 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA neural joint model for Vietnamese word segmentation, POS tagging and dependency parsing
Dec 30, 2018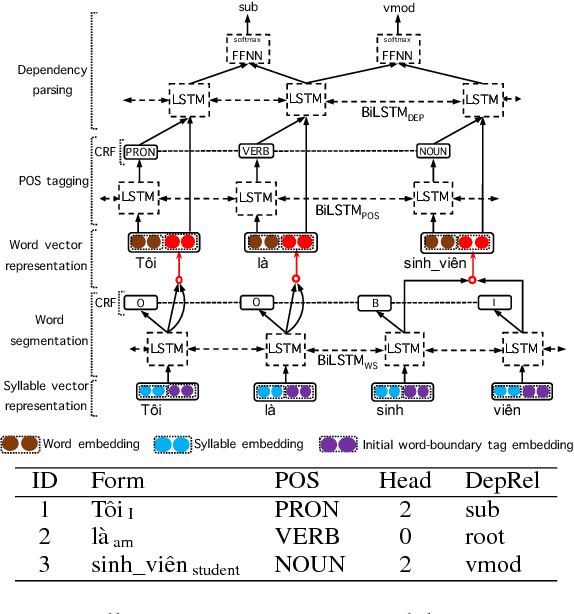
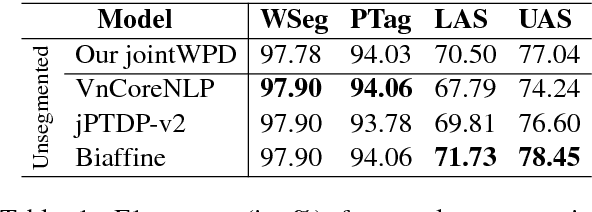
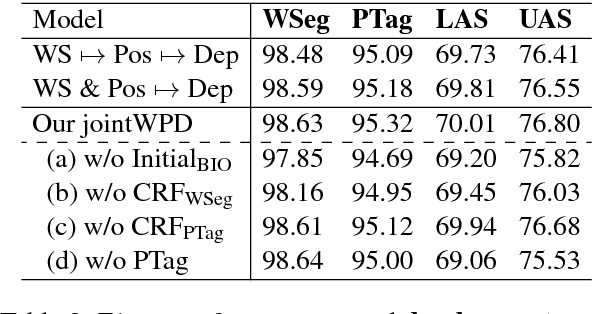
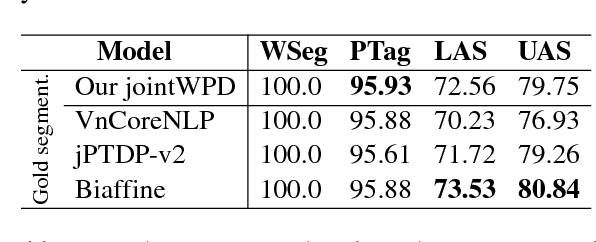
We propose the first joint model for Vietnamese word segmentation, part-of-speech (POS) tagging and dependency parsing. Our model extends the BIST graph-based dependency parser (Kiperwasser and Goldberg, 2016) with BiLSTM-CRF-based neural layers (Huang et al., 2015) for word segmentation and POS tagging. On benchmark Vietnamese datasets, experimental results show that our joint model obtains state-of-the-art or competitive performances.
