 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Agnostic Dual Quality Assessment for Adversarial Machine Learning and an Analysis of Current Neural Networks and Defenses
Jun 14, 2019

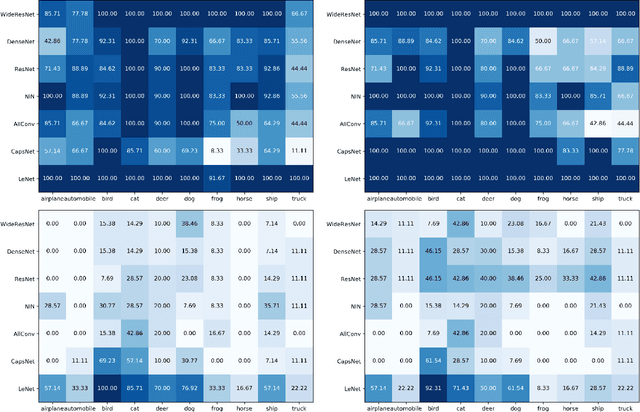
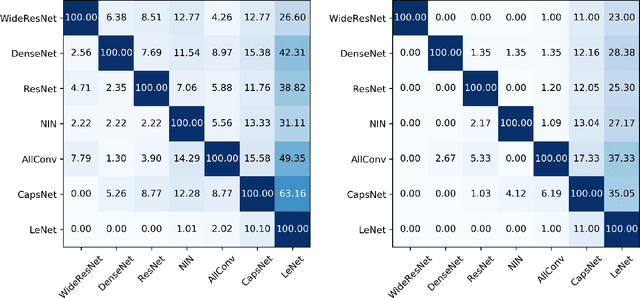
In adversarial machine learning, there are a huge number of attacks of various types which makes the evaluation of robustness for new models and defenses a daunting task. To make matters worse, there is an inherent bias in attacks and defenses. Here, we organize the problems faced (model dependence, insufficient evaluation, unreliable adversarial samples and perturbation dependent results) and propose a dual quality assessment method together with the concept of robustness levels to tackle them. We validate the dual quality assessment on state-of-the-art models (WideResNet, ResNet, AllConv, DenseNet, NIN, LeNet and CapsNet) as well as the current hardest defenses proposed at ICLR 2018 as well as the widely known adversarial training, showing that current models and defenses are vulnerable in all levels of robustness. Moreover, we show that robustness to $L_0$ and $L_\infty$ attacks differ greatly and therefore duality should be taken into account for a correct assessment. Interestingly, a by-product of the assessment proposed is a novel $L_\infty$ black-box method which requires even less perturbation than the One-Pixel Attack (only 12\% of One-Pixel Attack's amount of perturbation) to achieve similar results. Thus, this paper elucidates the problems of robustness evaluation, proposes a dual quality assessment to tackle them as well as analyze the robustness of current models and defenses. Hopefully, the current analysis and proposed methods would aid the development of more robust deep neural networks and hybrids alike. Code available at: http://bit.ly/DualQualityAssessment
Self Training Autonomous Driving Agent
Apr 26, 2019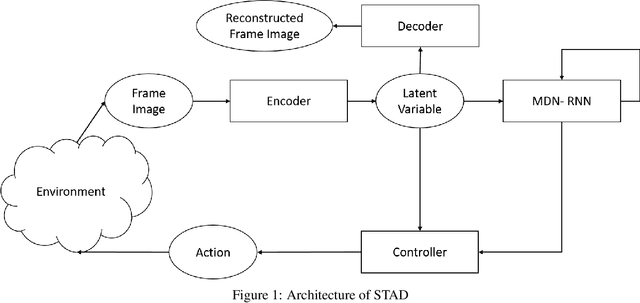

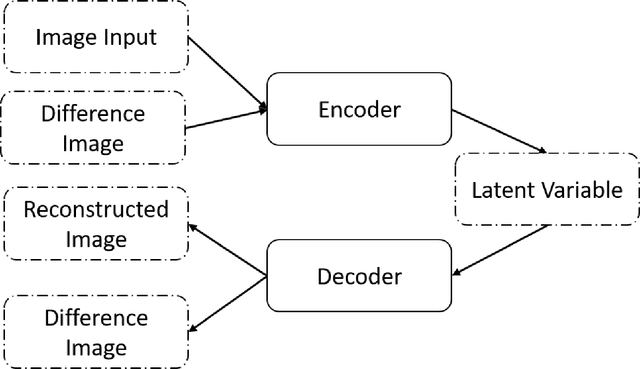
Intrinsically, driving is a Markov Decision Process which suits well the reinforcement learning paradigm. In this paper, we propose a novel agent which learns to drive a vehicle without any human assistance. We use the concept of reinforcement learning and evolutionary strategies to train our agent in a 2D simulation environment. Our model's architecture goes beyond the World Model's by introducing difference images in the auto encoder. This novel involvement of difference images in the auto-encoder gives better representation of the latent space with respect to the motion of vehicle and helps an autonomous agent to learn more efficiently how to drive a vehicle. Results show that our method requires fewer (96% less) total agents, (87.5% less) agents per generations, (70% less) generations and (90% less) rollouts than the original architecture while achieving the same accuracy of the original.
