 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaches to Analysing Historical Newspapers Using LLMs
Mar 27, 2026This study presents a computational analysis of the Slovene historical newspapers \textit{Slovenec} and \textit{Slovenski narod} from the sPeriodika corpus, combining topic modelling, large language model (LLM)-based aspect-level sentiment analysis, entity-graph visualisation, and qualitative discourse analysis to examine how collective identities, political orientations, and national belonging were represented in public discourse at the turn of the twentieth century. Using BERTopic, we identify major thematic patterns and show both shared concerns and clear ideological differences between the two newspapers, reflecting their conservative-Catholic and liberal-progressive orientations. We further evaluate four instruction-following LLMs for targeted sentiment classification in OCR-degraded historical Slovene and select the Slovene-adapted GaMS3-12B-Instruct model as the most suitable for large-scale application, while also documenting important limitations, particularly its stronger performance on neutral sentiment than on positive or negative sentiment. Applied at dataset scale, the model reveals meaningful variation in the portrayal of collective identities, with some groups appearing predominantly in neutral descriptive contexts and others more often in evaluative or conflict-related discourse. We then create NER graphs to explore the relationships between collective identities and places. We apply a mixed methods approach to analyse the named entity graphs, combining quantitative network analysis with critical discourse analysis. The investigation focuses on the emergence and development of intertwined historical political and socionomic identities. Overall, the study demonstrates the value of combining scalable computational methods with critical interpretation to support digital humanities research on noisy historical newspaper data.
The FRENK Datasets of Socially Unacceptable Discourse in Slovene and English
Jun 13, 2019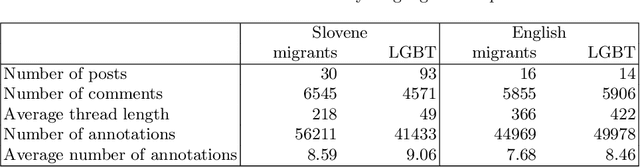
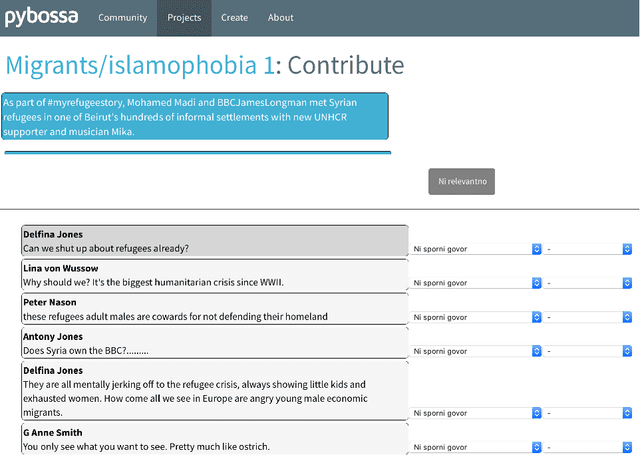
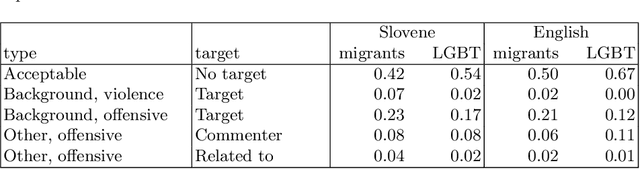

In this paper we present datasets of Facebook comment threads to mainstream media posts in Slovene and English developed inside the Slovene national project FRENK which cover two topics, migrants and LGBT, and are manually annotated for different types of socially unacceptable discourse (SUD). The main advantages of these datasets compared to the existing ones are identical sampling procedures, producing comparable data across languages and an annotation schema that takes into account six types of SUD and five targets at which SUD is directed. We describe the sampling and annotation procedures, and analyze the annotation distributions and inter-annotator agreements. We consider this dataset to be an important milestone in understanding and combating SUD for both languages.