End-to-end neural relation extraction using deep biaffine attention
Dec 29, 2018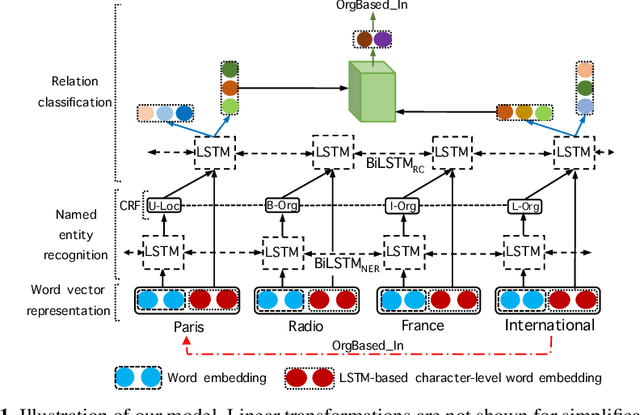
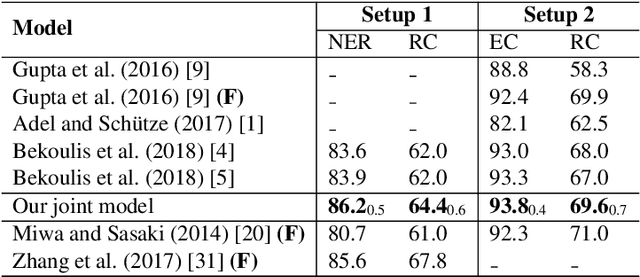
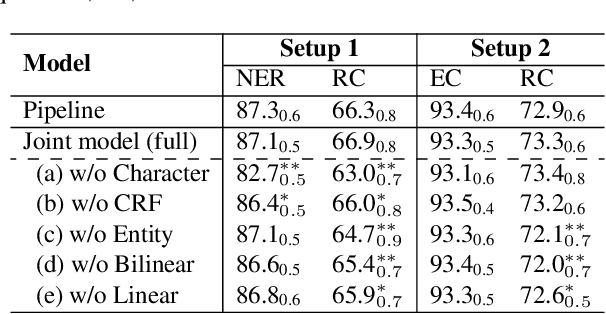
We propose a neural network model for joint extraction of named entities and relations between them, without any hand-crafted features. The key contribution of our model is to extend a BiLSTM-CRF-based entity recognition model with a deep biaffine attention layer to model second-order interactions between latent features for relation classification, specifically attending to the role of an entity in a directional relationship. On the benchmark "relation and entity recognition" dataset CoNLL04, experimental results show that our model outperforms previous models, producing new state-of-the-art performances.
Improving Topic Models with Latent Feature Word Representations
Oct 15, 2018Probabilistic topic models are widely used to discover latent topics in document collections, while latent feature vector representations of words have been used to obtain high performance in many NLP tasks. In this paper, we extend two different Dirichlet multinomial topic models by incorporating latent feature vector representations of words trained on very large corpora to improve the word-topic mapping learnt on a smaller corpus. Experimental results show that by using information from the external corpora, our new models produce significant improvements on topic coherence, document clustering and document classification tasks, especially on datasets with few or short documents.
* The published version is available at: https://transacl.org/ojs/index.php/tacl/article/view/582 ; The source code is available at: https://github.com/datquocnguyen/LFTM
Comparing CNN and LSTM character-level embeddings in BiLSTM-CRF models for chemical and disease named entity recognition
Aug 25, 2018

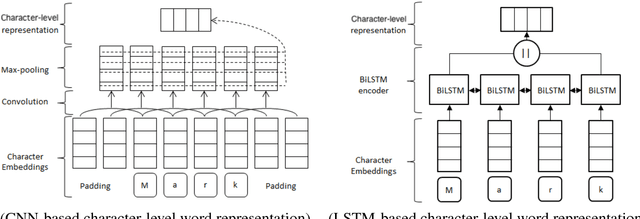
We compare the use of LSTM-based and CNN-based character-level word embeddings in BiLSTM-CRF models to approach chemical and disease named entity recognition (NER) tasks. Empirical results over the BioCreative V CDR corpus show that the use of either type of character-level word embeddings in conjunction with the BiLSTM-CRF models leads to comparable state-of-the-art performance. However, the models using CNN-based character-level word embeddings have a computational performance advantage, increasing training time over word-based models by 25% while the LSTM-based character-level word embeddings more than double the required training time.
