 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVnCoreNLP: A Vietnamese Natural Language Processing Toolkit
Apr 01, 2018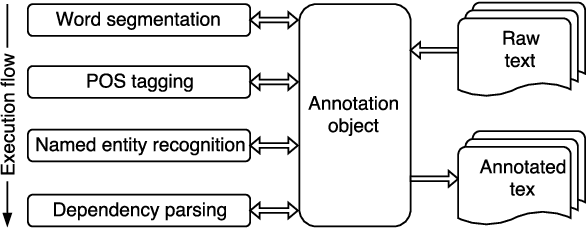
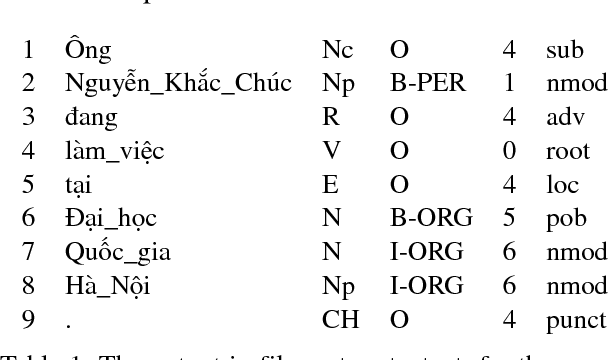
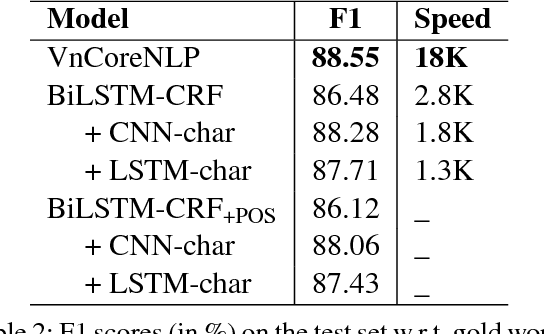
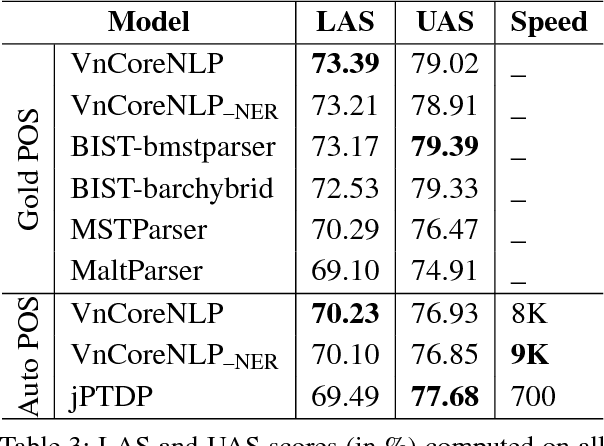
We present an easy-to-use and fast toolkit, namely VnCoreNLP---a Java NLP annotation pipeline for Vietnamese. Our VnCoreNLP supports key natural language processing (NLP) tasks including word segmentation, part-of-speech (POS) tagging, named entity recognition (NER) and dependency parsing, and obtains state-of-the-art (SOTA) results for these tasks. We release VnCoreNLP to provide rich linguistic annotations to facilitate research work on Vietnamese NLP. Our VnCoreNLP is open-source and available at: https://github.com/vncorenlp/VnCoreNLP
A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network
Mar 13, 2018
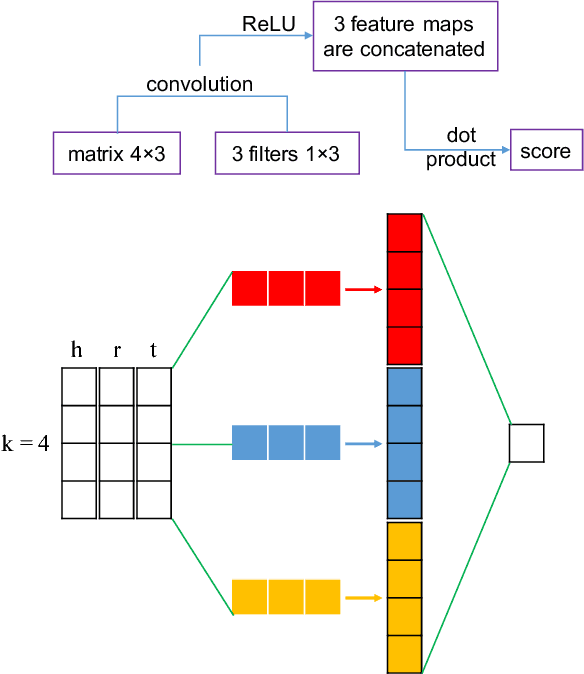
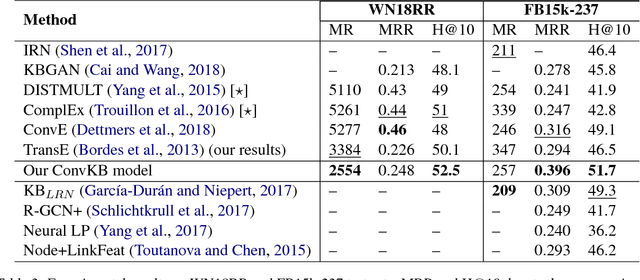
In this paper, we propose a novel embedding model, named ConvKB, for knowledge base completion. Our model ConvKB advances state-of-the-art models by employing a convolutional neural network, so that it can capture global relationships and transitional