 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Supervision for Free-space Segmentation
Apr 18, 2018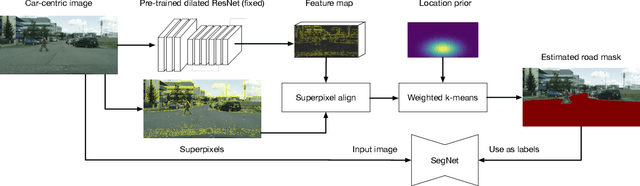

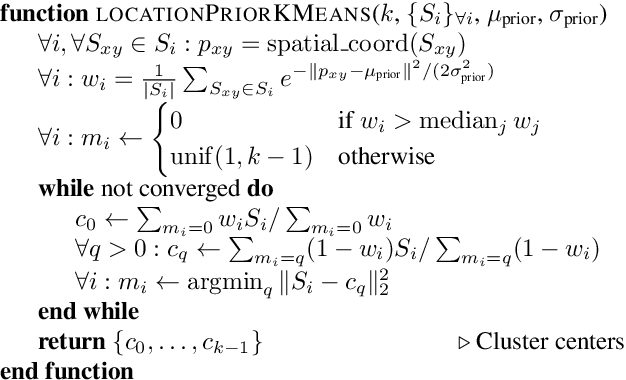

Identifying "free-space," or safely driveable regions in the scene ahead, is a fundamental task for autonomous navigation. While this task can be addressed using semantic segmentation, the manual labor involved in creating pixelwise annotations to train the segmentation model is very costly. Although weakly supervised segmentation addresses this issue, most methods are not designed for free-space. In this paper, we observe that homogeneous texture and location are two key characteristics of free-space, and develop a novel, practical framework for free-space segmentation with minimal human supervision. Our experiments show that our framework performs better than other weakly supervised methods while using less supervision. Our work demonstrates the potential for performing free-space segmentation without tedious and costly manual annotation, which will be important for adapting autonomous driving systems to different types of vehicles and environments
A Study of Cross-domain Generative Models applied to Cartoon Series
Sep 29, 2017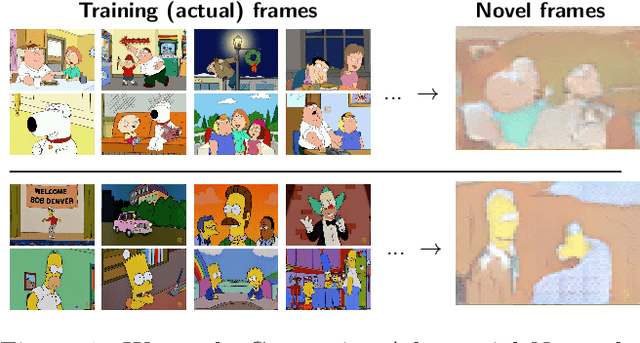
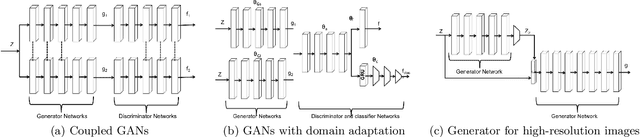


We investigate Generative Adversarial Networks (GANs) to model one particular kind of image: frames from TV cartoons. Cartoons are particularly interesting because their visual appearance emphasizes the important semantic information about a scene while abstracting out the less important details, but each cartoon series has a distinctive artistic style that performs this abstraction in different ways. We consider a dataset consisting of images from two popular television cartoon series, Family Guy and The Simpsons. We examine the ability of GANs to generate images from each of these two domains, when trained independently as well as on both domains jointly. We find that generative models may be capable of finding semantic-level correspondences between these two image domains despite the unsupervised setting, even when the training data does not give labeled alignments between them.
A Unified Model for Near and Remote Sensing
Aug 09, 2017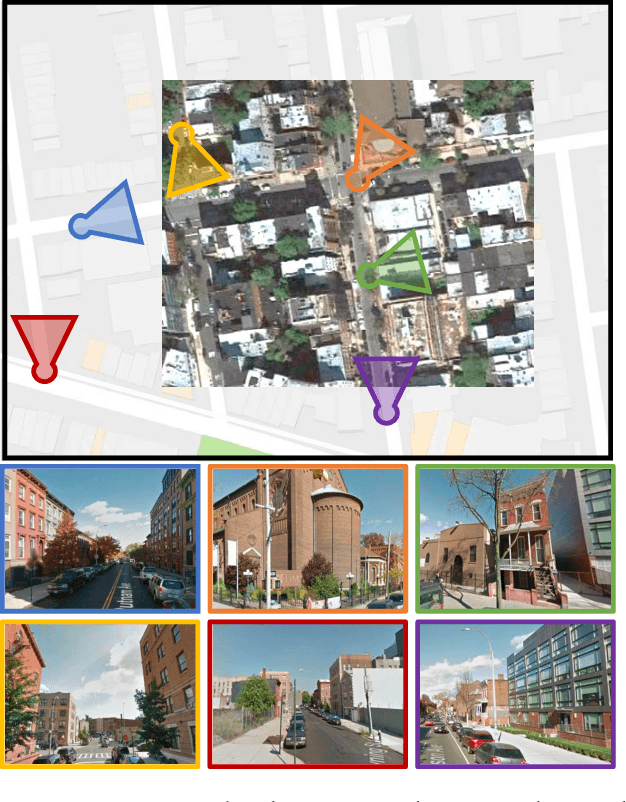
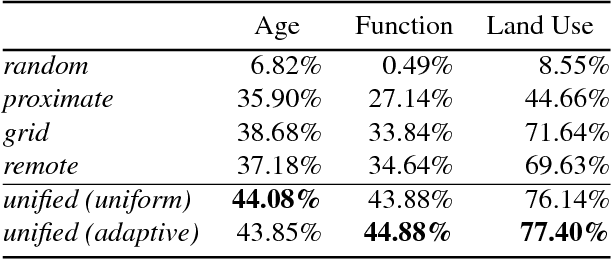

