 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdate Rules for Parameter Estimation in Bayesian Networks
Feb 06, 2013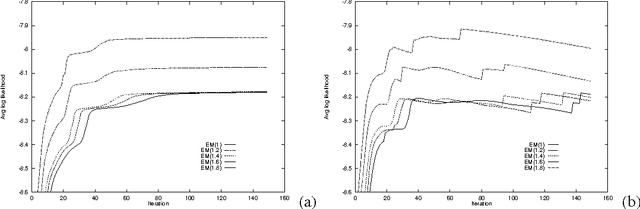
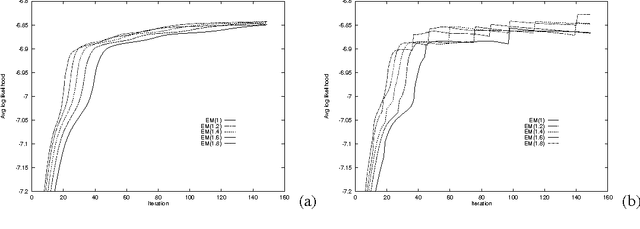
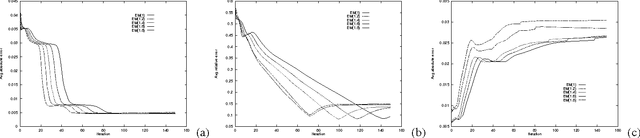
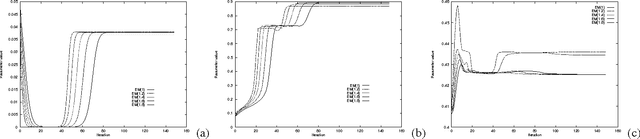
This paper re-examines the problem of parameter estimation in Bayesian networks with missing values and hidden variables from the perspective of recent work in on-line learning [Kivinen & Warmuth, 1994]. We provide a unified framework for parameter estimation that encompasses both on-line learning, where the model is continuously adapted to new data cases as they arrive, and the more traditional batch learning, where a pre-accumulated set of samples is used in a one-time model selection process. In the batch case, our framework encompasses both the gradient projection algorithm and the EM algorithm for Bayesian networks. The framework also leads to new on-line and batch parameter update schemes, including a parameterized version of EM. We provide both empirical and theoretical results indicating that parameterized EM allows faster convergence to the maximum likelihood parameters than does standard EM.
Tractable Inference for Complex Stochastic Processes
Jan 30, 2013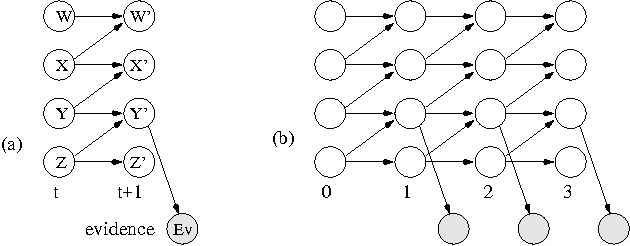
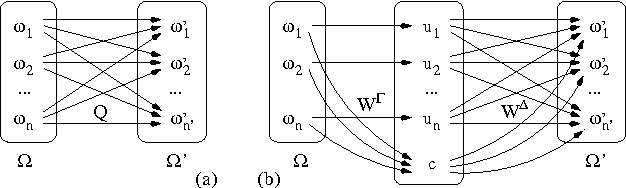
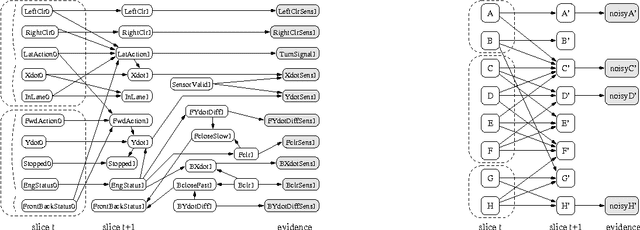
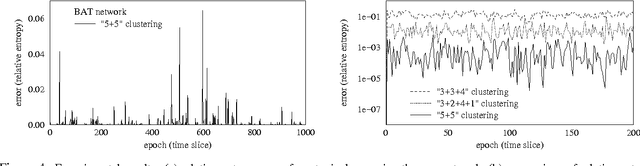
The monitoring and control of any dynamic system depends crucially on the ability to reason about its current status and its future trajectory. In the case of a stochastic system, these tasks typically involve the use of a belief state- a probability distribution over the state of the process at a given point in time. Unfortunately, the state spaces of complex processes are very large, making an explicit representation of a belief state intractable. Even in dynamic Bayesian networks (DBNs), where the process itself can be represented compactly, the representation of the belief state is intractable. We investigate the idea of maintaining a compact approximation to the true belief state, and analyze the conditions under which the errors due to the approximations taken over the lifetime of the process do not accumulate to make our answers completely irrelevant. We show that the error in a belief state contracts exponentially as the process evolves. Thus, even with multiple approximations, the error in our process remains bounded indefinitely. We show how the additional structure of a DBN can be used to design our approximation scheme, improving its performance significantly. We demonstrate the applicability of our ideas in the context of a monitoring task, showing that orders of magnitude faster inference can be achieved with only a small degradation in accuracy.