characteristics between entities and relations in knowledge bases. In ConvKB, each triple (head entity, relation, tail entity) is represented as a 3-column matrix where each column vector represents a triple element. This 3-column matrix is then fed to a convolution layer where multiple filters are operated on the matrix to generate different feature maps. These feature maps are then concatenated into a single feature vector representing the input triple. The feature vector is multiplied with a weight vector via a dot product to return a score. This score is then used to predict whether the triple is valid or not. Experiments show that ConvKB achieves better link prediction performance than previous state-of-the-art embedding models on two benchmark datasets WN18RR and FB15k-237.
An overview of embedding models of entities and relationships for knowledge base completion
Feb 03, 2018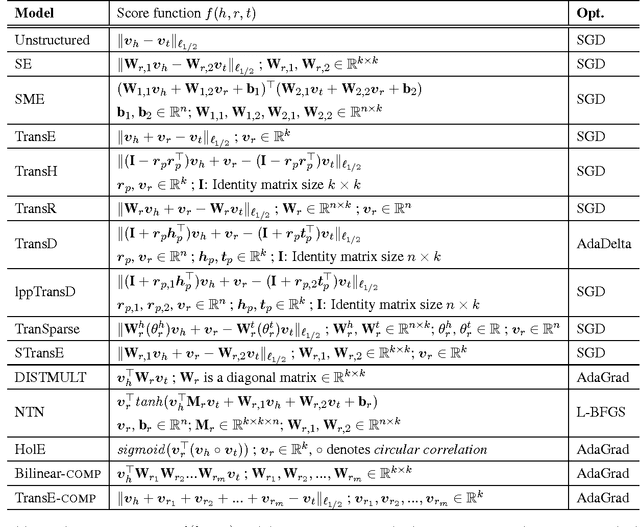
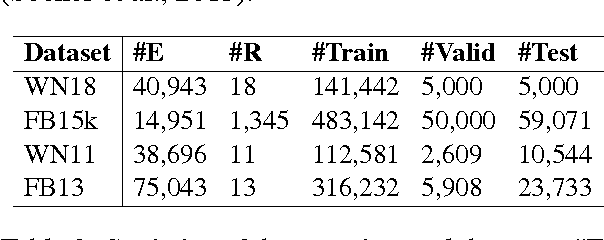
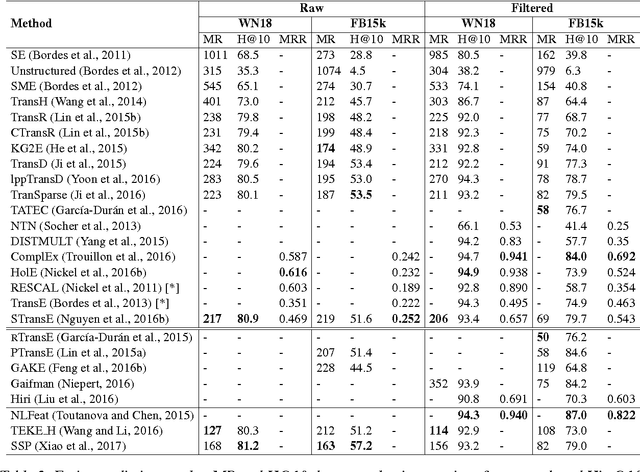
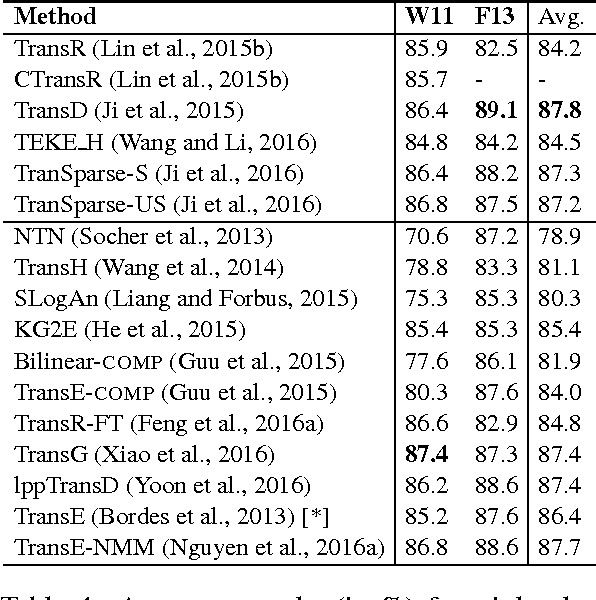
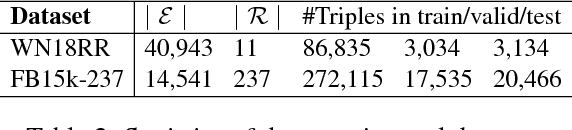
