 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoostLLM: Boosting-inspired LLM Fine-tuning for Few-shot Tabular Classification
May 07, 2026Large language models (LLMs) have recently been adapted to tabular prediction by serializing structured features into natural language, but their performance in low-data regimes remains limited compared to gradient-boosted decision trees (GBDTs). In this work, we revisit the boosting paradigm, traditionally associated with tree ensembles, and ask whether it can be applied as a general training principle for LLM fine-tuning. We propose BoostLLM, a framework that transforms parameter-efficient fine-tuning into a multi-round residual optimization process by training sequential PEFT adapters as weak learners. To incorporate tabular inductive bias, BoostLLM integrates decision-tree paths as a second input view alongside raw features; analysis reveals that the path view acts as a structured teacher in early training steps before the model shifts toward feature-driven representations. Empirically, BoostLLM achieves consistent improvements over standard fine-tuning across multiple LLM backbones and datasets, matching or surpassing XGBoost across a wide range of shot counts and outperforming GPT-4o-based methods with a 4B model. We further show that the framework scales: pairing with stronger tree models and extended boosting horizons yields additional gains under appropriate stabilization. These results suggest that boosting can serve as a general training principle for LLM fine-tuning, particularly in low-data regimes for structured data.
Integrating Inductive Biases in Transformers via Distillation for Financial Time Series Forecasting
Mar 17, 2026Transformer-based models have been widely adopted for time-series forecasting due to their high representational capacity and architectural flexibility. However, many Transformer variants implicitly assume stationarity and stable temporal dynamics -- assumptions routinely violated in financial markets characterized by regime shifts and non-stationarity. Empirically, state-of-the-art time-series Transformers often underperform even vanilla Transformers on financial tasks, while simpler architectures with distinct inductive biases, such as CNNs and RNNs, can achieve stronger performance with substantially lower complexity. At the same time, no single inductive bias dominates across markets or regimes, suggesting that robust financial forecasting requires integrating complementary temporal priors. We propose TIPS (Transformer with Inductive Prior Synthesis), a knowledge distillation framework that synthesizes diverse inductive biases -- causality, locality, and periodicity -- within a unified Transformer. TIPS trains bias-specialized Transformer teachers via attention masking, then distills their knowledge into a single student model with regime-dependent alignment across inductive biases. Across four major equity markets, TIPS achieves state-of-the-art performance, outperforming strong ensemble baselines by 55%, 9%, and 16% in annual return, Sharpe ratio, and Calmar ratio, while requiring only 38% of the inference-time computation. Further analyses show that TIPS generates statistically significant excess returns beyond both vanilla Transformers and its teacher ensembles, and exhibits regime-dependent behavioral alignment with classical architectures during their profitable periods. These results highlight the importance of regime-dependent inductive bias utilization for robust generalization in non-stationary financial time series.
Supervised Machine Learning with a Novel Pointwise Density Estimator
Nov 06, 2007This article proposes a novel density estimation based algorithm for carrying out supervised machine learning. The proposed algorithm features O(n) time complexity for generating a classifier, where n is the number of sampling instances in the training dataset. This feature is highly desirable in contemporary applications that involve large and still growing databases. In comparison with the kernel density estimation based approaches, the mathe-matical fundamental behind the proposed algorithm is not based on the assump-tion that the number of training instances approaches infinite. As a result, a classifier generated with the proposed algorithm may deliver higher prediction accuracy than the kernel density estimation based classifier in some cases.
Supervised Machine Learning with a Novel Kernel Density Estimator
Oct 16, 2007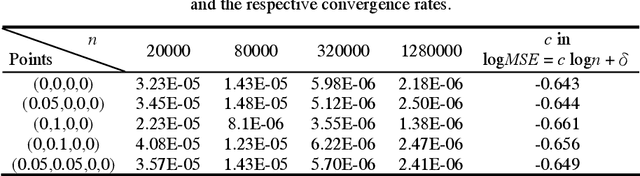
In recent years, kernel density estimation has been exploited by computer scientists to model machine learning problems. The kernel density estimation based approaches are of interest due to the low time complexity of either O(n) or O(n*log(n)) for constructing a classifier, where n is the number of sampling instances. Concerning design of kernel density estimators, one essential issue is how fast the pointwise mean square error (MSE) and/or the integrated mean square error (IMSE) diminish as the number of sampling instances increases. In this article, it is shown that with the proposed kernel function it is feasible to make the pointwise MSE of the density estimator converge at O(n^-2/3) regardless of the dimension of the vector space, provided that the probability density function at the point of interest meets certain conditions.