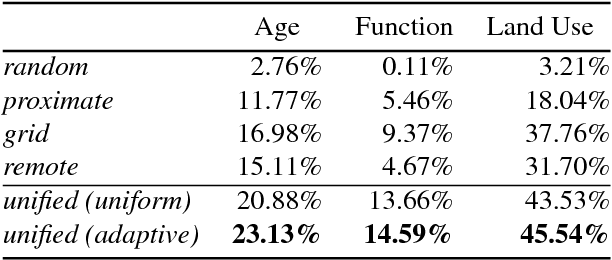
We propose a novel convolutional neural network architecture for estimating geospatial functions such as population density, land cover, or land use. In our approach, we combine overhead and ground-level images in an end-to-end trainable neural network, which uses kernel regression and density estimation to convert features extracted from the ground-level images into a dense feature map. The output of this network is a dense estimate of the geospatial function in the form of a pixel-level labeling of the overhead image. To evaluate our approach, we created a large dataset of overhead and ground-level images from a major urban area with three sets of labels: land use, building function, and building age. We find that our approach is more accurate for all tasks, in some cases dramatically so.
Identifying First-person Camera Wearers in Third-person Videos
Apr 20, 2017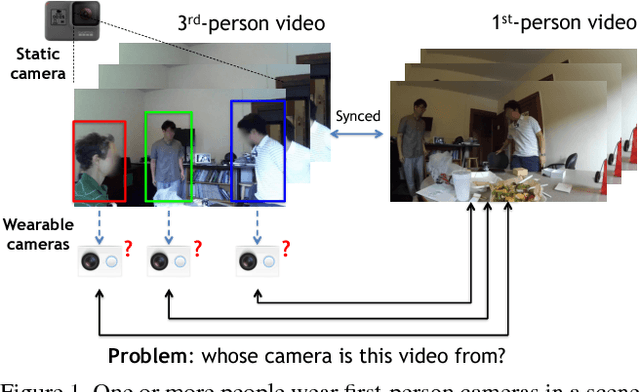
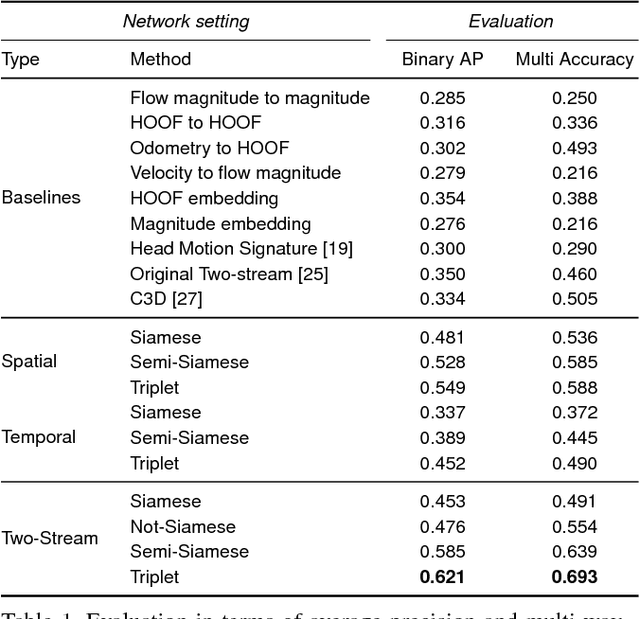
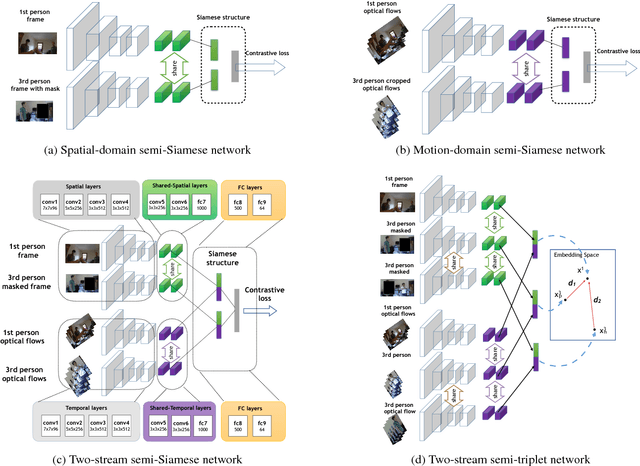
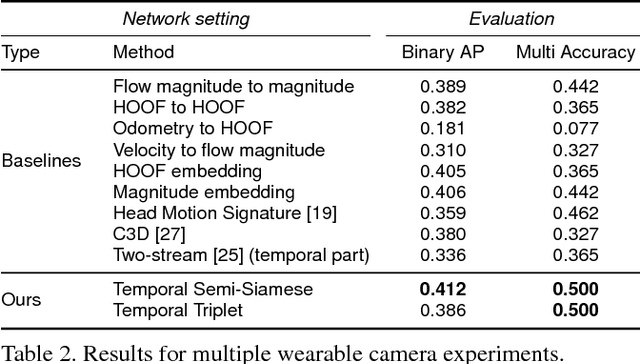
We consider scenarios in which we wish to perform joint scene understanding, object tracking, activity recognition, and other tasks in environments in which multiple people are wearing body-worn cameras while a third-person static camera also captures the scene. To do this, we need to establish person-level correspondences across first- and third-person videos, which is challenging because the camera wearer is not visible from his/her own egocentric video, preventing the use of direct feature matching. In this paper, we propose a new semi-Siamese Convolutional