Knowledge bases (KBs) of real-world facts about entities and their relationships are useful resources for a variety of natural language processing tasks. However, because knowledge bases are typically incomplete, it is useful to be able to perform knowledge base completion or link prediction, i.e., predict whether a relationship not in the knowledge base is likely to be true. This article serves as a brief overview of embedding models of entities and relationships for knowledge base completion, summarizing up-to-date experimental results on standard benchmark datasets FB15k, WN18, FB15k-237, WN18RR, FB13 and WN11.
A Fast and Accurate Vietnamese Word Segmenter
Dec 23, 2017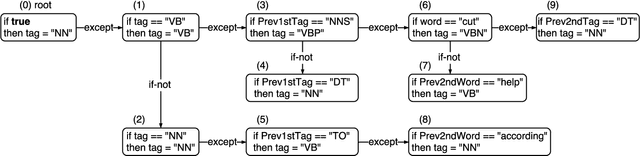

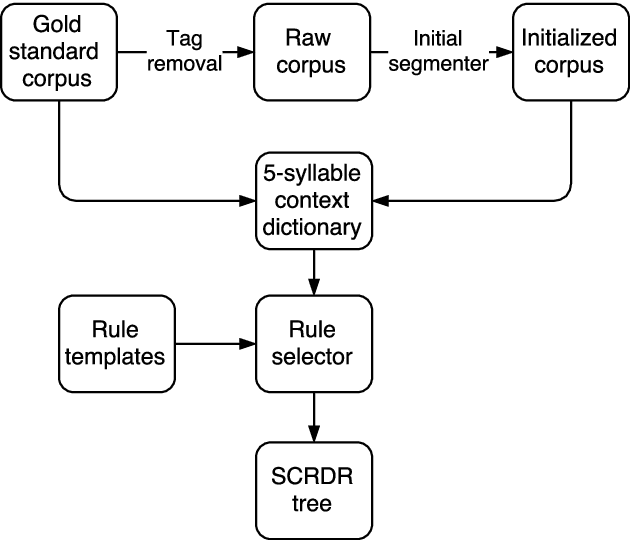

We propose a novel approach to Vietnamese word segmentation. Our approach is based on the Single Classification Ripple Down Rules methodology (Compton and Jansen, 1990), where rules are stored in an exception structure and new rules are only added to correct segmentation errors given by existing rules. Experimental results on the benchmark Vietnamese treebank show that our approach outperforms previous state-of-the-art approaches JVnSegmenter, vnTokenizer, DongDu and UETsegmenter in terms of both accuracy and performance speed. Our code is open-source and available at: https://github.com/datquocnguyen/RDRsegmenter.
