 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATZ - An Adaptive Sentence Segmentation System
Mar 20, 1995


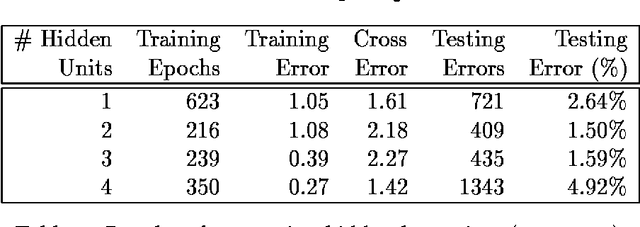
This paper provides a detailed description of the sentence segmentation system first introduced in cmp-lg/9411022. It provides results of systematic experiments involving sentence boundary determination, including context size, lexicon size, and single-case texts. Also included are the results of successfully adapting the system to German and French. The source code for the system is available as a compressed tar file at ftp://cs-tr.CS.Berkeley.EDU/pub/cstr/satz.tar.Z .
Adaptive Sentence Boundary Disambiguation
Nov 22, 1994



Labeling of sentence boundaries is a necessary prerequisite for many natural language processing tasks, including part-of-speech tagging and sentence alignment. End-of-sentence punctuation marks are ambiguous; to disambiguate them most systems use brittle, special-purpose regular expression grammars and exception rules. As an alternative, we have developed an efficient, trainable algorithm that uses a lexicon with part-of-speech probabilities and a feed-forward neural network. After training for less than one minute, the method correctly labels over 98.5\% of sentence boundaries in a corpus of over 27,000 sentence-boundary marks. We show the method to be efficient and easily adaptable to different text genres, including single-case texts.
* This is a Latex version of the previously submitted ps file (formatted as a uuencoded gz-compressed .tar file created by csh script). The software from the work described in this paper is available by contacting dpalmer@cs.berkeley.edu