SPOOK: A System for Probabilistic Object-Oriented Knowledge Representation
Jan 23, 2013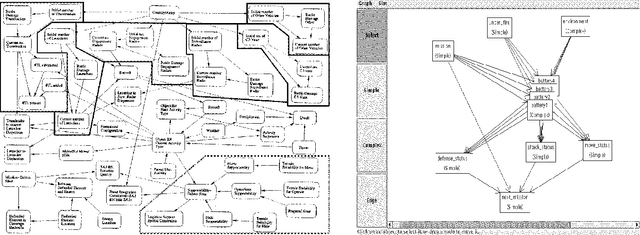
In previous work, we pointed out the limitations of standard Bayesian networks as a modeling framework for large, complex domains. We proposed a new, richly structured modeling language, {em Object-oriented Bayesian Netorks}, that we argued would be able to deal with such domains. However, it turns out that OOBNs are not expressive enough to model many interesting aspects of complex domains: the existence of specific named objects, arbitrary relations between objects, and uncertainty over domain structure. These aspects are crucial in real-world domains such as battlefield awareness. In this paper, we present SPOOK, an implemented system that addresses these limitations. SPOOK implements a more expressive language that allows it to represent the battlespace domain naturally and compactly. We present a new inference algorithm that utilizes the model structure in a fundamental way, and show empirically that it achieves orders of magnitude speedup over existing approaches.
A General Algorithm for Approximate Inference and its Application to Hybrid Bayes Nets
Jan 23, 2013



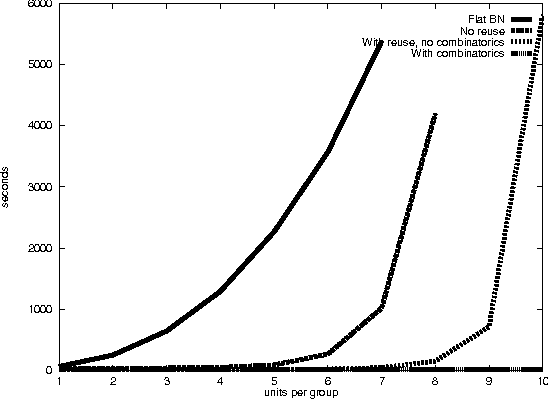
The clique tree algorithm is the standard method for doing inference in Bayesian networks. It works by manipulating clique potentials - distributions over the variables in a clique. While this approach works well for many networks, it is limited by the need to maintain an exact representation of the clique potentials. This paper presents a new unified approach that combines approximate inference and the clique tree algorithm, thereby circumventing this limitation. Many known approximate inference algorithms can be viewed as instances of this approach. The algorithm essentially does clique tree propagation, using approximate inference to estimate the densities in each clique. In many settings, the computation of the approximate clique potential can be done easily using statistical importance sampling. Iterations are used to gradually improve the quality of the estimation.