From Word Segmentation to POS Tagging for Vietnamese
Nov 14, 2017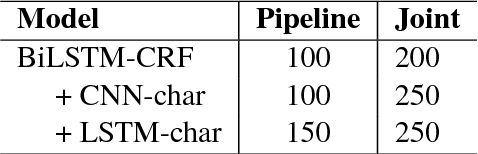
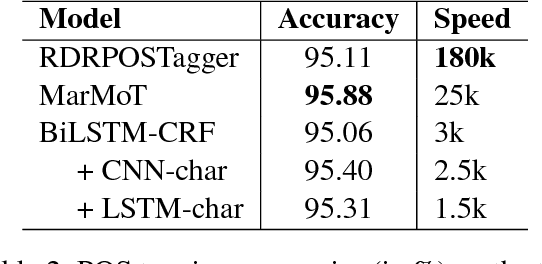
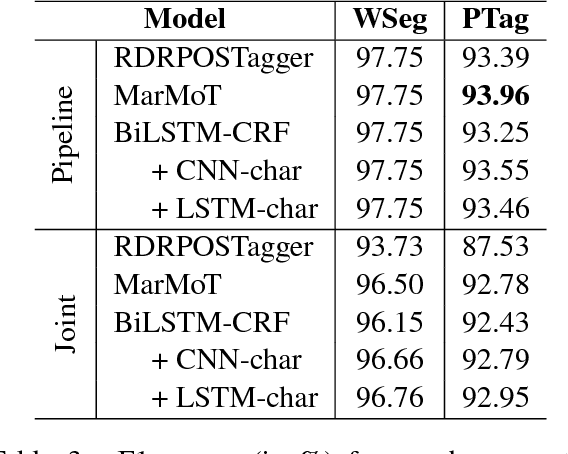
This paper presents an empirical comparison of two strategies for Vietnamese Part-of-Speech (POS) tagging from unsegmented text: (i) a pipeline strategy where we consider the output of a word segmenter as the input of a POS tagger, and (ii) a joint strategy where we predict a combined segmentation and POS tag for each syllable. We also make a comparison between state-of-the-art (SOTA) feature-based and neural network-based models. On the benchmark Vietnamese treebank (Nguyen et al., 2009), experimental results show that the pipeline strategy produces better scores of POS tagging from unsegmented text than the joint strategy, and the highest accuracy is obtained by using a feature-based model.
Sequence to Sequence Learning for Event Prediction
Sep 18, 2017
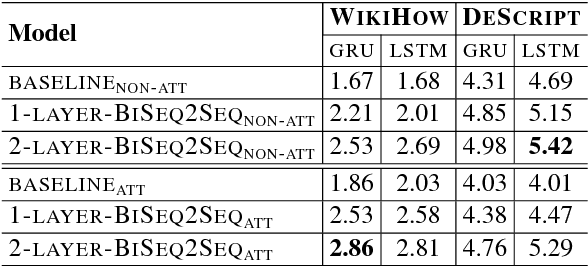
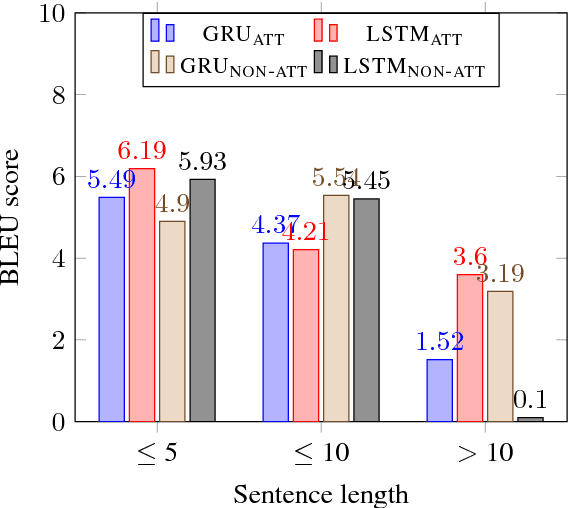

This paper presents an approach to the task of predicting an event description from a preceding sentence in a text. Our approach explores sequence-to-sequence learning using a bidirectional multi-layer recurrent neural network. Our approach substantially outperforms previous work in terms of the BLEU score on two datasets derived from WikiHow and DeScript respectively. Since the BLEU score is not easy to interpret as a measure of event prediction, we complement our study with a second evaluation that exploits the rich linguistic annotation of gold paraphrase sets of events.