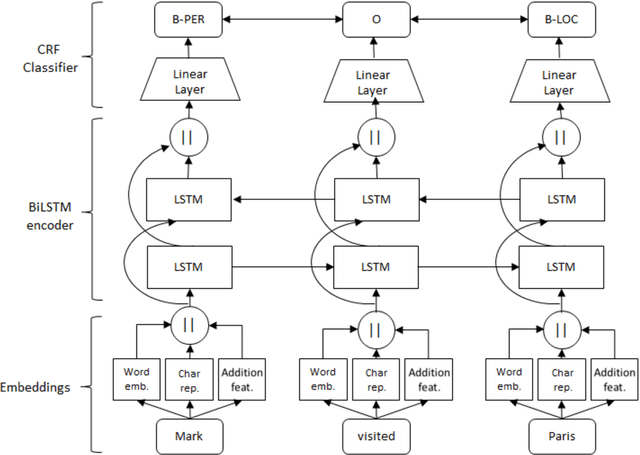
An improved neural network model for joint POS tagging and dependency parsing
Aug 20, 2018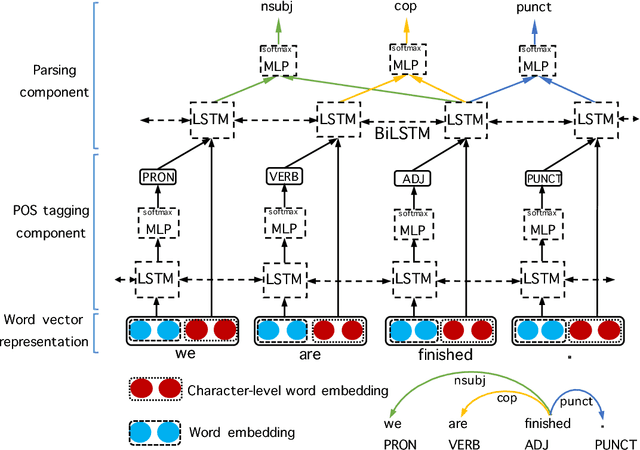
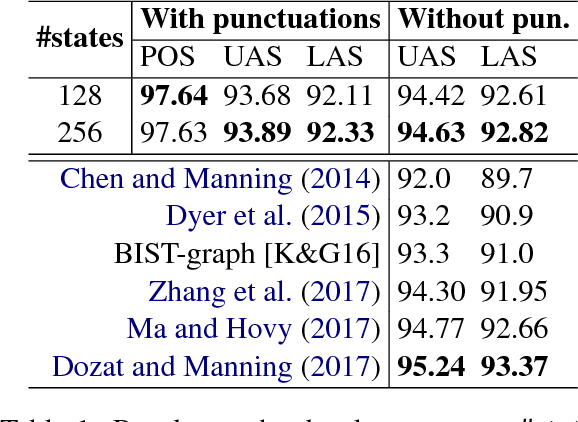
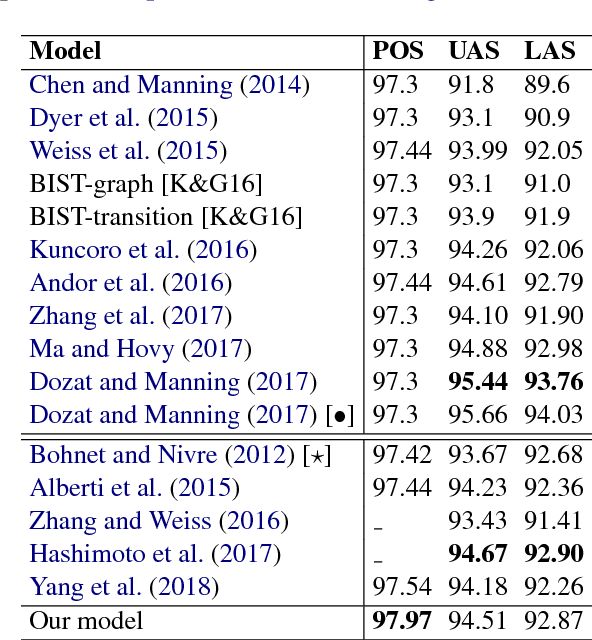
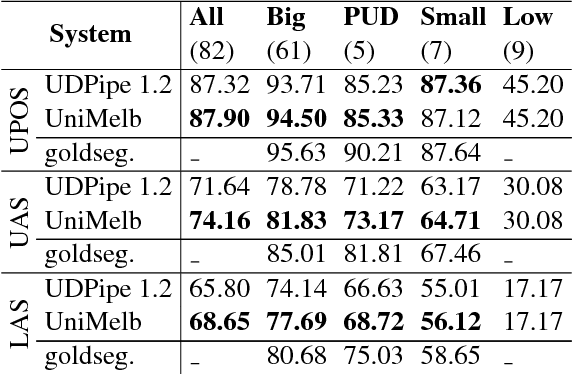
We propose a novel neural network model for joint part-of-speech (POS) tagging and dependency parsing. Our model extends the well-known BIST graph-based dependency parser (Kiperwasser and Goldberg, 2016) by incorporating a BiLSTM-based tagging component to produce automatically predicted POS tags for the parser. On the benchmark English Penn treebank, our model obtains strong UAS and LAS scores at 94.51% and 92.87%, respectively, producing 1.5+% absolute improvements to the BIST graph-based parser, and also obtaining a state-of-the-art POS tagging accuracy at 97.97%. Furthermore, experimental results on parsing 61 "big" Universal Dependencies treebanks from raw texts show that our model outperforms the baseline UDPipe (Straka and Strakov\'a, 2017) with 0.8% higher average POS tagging score and 3.6% higher average LAS score. In addition, with our model, we also obtain state-of-the-art downstream task scores for biomedical event extraction and opinion analysis applications. Our code is available together with all pre-trained models at: https://github.com/datquocnguyen/jPTDP
