 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Monocular Depth Estimation with Uncertainty Modeling
May 11, 2026Event cameras offer distinct advantages over conventional frame-based sensors, including microsecond-level temporal resolution, high dynamic range, and low bandwidth. In this paper, we predict per-pixel depth distributions from monocular event streams using deep neural networks. We estimate uncertainty using Gaussian, log-normal, and evidential learning frameworks. We compare six event representations: spatio-temporal voxel grids with 1, 5, 10, and 20 temporal bins, the Compact Spatio-Temporal Representation (CSTR), and Time-Ordered Recent Event (TORE) volumes. Our U-Net-based models are trained on synthetic data and then fine-tuned on real sequences. We evaluate performance using absolute relative error, root mean squared error, and the area under the sparsification error. Quantitative results show that the representations perform similarly, while 10 bin log-normal and 5 bin evidential learning perform best across metrics. Our experiments demonstrate that uncertainty estimation can be successfully integrated into event-based monocular depth estimation, and be used to indicate pixels with reliable depth.
Drone Detection Using a Low-Power Neuromorphic Virtual Tripwire
Sep 16, 2025Small drones are an increasing threat to both military personnel and civilian infrastructure, making early and automated detection crucial. In this work we develop a system that uses spiking neural networks and neuromorphic cameras (event cameras) to detect drones. The detection model is deployed on a neuromorphic chip making this a fully neuromorphic system. Multiple detection units can be deployed to create a virtual tripwire which detects when and where drones enter a restricted zone. We show that our neuromorphic solution is several orders of magnitude more energy efficient than a reference solution deployed on an edge GPU, allowing the system to run for over a year on battery power. We investigate how synthetically generated data can be used for training, and show that our model most likely relies on the shape of the drone rather than the temporal characteristics of its propellers. The small size and low power consumption allows easy deployment in contested areas or locations that lack power infrastructure.
Unpaired Thermal to Visible Spectrum Transfer using Adversarial Training
Apr 03, 2019
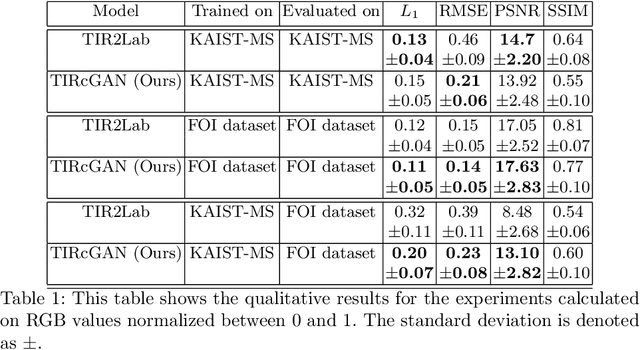
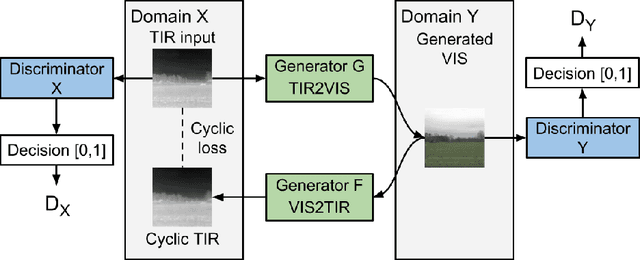

Thermal Infrared (TIR) cameras are gaining popularity in many computer vision applications due to their ability to operate under low-light conditions. Images produced by TIR cameras are usually difficult for humans to perceive visually, which limits their usability. Several methods in the literature were proposed to address this problem by transforming TIR images into realistic visible spectrum (VIS) images. However, existing TIR-VIS datasets suffer from imperfect alignment between TIR-VIS image pairs which degrades the performance of supervised methods. We tackle this problem by learning this transformation using an unsupervised Generative Adversarial Network (GAN) which trains on unpaired TIR and VIS images. When trained and evaluated on KAIST-MS dataset, our proposed methods was shown to produce significantly more realistic and sharp VIS images than the existing state-of-the-art supervised methods. In addition, our proposed method was shown to generalize very well when evaluated on a new dataset of new environments.