Batch Tournament Selection for Genetic Programming
Apr 18, 2019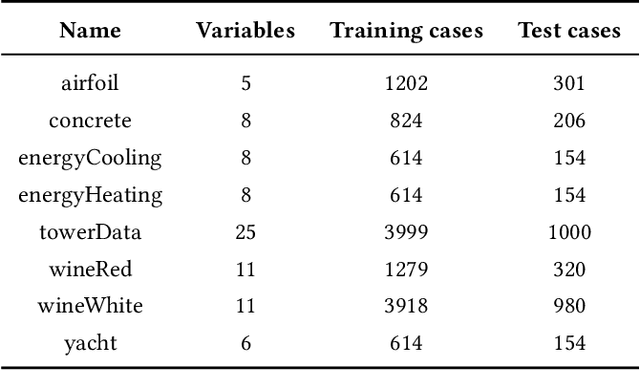
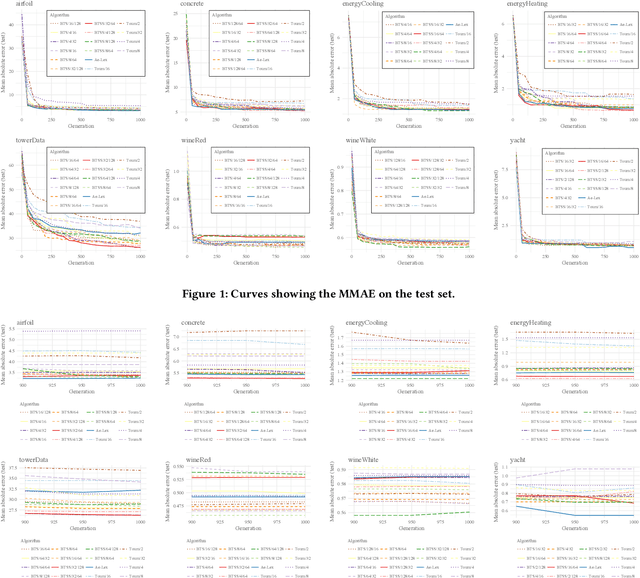
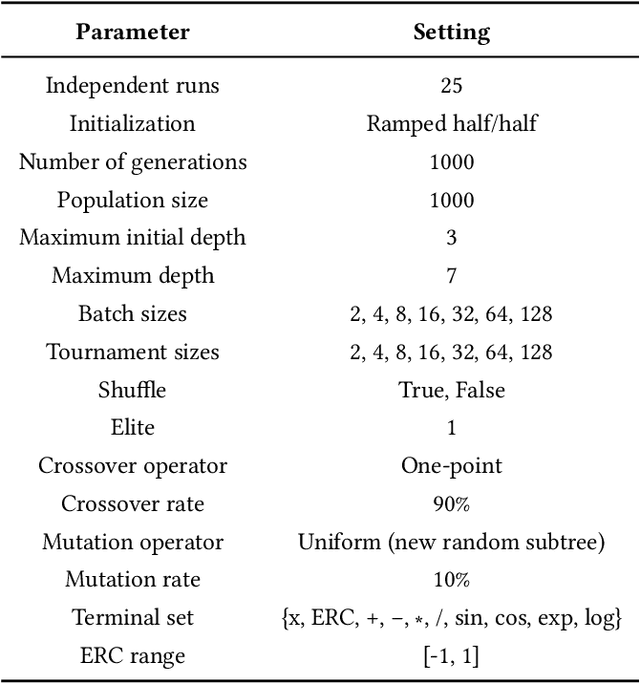
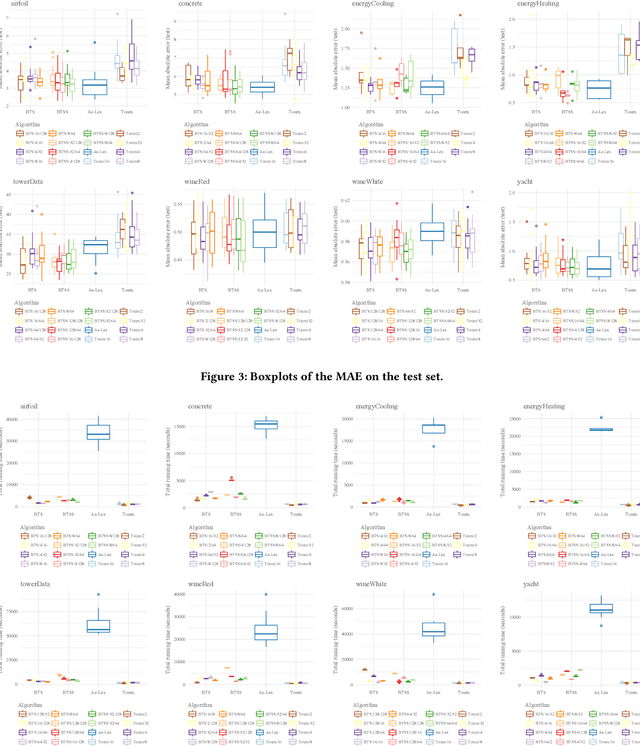
Lexicase selection achieves very good solution quality by introducing ordered test cases. However, the computational complexity of lexicase selection can prohibit its use in many applications. In this paper, we introduce Batch Tournament Selection (BTS), a hybrid of tournament and lexicase selection which is approximately one order of magnitude faster than lexicase selection while achieving a competitive quality of solutions. Tests on a number of regression datasets show that BTS compares well with lexicase selection in terms of mean absolute error while having a speed-up of up to 25 times. Surprisingly, BTS and lexicase selection have almost no difference in both diversity and performance. This reveals that batches and ordered test cases are completely different mechanisms which share the same general principle fostering the specialization of individuals. This work introduces an efficient algorithm that sheds light onto the main principles behind the success of lexicase, potentially opening up a new range of possibilities for algorithms to come.