A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization
Aug 19, 2018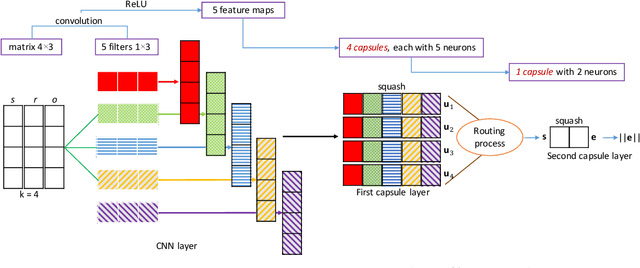
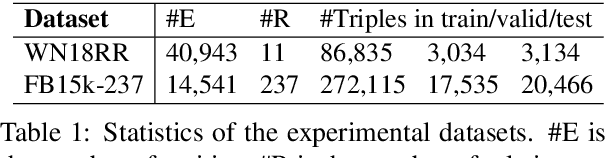
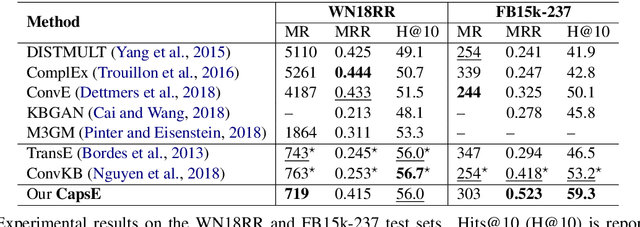
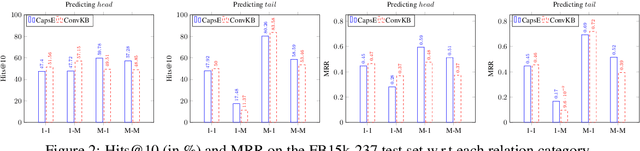
In this paper, we introduce an embedding model, named CapsE, exploring a capsule network to model relationship triples (subject, relation, object). Our CapsE represents each triple as a 3-column matrix where each column vector represents the embedding of an element in the triple. This 3-column matrix is then fed to a convolution layer where multiple filters are operated to generate different feature maps. These feature maps are used to construct capsules in the first capsule layer. Capsule layers are connected via dynamic routing mechanism. The last capsule layer consists of only one capsule to produce a vector output. The length of this vector output is used to measure the plausibility of the triple. Our proposed CapsE obtains state-of-the-art link prediction results for knowledge graph completion on two benchmark datasets: WN18RR and FB15k-237, and outperforms strong search personalization baselines on SEARCH17 dataset.