Discovering the Hidden Structure of Complex Dynamic Systems
Jan 23, 2013

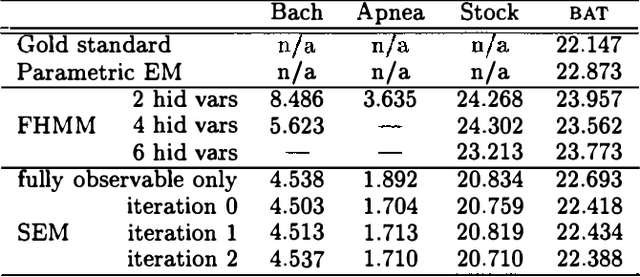
Dynamic Bayesian networks provide a compact and natural representation for complex dynamic systems. However, in many cases, there is no expert available from whom a model can be elicited. Learning provides an alternative approach for constructing models of dynamic systems. In this paper, we address some of the crucial computational aspects of learning the structure of dynamic systems, particularly those where some relevant variables are partially observed or even entirely unknown. Our approach is based on the Structural Expectation Maximization (SEM) algorithm. The main computational cost of the SEM algorithm is the gathering of expected sufficient statistics. We propose a novel approximation scheme that allows these sufficient statistics to be computed efficiently. We also investigate the fundamental problem of discovering the existence of hidden variables without exhaustive and expensive search. Our approach is based on the observation that, in dynamic systems, ignoring a hidden variable typically results in a violation of the Markov property. Thus, our algorithm searches for such violations in the data, and introduces hidden variables to explain them. We provide empirical results showing that the algorithm is able to learn the dynamics of complex systems in a computationally tractable way.
Probabilistic Models for Agents' Beliefs and Decisions
Jan 16, 2013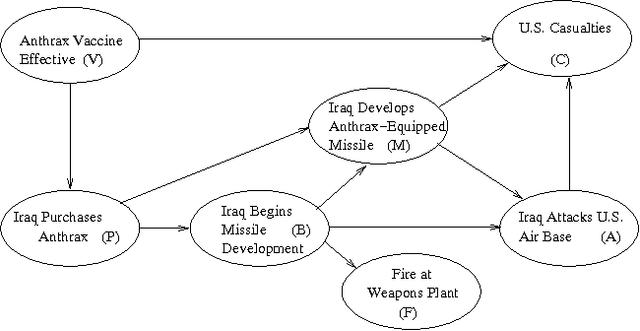
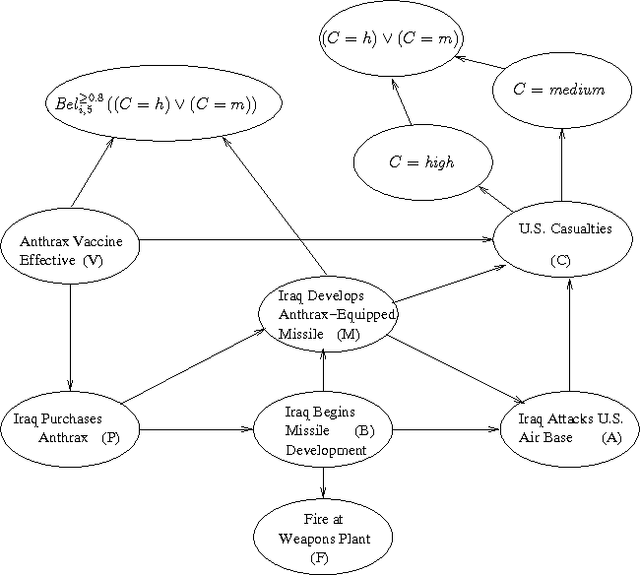
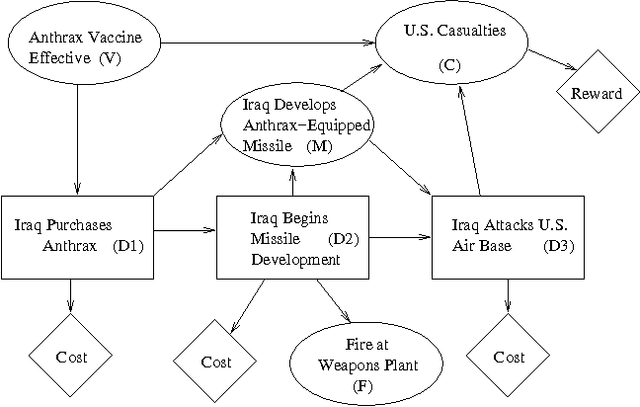
Many applications of intelligent systems require reasoning about the mental states of agents in the domain. We may want to reason about an agent's beliefs, including beliefs about other agents; we may also want to reason about an agent's preferences, and how his beliefs and preferences relate to his behavior. We define a probabilistic epistemic logic (PEL) in which belief statements are given a formal semantics, and provide an algorithm for asserting