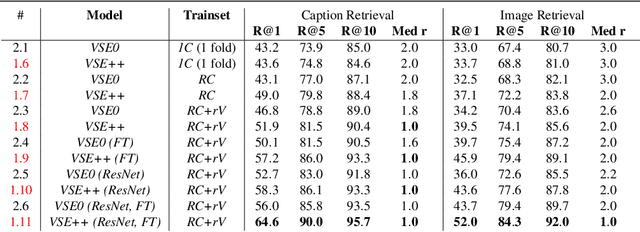
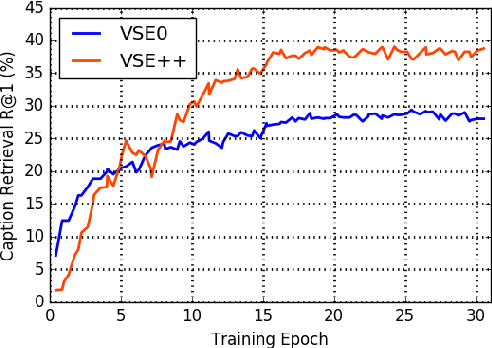
We present a new technique for learning visual-semantic embeddings for cross-modal retrieval. Inspired by hard negative mining, the use of hard negatives in structured prediction, and ranking loss functions, we introduce a simple change to common loss functions used for multi-modal embeddings. That, combined with fine-tuning and use of augmented data, yields significant gains in retrieval performance. We showcase our approach, VSE++, on MS-COCO and Flickr30K datasets, using ablation studies and comparisons with existing methods. On MS-COCO our approach outperforms state-of-the-art methods by 8.8% in caption retrieval and 11.3% in image retrieval (at R@1).
Adversarial Manipulation of Deep Representations
Mar 04, 2016


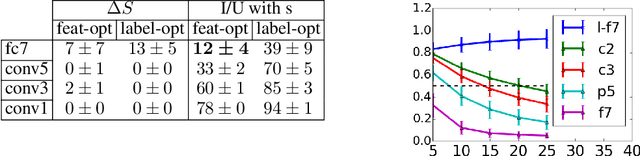
We show that the representation of an image in a deep neural network (DNN) can be manipulated to mimic those of other natural images, with only minor, imperceptible perturbations to the original image. Previous methods for generating adversarial images focused on image perturbations designed to produce erroneous class labels, while we concentrate on the internal layers of DNN representations. In this way our new class of adversarial images differs qualitatively from others. While the adversary is perceptually similar to one image, its internal representation appears remarkably similar to a different image, one from a different class, bearing little if any apparent similarity to the input; they appear generic and consistent with the space of natural images. This phenomenon raises questions about DNN representations, as well as the properties of natural images themselves.
Generalized Product of Experts for Automatic and Principled Fusion of Gaussian Process Predictions
Nov 24, 2015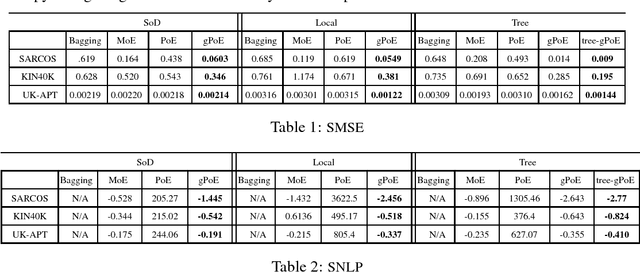
In this work, we propose a generalized product of experts (gPoE) framework for combining the predictions of multiple probabilistic models. We identify four desirable properties that are important for scalability, expressiveness and robustness, when learning and inferring with a combination of multiple models. Through analysis and experiments, we show that gPoE of Gaussian processes (GP) have these qualities, while no other existing combination schemes satisfy all of them at the same time. The resulting GP-gPoE is highly scalable as individual GP experts can be independently learned in parallel; very expressive as the way experts are combined depends on the input rather than fixed; the combined prediction is still a valid probabilistic model with natural interpretation; and finally robust to unreliable predictions from individual experts.
Transductive Log Opinion Pool of Gaussian Process Experts
Nov 24, 2015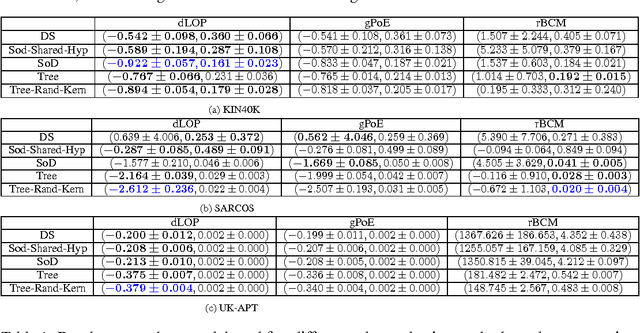
We introduce a framework for analyzing transductive combination of Gaussian process (GP) experts, where independently trained GP experts are combined in a way that depends on test point location, in order to scale GPs to big data. The framework provides some theoretical justification for the generalized product of GP experts (gPoE-GP) which was previously shown to work well in practice but lacks theoretical basis. Based on the proposed framework, an improvement over gPoE-GP is introduced and empirically validated.