A Mixture Model for Learning Multi-Sense Word Embeddings
Jun 15, 2017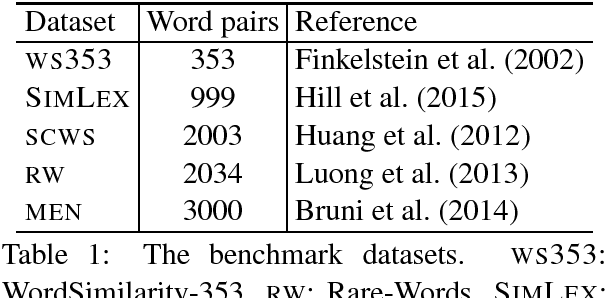
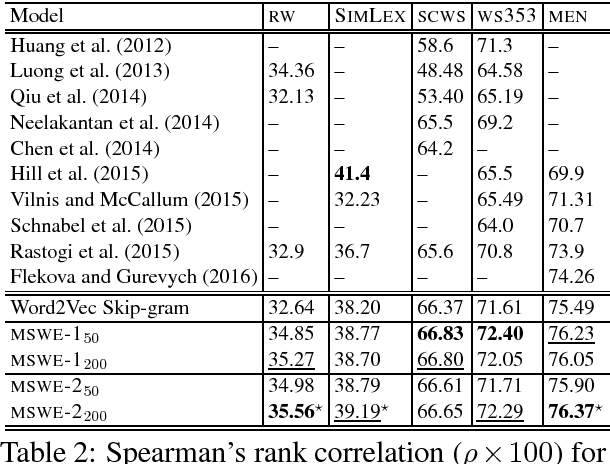
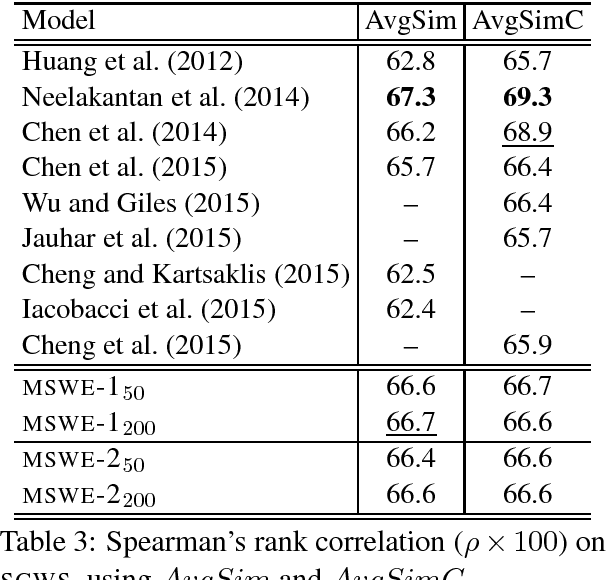
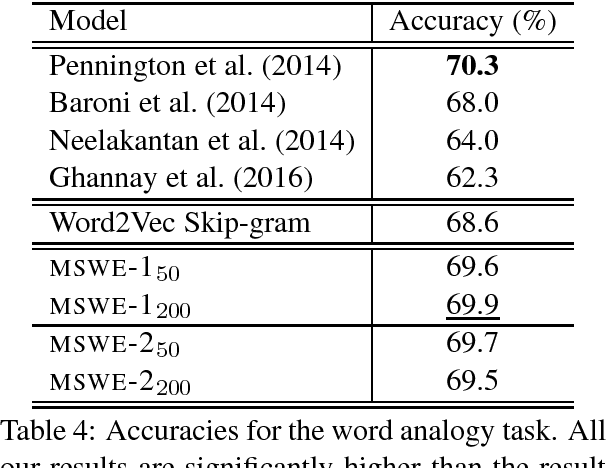
Word embeddings are now a standard technique for inducing meaning representations for words. For getting good representations, it is important to take into account different senses of a word. In this paper, we propose a mixture model for learning multi-sense word embeddings. Our model generalizes the previous works in that it allows to induce different weights of different senses of a word. The experimental results show that our model outperforms previous models on standard evaluation tasks.