KAS-term: Extracting Slovene Terms from Doctoral Theses via Supervised Machine Learning
Jun 05, 2019
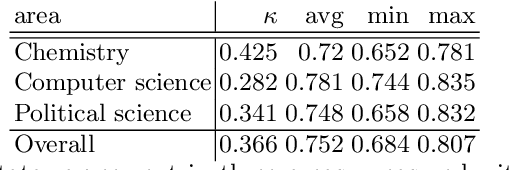
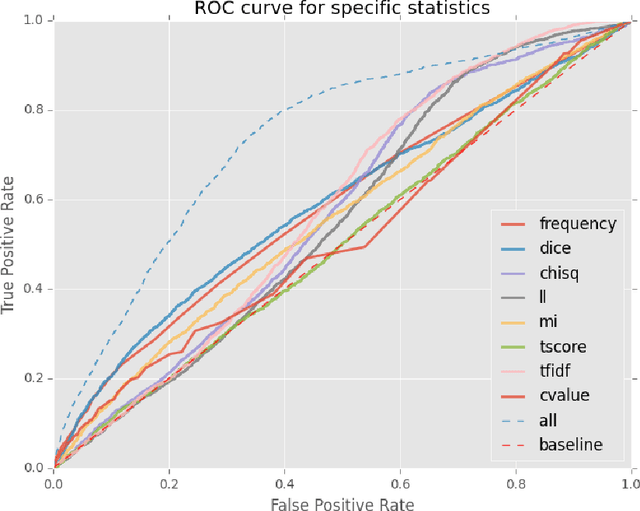
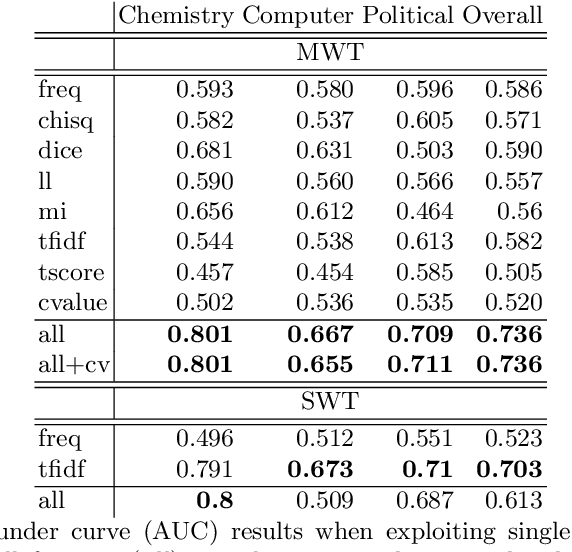
This paper presents a dataset and supervised learning experiments for term extraction from Slovene academic texts. Term candidates in the dataset were extracted via morphosyntactic patterns and annotated for their termness by four annotators. Experiments on the dataset show that most co-occurrence statistics, applied after morphosyntactic patterns and a frequency threshold, perform close to random and that the results can be significantly improved by combining, with supervised machine learning, all the seven statistic measures included in the dataset. On multi-word terms the model using all statistics obtains an AUC of 0.736 while the best single statistic produces only AUC 0.590. Among many additional candidate features, only adding multi-word morphosyntactic pattern information and length of the single-word term candidates achieves further improvements of the results.
Predicting Concreteness and Imageability of Words Within and Across Languages via Word Embeddings
Jul 09, 2018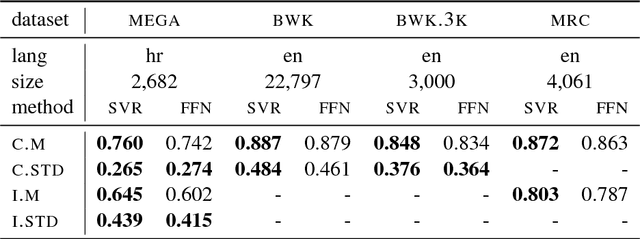

The notions of concreteness and imageability, traditionally important in psycholinguistics, are gaining significance in semantic-oriented natural language processing tasks. In this paper we investigate the predictability of these two concepts via supervised learning, using word embeddings as explanatory variables. We perform predictions both within and across languages by exploiting collections of cross-lingual embeddings aligned to a single vector space. We show that the notions of concreteness and imageability are highly predictable both within and across languages, with a moderate loss of up to 20% in correlation when predicting across languages. We further show that the cross-lingual transfer via word embeddings is more efficient than the simple transfer via bilingual dictionaries.