and querying PEL formulas in Bayesian networks. We then show how to reason about an agent's behavior by modeling his decision process as an influence diagram and assuming that he behaves rationally. PEL can then be used for reasoning from an agent's observed actions to conclusions about other aspects of the domain, including unobserved domain variables and the agent's mental states.
Policy Iteration for Factored MDPs
Jan 16, 2013
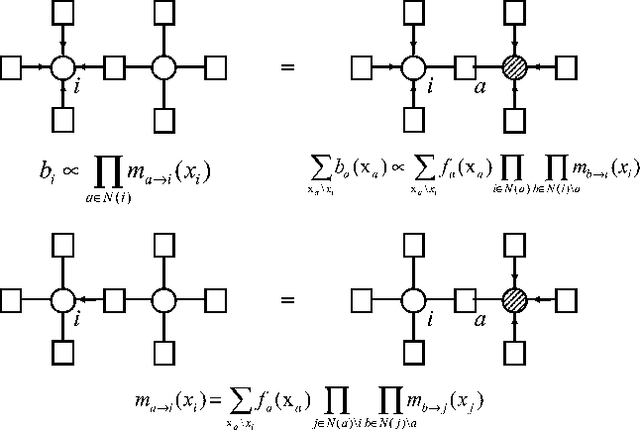
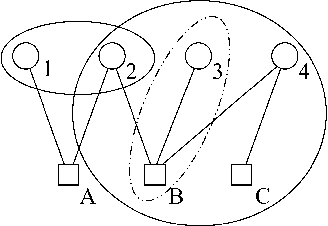
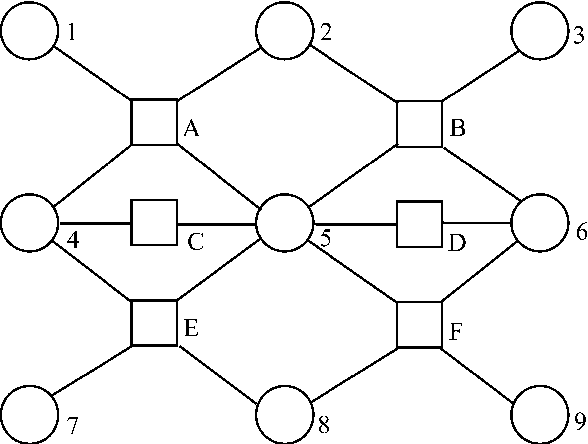
Many large MDPs can be represented compactly using a dynamic Bayesian network. Although the structure of the value function does not retain the structure of the process, recent work has shown that value functions in factored MDPs can often be approximated well using a decomposed value function: a linear combination of <I>restricted</I> basis functions, each of which refers only to a small subset of variables. An approximate value function for a particular policy can be computed using approximate dynamic programming, but this approach (and others) can only produce an approximation relative to a distance metric which is weighted by the stationary distribution of the current policy. This type of weighted projection is ill-suited to policy improvement. We present a new approach to value determination, that uses a simple closed-form computation to directly compute a least-squares decomposed approximation to the value function <I>for any weights</I>. We then use this value determination algorithm as a subroutine in a policy iteration process. We show that, under reasonable restrictions, the policies induced by a factored value function are compactly represented, and can be manipulated efficiently in a policy iteration process. We also present a method for computing error bounds for decomposed value functions using a variable-elimination algorithm for function optimization. The complexity of all of our algorithms depends on the factorization of system dynamics and of the approximate value function.