Neural Network architecture to address this novel challenge. We formulate the problem as learning a joint embedding space for first- and third-person videos that considers both spatial- and motion-domain cues. A new triplet loss function is designed to minimize the distance between correct first- and third-person matches while maximizing the distance between incorrect ones. This end-to-end approach performs significantly better than several baselines, in part by learning the first- and third-person features optimized for matching jointly with the distance measure itself.
DeepDiary: Automatic Caption Generation for Lifelogging Image Streams
Aug 12, 2016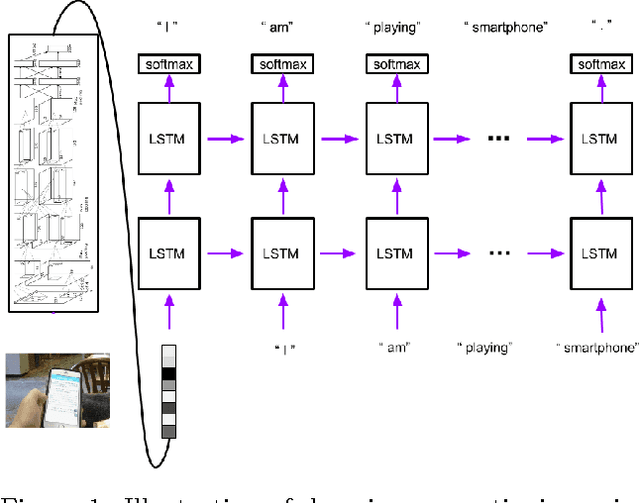
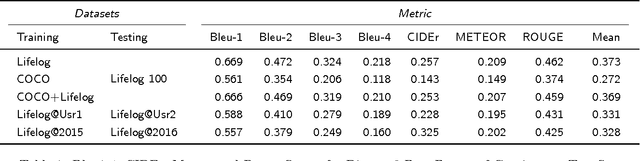

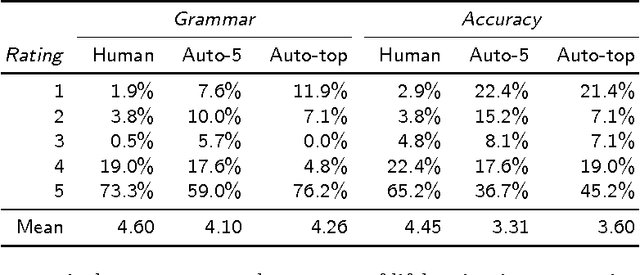
Lifelogging cameras capture everyday life from a first-person perspective, but generate so much data that it is hard for users to browse and organize their image collections effectively. In this paper, we propose to use automatic image captioning algorithms to generate textual representations of these collections. We develop and explore novel techniques based on deep learning to generate captions for both individual images and image streams, using temporal consistency constraints to create summaries that are both more compact and less noisy. We evaluate our techniques with quantitative and qualitative results, and apply captioning to an image retrieval application for finding potentially private images. Our results suggest that our automatic captioning algorithms, while imperfect, may work well enough to help users manage lifelogging photo collections.