 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Representational Limits of Quantum-Inspired 1024-D Document Embeddings: An Experimental Evaluation Framework
Apr 10, 2026Text embeddings are central to modern information retrieval and Retrieval-Augmented Generation (RAG). While dense models derived from Large Language Models (LLMs) dominate current practice, recent work has explored quantum-inspired alternatives motivated by the geometric properties of Hilbert-like spaces and their potential to encode richer semantic structure. This paper presents an experimental framework for constructing quantum-inspired 1024-dimensional document embeddings based on overlapping windows and multi-scale aggregation. The pipeline combines semantic projections (e.g., EigAngle), circuit-inspired feature mappings, and optional teacher-student distillation, together with a fingerprinting mechanism for reproducibility and controlled evaluation. We introduce a set of diagnostic tools for hybrid retrieval, including static and dynamic interpolation between BM25 and embedding-based scores, candidate union strategies, and a conceptual alpha-oracle that provides an upper bound for score-level fusion. Experiments on controlled corpora of Italian and English documents across technical, narrative, and legal domains, using synthetic queries, show that BM25 remains a strong baseline, teacher embeddings provide stable semantic structure, and standalone quantum-inspired embeddings exhibit weak and unstable ranking signals. Distillation yields mixed effects, improving alignment in some cases but not consistently enhancing retrieval performance, while hybrid retrieval can recover competitive results when lexical and embedding-based signals are combined. Overall, the results highlight structural limitations in the geometry of quantum-inspired embeddings, including distance compression and ranking instability, and clarify their role as auxiliary components rather than standalone retrieval representations.
Bridging OLAP and RAG: A Multidimensional Approach to the Design of Corpus Partitioning
Jan 07, 2026Retrieval-Augmented Generation (RAG) systems are increasingly deployed on large-scale document collections, often comprising millions of documents and tens of millions of text chunks. In industrial-scale retrieval platforms, scalability is typically addressed through horizontal sharding and a combination of Approximate Nearest-Neighbor search, hybrid indexing, and optimized metadata filtering. Although effective from an efficiency perspective, these mechanisms rely on bottom-up, similarity-driven organization and lack a conceptual rationale for corpus partitioning. In this paper, we claim that the design of large-scale RAG systems may benefit from the combination of two orthogonal strategies: semantic clustering, which optimizes locality in embedding space, and multidimensional partitioning, which governs where retrieval should occur based on conceptual dimensions such as time and organizational context. Although such dimensions are already implicitly present in current systems, they are used in an ad hoc and poorly structured manner. We propose the Dimensional Fact Model (DFM) as a conceptual framework to guide the design of multidimensional partitions for RAG corpora. The DFM provides a principled way to reason about facts, dimensions, hierarchies, and granularity in retrieval-oriented settings. This framework naturally supports hierarchical routing and controlled fallback strategies, ensuring that retrieval remains robust even in the presence of incomplete metadata, while transforming the search process from a 'black-box' similarity matching into a governable and deterministic workflow. This work is intended as a position paper; its goal is to bridge the gap between OLAP-style multidimensional modeling and modern RAG architectures, and to stimulate further research on principled, explainable, and governable retrieval strategies at scale.
Template co-updating in multi-modal human activity recognition systems
Dec 04, 2019
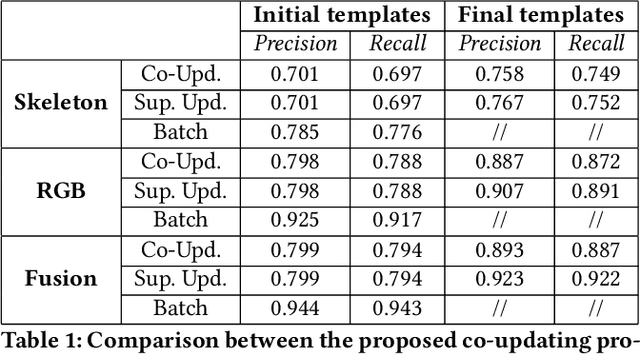
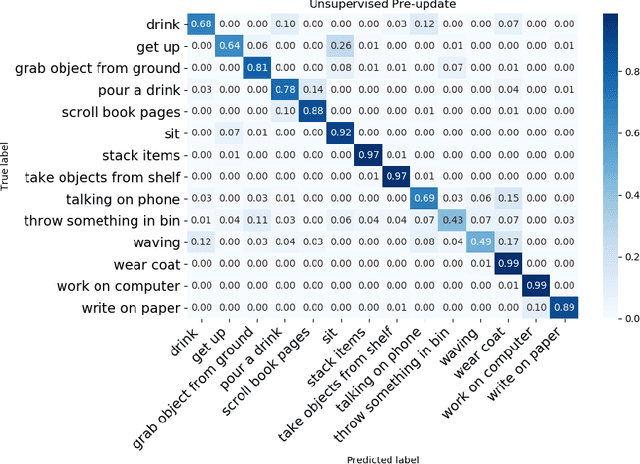
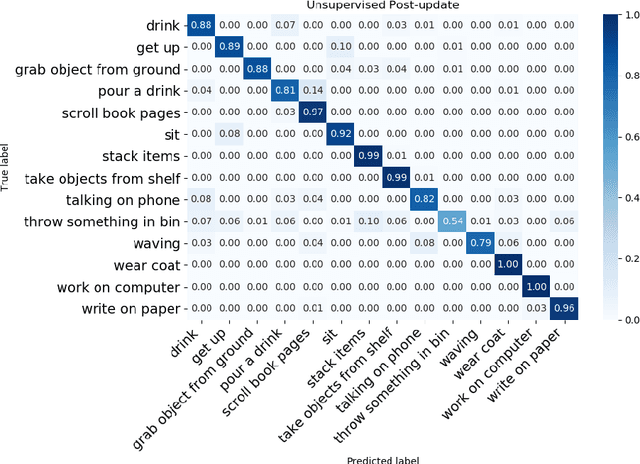
Multi-modal systems are quite common in the context of human activity recognition; widely used RGB-D sensors (Kinect is the most prominent example) give access to parallel data streams, typically RGB images, depth data, skeleton information. The richness of multimodal information has been largely exploited in many works in the literature, while an analysis of their effectiveness for incremental template updating has not been investigated so far. This paper is aimed at defining a general framework for unsupervised template updating in multi-modal systems, where the different data sources can provide complementary information, increasing the effectiveness of the updating procedure and reducing at the same time the probability of incorrect template modifications.