Being Bayesian about Network Structure
Jan 16, 2013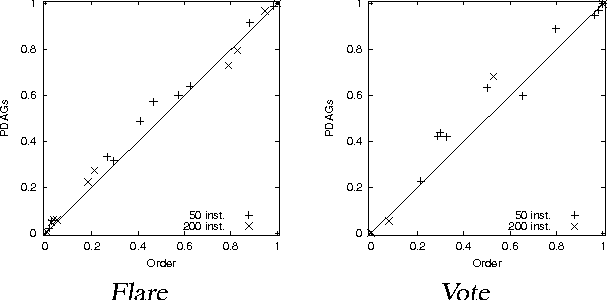
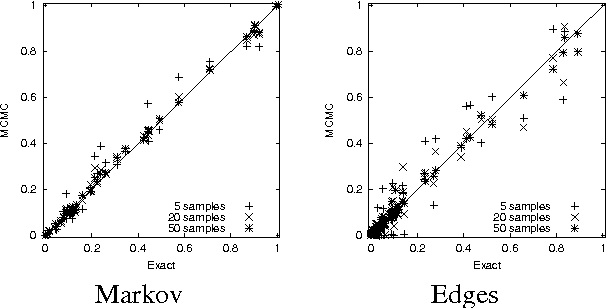
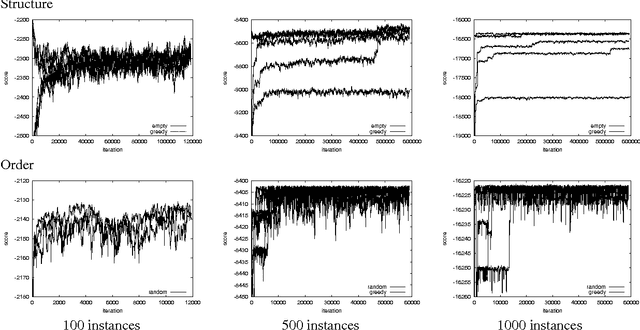
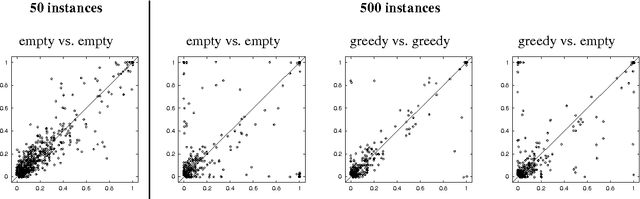
In many domains, we are interested in analyzing the structure of the underlying distribution, e.g., whether one variable is a direct parent of the other. Bayesian model-selection attempts to find the MAP model and use its structure to answer these questions. However, when the amount of available data is modest, there might be many models that have non-negligible posterior. Thus, we want compute the Bayesian posterior of a feature, i.e., the total posterior probability of all models that contain it. In this paper, we propose a new approach for this task. We first show how to efficiently compute a sum over the exponential number of networks that are consistent with a fixed ordering over network variables. This allows us to compute, for a given ordering, both the marginal probability of the data and the posterior of a feature. We then use this result as the basis for an algorithm that approximates the Bayesian posterior of a feature. Our approach uses a Markov Chain Monte Carlo (MCMC) method, but over orderings rather than over network structures. The space of orderings is much smaller and more regular than the space of structures, and has a smoother posterior `landscape'. We present empirical results on synthetic and real-life datasets that compare our approach to full model averaging (when possible), to MCMC over network structures, and to a non-Bayesian bootstrap approach.