A Novel Neural Network Model for Joint POS Tagging and Graph-based Dependency Parsing
Jun 08, 2017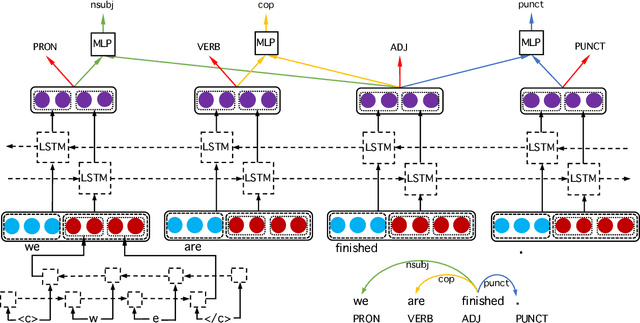

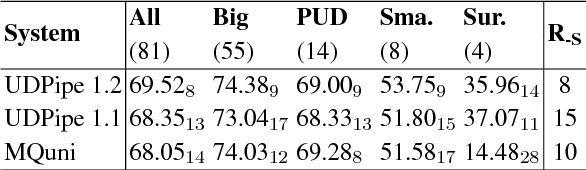
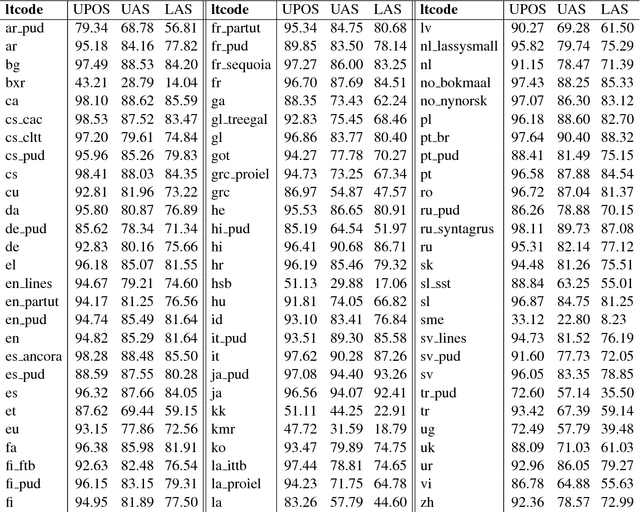
We present a novel neural network model that learns POS tagging and graph-based dependency parsing jointly. Our model uses bidirectional LSTMs to learn feature representations shared for both POS tagging and dependency parsing tasks, thus handling the feature-engineering problem. Our extensive experiments, on 19 languages from the Universal Dependencies project, show that our model outperforms the state-of-the-art neural network-based Stack-propagation model for joint POS tagging and transition-based dependency parsing, resulting in a new state of the art. Our code is open-source and available together with pre-trained models at: https://github.com/datquocnguyen/jPTDP
Neighborhood Mixture Model for Knowledge Base Completion
Mar 09, 2017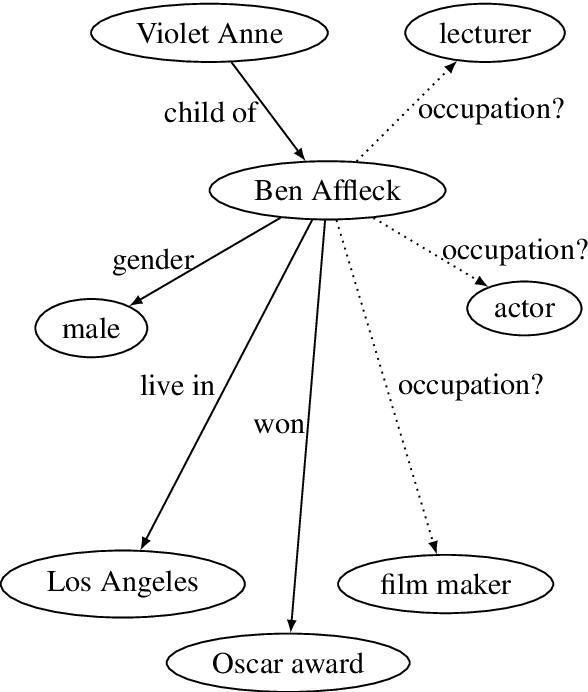

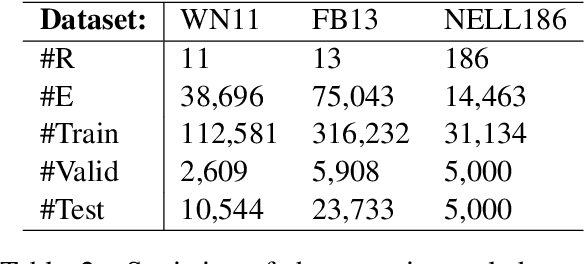
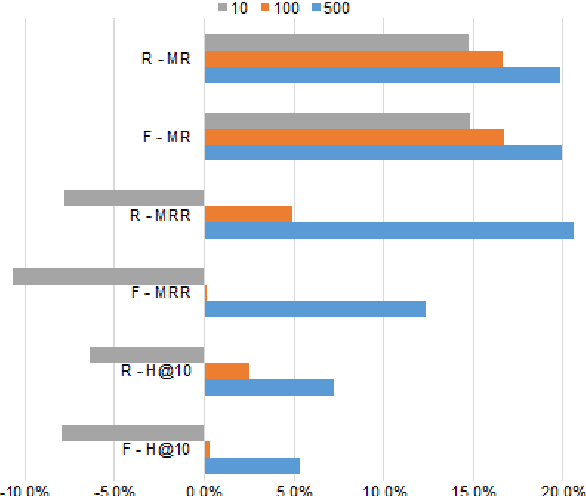
Knowledge bases are useful resources for many natural language processing tasks, however, they are far from complete. In this paper, we define a novel entity representation as a mixture of its neighborhood in the knowledge base and apply this technique on TransE-a well-known embedding model for