 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Challenges in Fixed Point Training of Deep Convolutional Networks
Jul 08, 2016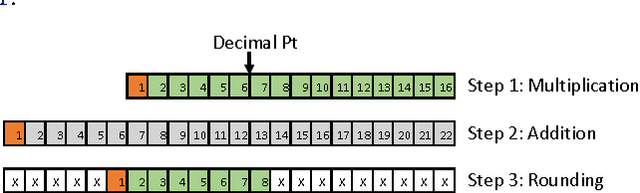
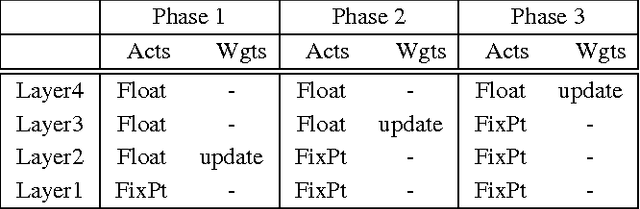
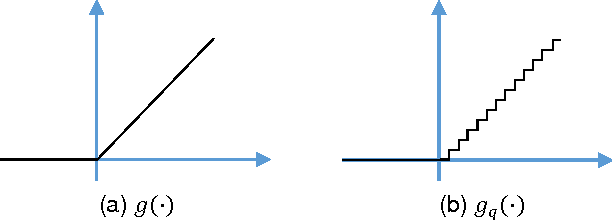
It is known that training deep neural networks, in particular, deep convolutional networks, with aggressively reduced numerical precision is challenging. The stochastic gradient descent algorithm becomes unstable in the presence of noisy gradient updates resulting from arithmetic with limited numeric precision. One of the well-accepted solutions facilitating the training of low precision fixed point networks is stochastic rounding. However, to the best of our knowledge, the source of the instability in training neural networks with noisy gradient updates has not been well investigated. This work is an attempt to draw a theoretical connection between low numerical precision and training algorithm stability. In doing so, we will also propose and verify through experiments methods that are able to improve the training performance of deep convolutional networks in fixed point.
Fixed Point Quantization of Deep Convolutional Networks
Jun 02, 2016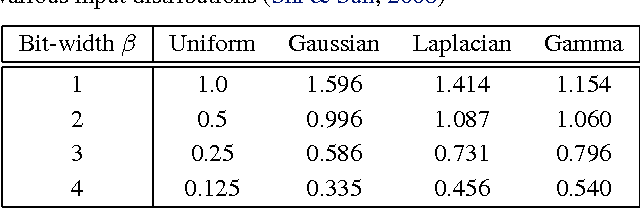
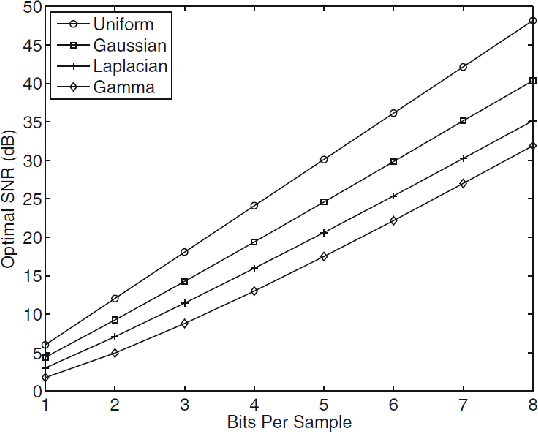

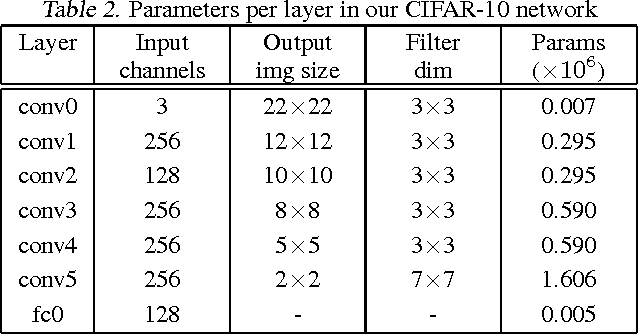
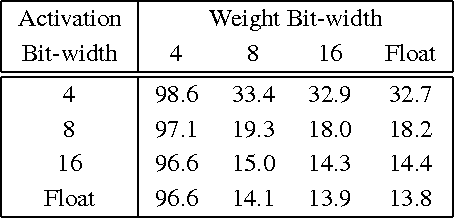
In recent years increasingly complex architectures for deep convolution networks (DCNs) have been proposed to boost the performance on image recognition tasks. However, the gains in performance have come at a cost of substantial increase in computation and model storage resources. Fixed point implementation of DCNs has the potential to alleviate some of these complexities and facilitate potential deployment on embedded hardware. In this paper, we propose a quantizer design for fixed point implementation of DCNs. We formulate and solve an optimization problem to identify optimal fixed point bit-width allocation across DCN layers. Our experiments show that in comparison to equal bit-width settings, the fixed point DCNs with optimized bit width allocation offer >20% reduction in the model size without any loss in accuracy on CIFAR-10 benchmark. We also demonstrate that fine-tuning can further enhance the accuracy of fixed point DCNs beyond that of the original floating point model. In doing so, we report a new state-of-the-art fixed point performance of 6.78% error-rate on CIFAR-10 benchmark.