jLDADMM: A Java package for the LDA and DMM topic models
Aug 11, 2018In this technical report, we present jLDADMM---an easy-to-use Java toolkit for conventional topic models. jLDADMM is released to provide alternatives for topic modeling on normal or short texts. It provides implementations of the Latent Dirichlet Allocation topic model and the one-topic-per-document Dirichlet Multinomial Mixture model (i.e. mixture of unigrams), using collapsed Gibbs sampling. In addition, jLDADMM supplies a document clustering evaluation to compare topic models. jLDADMM is open-source and available to download at: https://github.com/datquocnguyen/jLDADMM
From POS tagging to dependency parsing for biomedical event extraction
Aug 11, 2018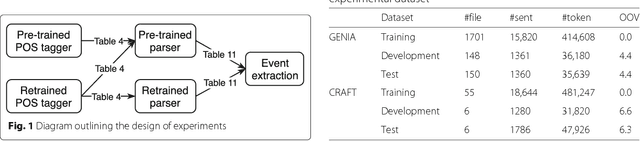
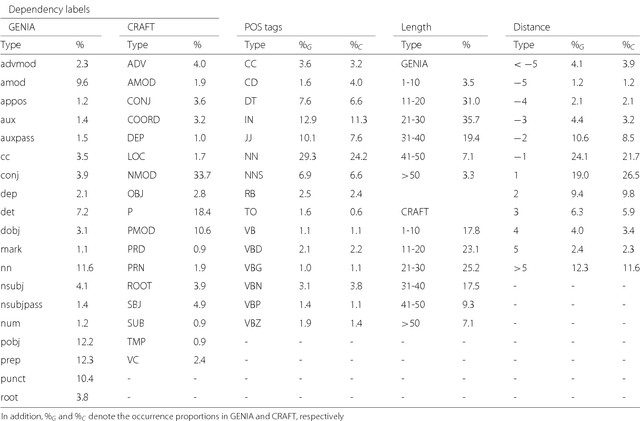
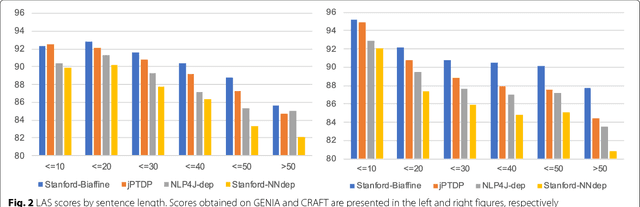
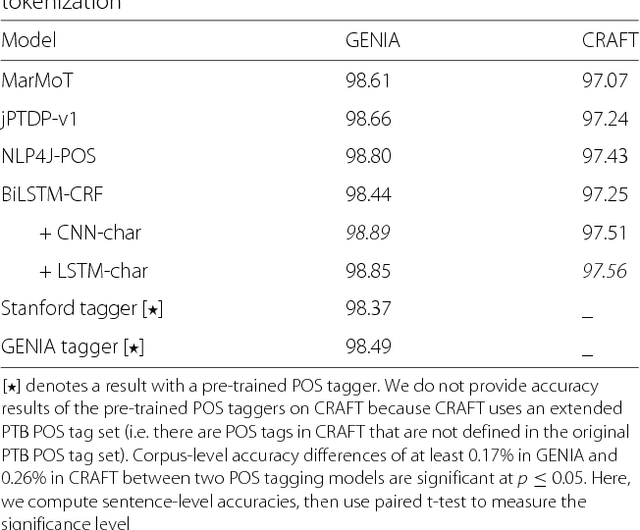
Given the importance of relation or event extraction from biomedical research publications to support knowledge capture and synthesis, and the strong dependency of approaches to this information extraction task on syntactic information, it is valuable to understand which approaches to syntactic processing of biomedical text have the highest performance. In this paper, we perform an empirical study comparing state-of-the-art traditional feature-based and neural network-based models for two core NLP tasks of POS tagging and dependency parsing on two benchmark biomedical corpora, GENIA and CRAFT. To the best of our knowledge, there is no recent work making such comparisons in the biomedical context; specifically no detailed analysis of neural models on this data is available. We also perform a task-oriented evaluation to investigate the influences of these models in a downstream application on biomedical event extraction.