Efficient non-greedy optimization of decision trees
Nov 12, 2015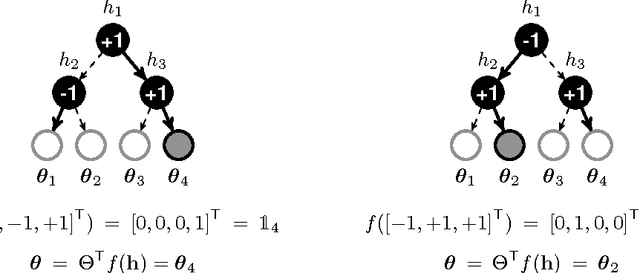
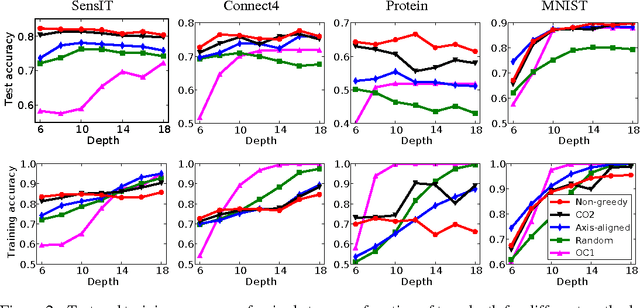
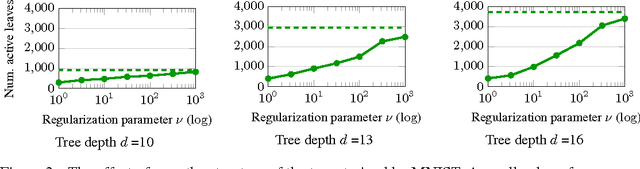
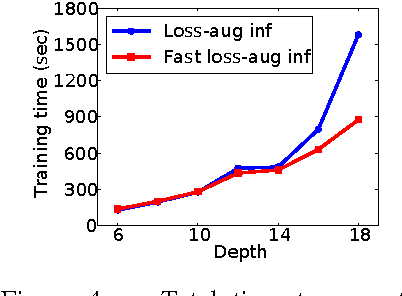
Decision trees and randomized forests are widely used in computer vision and machine learning. Standard algorithms for decision tree induction optimize the split functions one node at a time according to some splitting criteria. This greedy procedure often leads to suboptimal trees. In this paper, we present an algorithm for optimizing the split functions at all levels of the tree jointly with the leaf parameters, based on a global objective. We show that the problem of finding optimal linear-combination (oblique) splits for decision trees is related to structured prediction with latent variables, and we formulate a convex-concave upper bound on the tree's empirical loss. The run-time of computing the gradient of the proposed surrogate objective with respect to each training exemplar is quadratic in the the tree depth, and thus training deep trees is feasible. The use of stochastic gradient descent for optimization enables effective training with large datasets. Experiments on several classification benchmarks demonstrate that the resulting non-greedy decision trees outperform greedy decision tree baselines.
CO2 Forest: Improved Random Forest by Continuous Optimization of Oblique Splits
Jun 24, 2015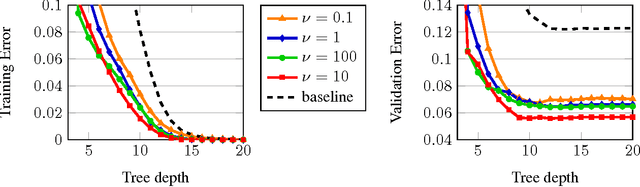
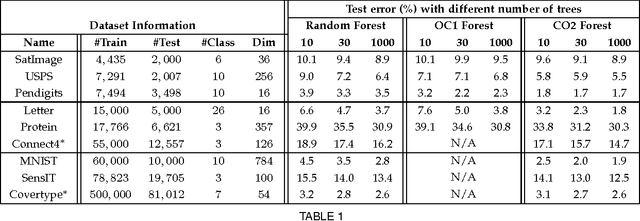
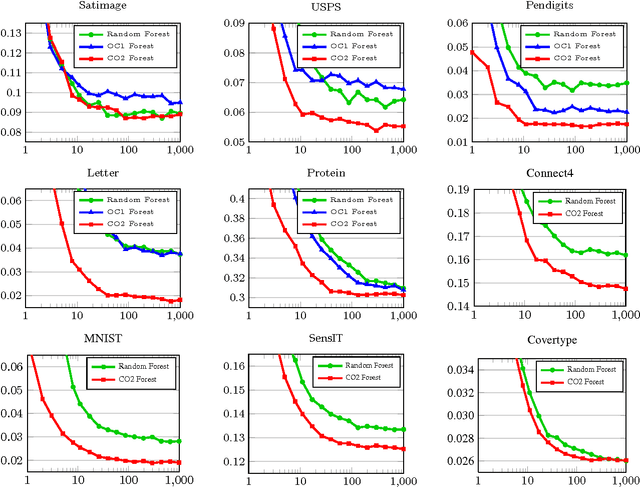

We propose a novel algorithm for optimizing multivariate linear threshold functions as split functions of decision trees to create improved Random Forest classifiers. Standard tree induction methods resort to sampling and exhaustive search to find good univariate split functions. In contrast, our method computes a linear combination of the features at each node, and optimizes the parameters of the linear combination (oblique) split functions by adopting a variant of latent variable SVM formulation. We develop a convex-concave upper bound on the classification loss for a one-level decision tree, and optimize the bound by stochastic gradient descent at each internal node of the tree. Forests of up to 1000 Continuously Optimized Oblique (CO2) decision trees are created, which significantly outperform Random Forest with univariate splits and previous techniques for constructing oblique trees. Experimental results are reported on multi-class classification benchmarks and on Labeled Faces in the Wild (LFW) dataset.