Utilities as Random Variables: Density Estimation and Structure Discovery
Jan 16, 2013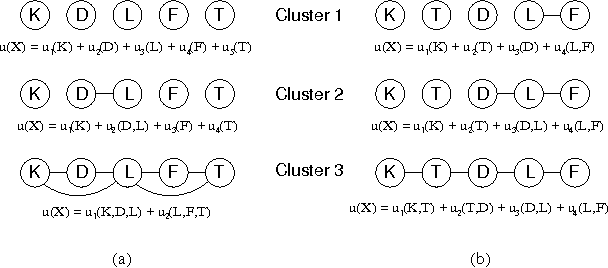
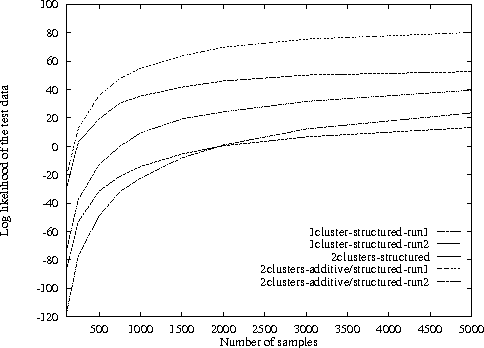
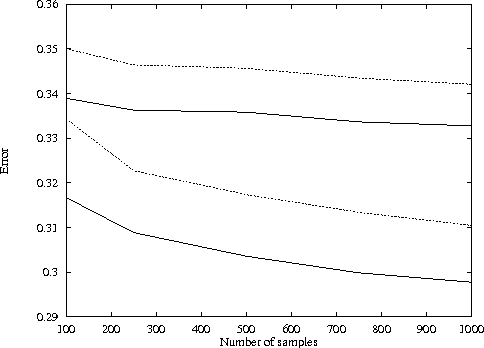
Decision theory does not traditionally include uncertainty over utility functions. We argue that the a person's utility value for a given outcome can be treated as we treat other domain attributes: as a random variable with a density function over its possible values. We show that we can apply statistical density estimation techniques to learn such a density function from a database of partially elicited utility functions. In particular, we define a Bayesian learning framework for this problem, assuming the distribution over utilities is a mixture of Gaussians, where the mixture components represent statistically coherent subpopulations. We can also extend our techniques to the problem of discovering generalized additivity structure in the utility functions in the population. We define a Bayesian model selection criterion for utility function structure and a search procedure over structures. The factorization of the utilities in the learned model, and the generalization obtained from density estimation, allows us to provide robust estimates of utilities using a significantly smaller number of utility elicitation questions. We experiment with our technique on synthetic utility data and on a real database of utility functions in the domain of prenatal diagnosis.
Exact Inference in Networks with Discrete Children of Continuous Parents
Jan 10, 2013



Many real life domains contain a mixture of discrete and continuous variables and can be modeled as hybrid Bayesian Networks. Animportant subclass of hybrid BNs are conditional linear Gaussian (CLG) networks, where the conditional distribution of the continuous variables given an assignment to the discrete variables is a multivariate Gaussian. Lauritzen's extension to the clique tree algorithm can be used for exact inference in CLG networks. However, many domains also include discrete variables that depend on continuous ones, and CLG networks do not allow such dependencies to berepresented. No exact inference algorithm has been proposed for these enhanced CLG networks. In this paper, we generalize Lauritzen's algorithm, providing the first "exact" inference algorithm for augmented CLG networks - networks where continuous nodes are conditional linear Gaussians but that also allow discrete children ofcontinuous parents. Our algorithm is exact in the sense that it computes the exact distributions over the discrete nodes, and the exact first and second moments of the continuous ones, up to the accuracy obtained by numerical integration used within thealgorithm. When the discrete children are modeled with softmax CPDs (as is the case in many real world domains) the approximation of the continuous distributions using the first two moments is particularly accurate. Our algorithm is simple to implement and often comparable in its complexity to Lauritzen's algorithm. We show empirically that it achieves substantially higher accuracy than previous approximate algorithms.