Convolutional neural networks for chemical-disease relation extraction are improved with character-based word embeddings
May 27, 2018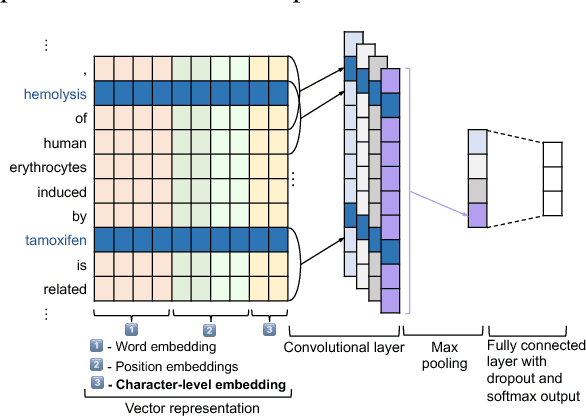
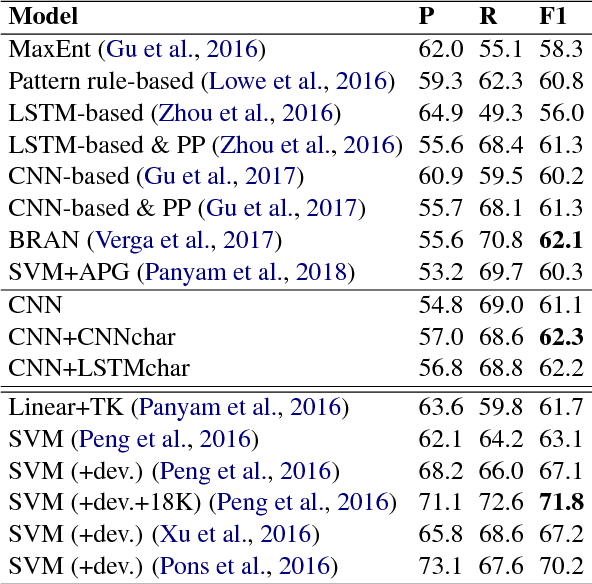
We investigate the incorporation of character-based word representations into a standard CNN-based relation extraction model. We experiment with two common neural architectures, CNN and LSTM, to learn word vector representations from character embeddings. Through a task on the BioCreative-V CDR corpus, extracting relationships between chemicals and diseases, we show that models exploiting the character-based word representations improve on models that do not use this information, obtaining state-of-the-art result relative to previous neural approaches.
NIHRIO at SemEval-2018 Task 3: A Simple and Accurate Neural Network Model for Irony Detection in Twitter
Apr 08, 2018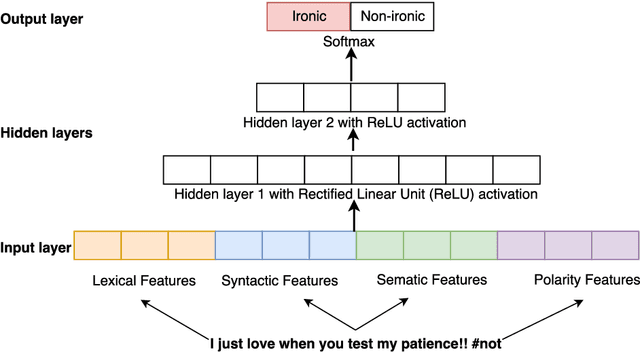
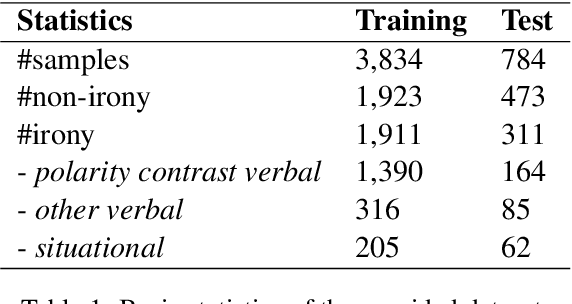
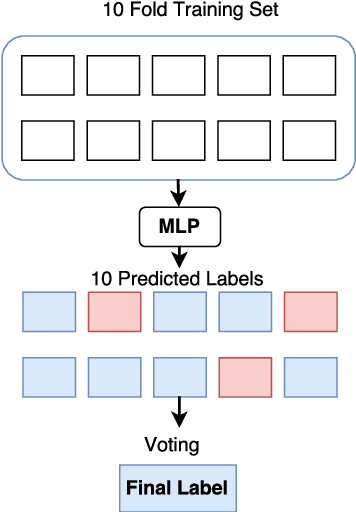
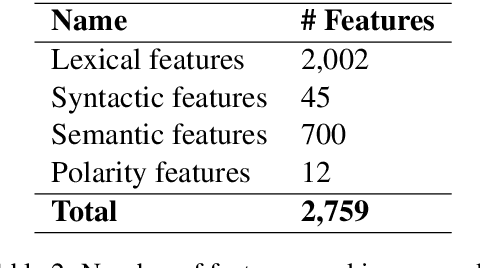
This paper describes our NIHRIO system for SemEval-2018 Task 3 "Irony detection in English tweets". We propose to use a simple neural network architecture of Multilayer Perceptron with various types of input features including: lexical, syntactic, semantic and polarity features. Our system achieves very high performance in both subtasks of binary and multi-class irony detection in tweets. In particular, we rank third using the accuracy metric and fifth using the F1 metric. Our code is available at https://github.com/NIHRIO/IronyDetectionInTwitter