 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continuum of Generation Tasks for Investigating Length Bias and Degenerate Repetition
Oct 19, 2022
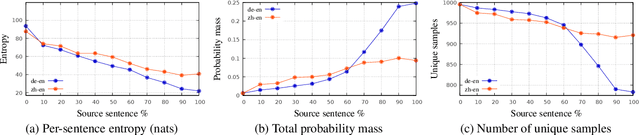
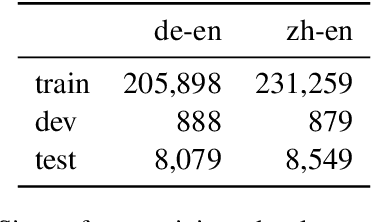
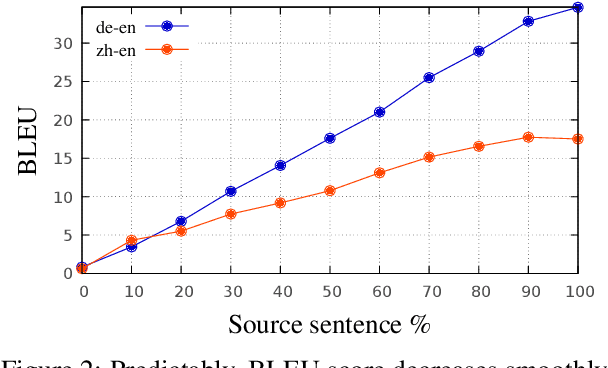
Language models suffer from various degenerate behaviors. These differ between tasks: machine translation (MT) exhibits length bias, while tasks like story generation exhibit excessive repetition. Recent work has attributed the difference to task constrainedness, but evidence for this claim has always involved many confounding variables. To study this question directly, we introduce a new experimental framework that allows us to smoothly vary task constrainedness, from MT at one end to fully open-ended generation at the other, while keeping all other aspects fixed. We find that: (1) repetition decreases smoothly with constrainedness, explaining the difference in repetition across tasks; (2) length bias surprisingly also decreases with constrainedness, suggesting some other cause for the difference in length bias; (3) across the board, these problems affect the mode, not the whole distribution; (4) the differences cannot be attributed to a change in the entropy of the distribution, since another method of changing the entropy, label smoothing, does not produce the same effect.
Factor Graph Grammars
Oct 22, 2020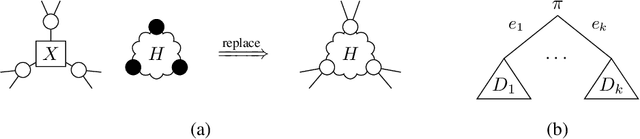
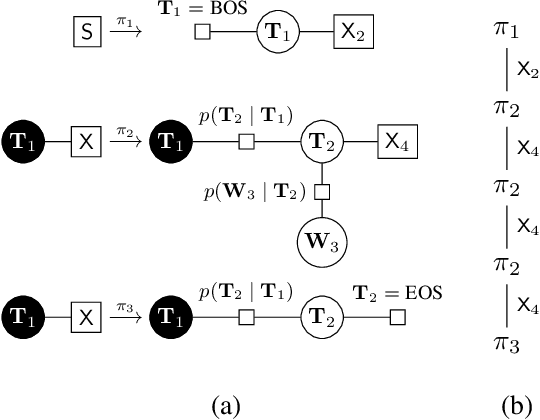
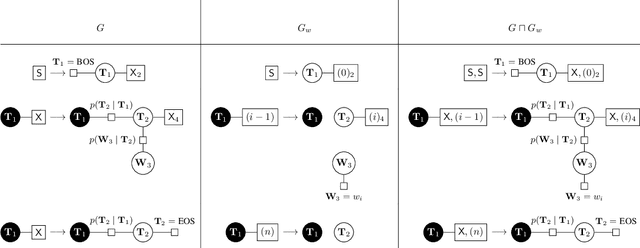
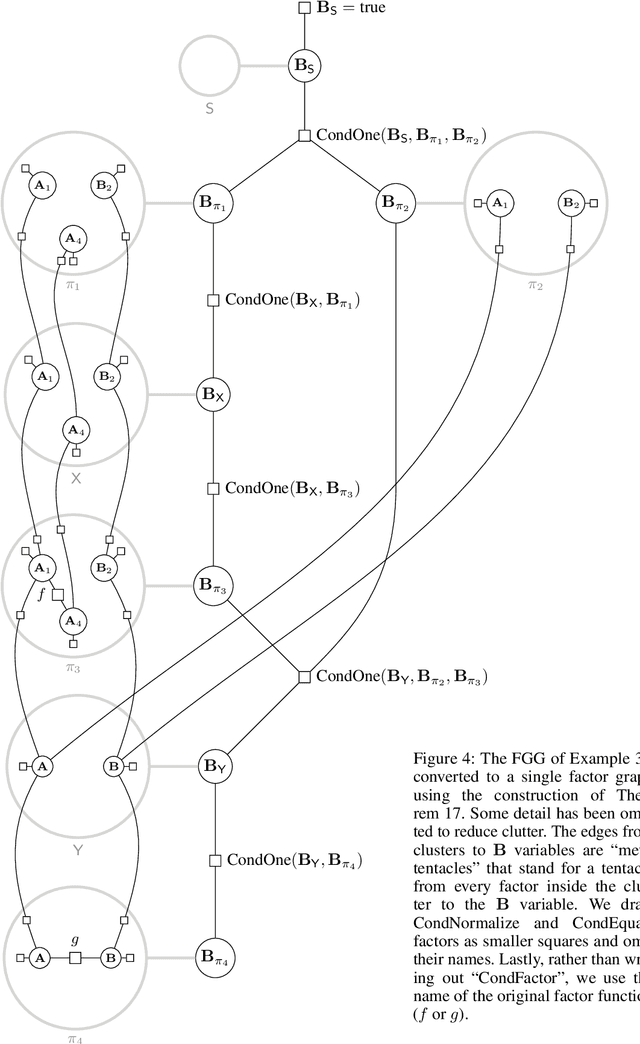
We propose the use of hyperedge replacement graph grammars for factor graphs, or factor graph grammars (FGGs) for short. FGGs generate sets of factor graphs and can describe a more general class of models than plate notation, dynamic graphical models, case-factor diagrams, and sum-product networks can. Moreover, inference can be done on FGGs without enumerating all the generated factor graphs. For finite variable domains (but possibly infinite sets of graphs), a generalization of variable elimination to FGGs allows exact and tractable inference in many situations. For finite sets of graphs (but possibly infinite variable domains), a FGG can be converted to a single factor graph amenable to standard inference techniques.