knowledge base completion. Experimental results show that the neighborhood information significantly helps to improve the results of the TransE model, leading to better performance than obtained by other state-of-the-art embedding models on three benchmark datasets for triple classification, entity prediction and relation prediction tasks.
STransE: a novel embedding model of entities and relationships in knowledge bases
Mar 08, 2017

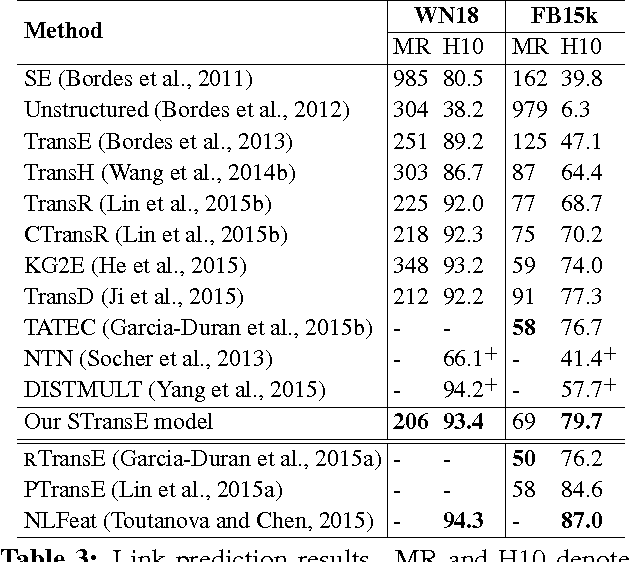
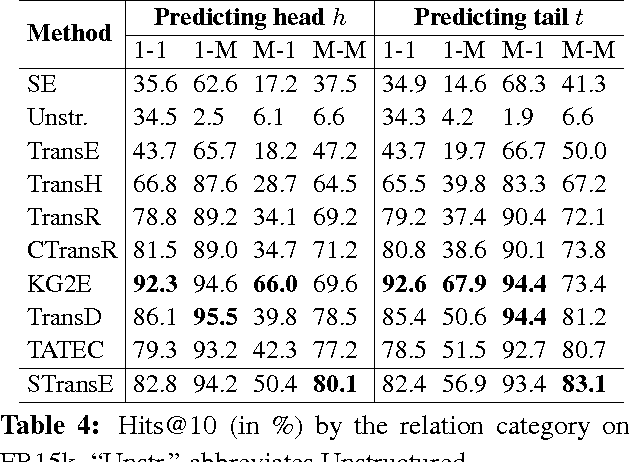
Knowledge bases of real-world facts about entities and their relationships are useful resources for a variety of natural language processing tasks. However, because knowledge bases are typically incomplete, it is useful to be able to perform link prediction or knowledge base completion, i.e., predict whether a relationship not in the knowledge base is likely to be true. This paper combines insights from several previous link prediction models into a new embedding model STransE that represents each entity as a low-dimensional vector, and each relation by two matrices and a translation vector. STransE is a simple combination of the SE and TransE models, but it obtains better link prediction performance on two benchmark datasets than previous embedding models. Thus, STransE can serve as a new baseline for the more complex models in the link prediction task.