 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Autoencoders Using Stochastic Hessian-Free Optimization with LSMR
Apr 17, 2025

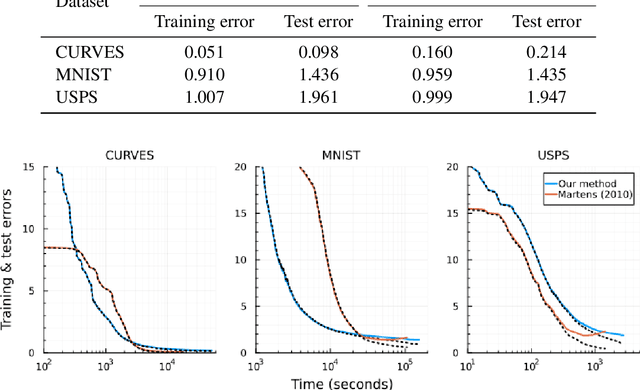
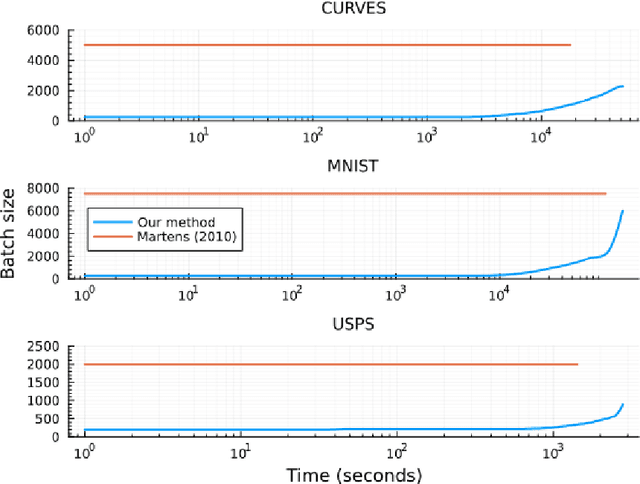
Hessian-free (HF) optimization has been shown to effectively train deep autoencoders (Martens, 2010). In this paper, we aim to accelerate HF training of autoencoders by reducing the amount of data used in training. HF utilizes the conjugate gradient algorithm to estimate update directions. Instead, we propose using the LSMR method, which is known for effectively solving large sparse linear systems. We also incorporate Chapelle & Erhan (2011)'s improved preconditioner for HF optimization. In addition, we introduce a new mini-batch selection algorithm to mitigate overfitting. Our algorithm starts with a small subset of the training data and gradually increases the mini-batch size based on (i) variance estimates obtained during the computation of a mini-batch gradient (Byrd et al., 2012) and (ii) the relative decrease in objective value for the validation data. Our experimental results demonstrate that our stochastic Hessian-free optimization, using the LSMR method and the new sample selection algorithm, leads to rapid training of deep autoencoders with improved generalization error.
gBeam-ACO: a greedy and faster variant of Beam-ACO
Apr 23, 2020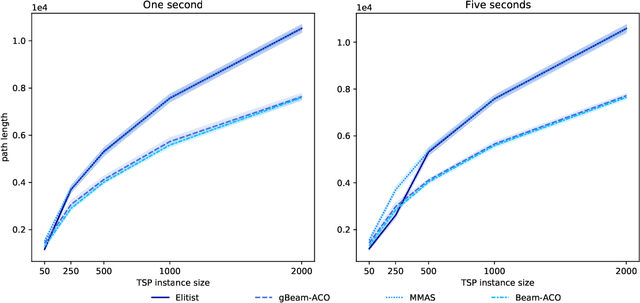

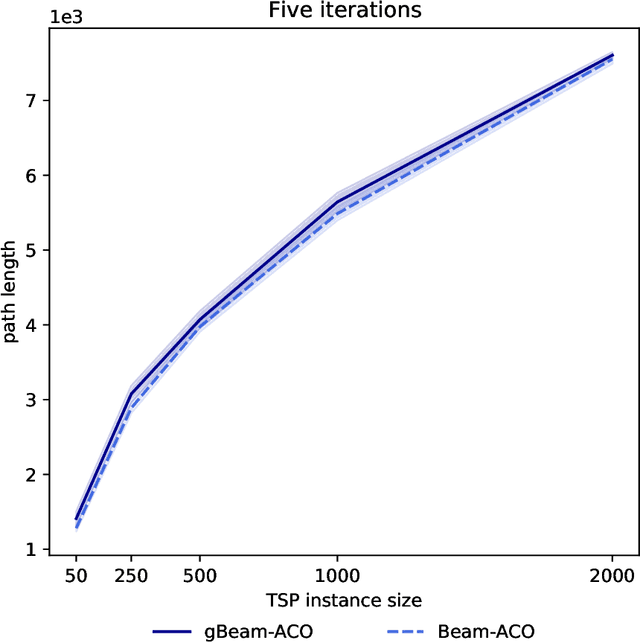
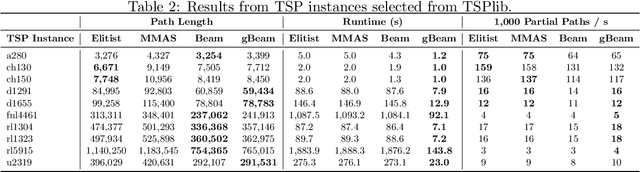
Beam-ACO, a modification of the traditional Ant Colony Optimization (ACO) algorithms that incorporates a modified beam search, is one of the most effective ACO algorithms for solving the Traveling Salesman Problem (TSP). Although adding beam search to the ACO heuristic search process is effective, it also increases the amount of work (in terms of partial paths) done by the algorithm at each step. In this work, we introduce a greedy variant of Beam-ACO that uses a greedy path selection heuristic. The exploitation of the greedy path selection is offset by the exploration required in maintaining the beam of paths. This approach has the added benefit of avoiding costly calls to a random number generator and reduces the algorithms internal state, making it simpler to parallelize. Our experiments demonstrate that not only is our greedy Beam-ACO (gBeam-ACO) faster than traditional Beam-ACO, in some cases by an order of magnitude, but it does not sacrifice quality of the found solution, especially on large TSP instances. We also found that our greedy algorithm, which we refer to as gBeam-ACO, was less dependent on hyperparameter settings.