Tackling Unit Commitment and Load Dispatch Problems Considering All Constraints with Evolutionary Computation
Mar 06, 2019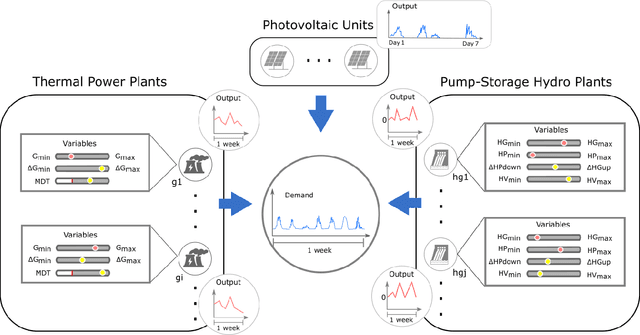
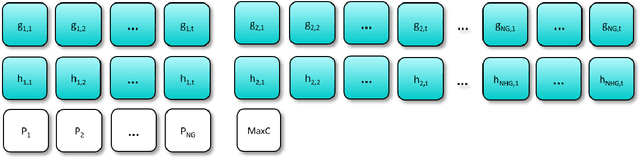
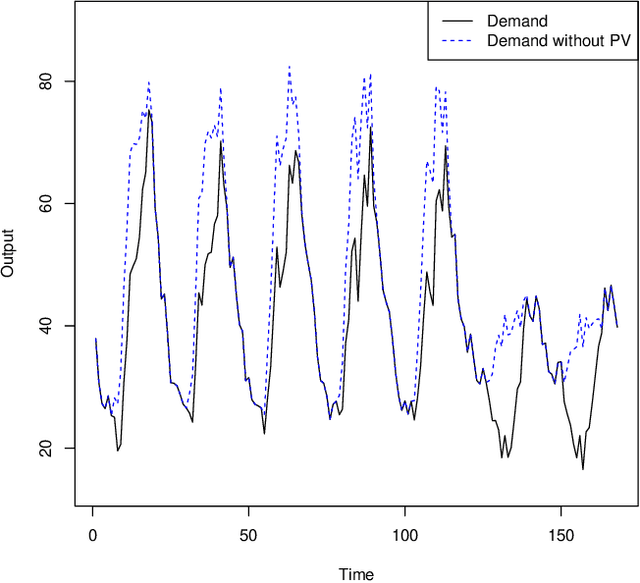
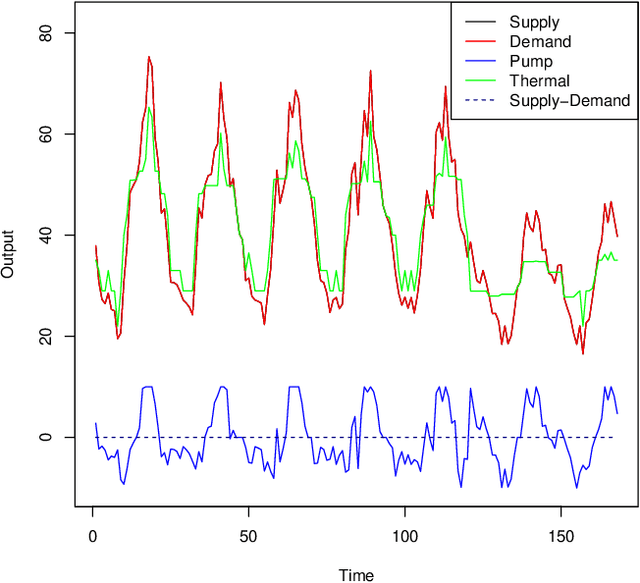
Unit commitment and load dispatch problems are important and complex problems in power system operations that have being traditionally solved separately. In this paper, both problems are solved together without approximations or simplifications. In fact, the problem solved has a massive amount of grid-connected photovoltaic units, four pump-storage hydro plants as energy storage units and ten thermal power plants, each with its own set of operation requirements that need to be satisfied. To face such a complex constrained optimization problem an adaptive repair method is proposed. By including a given repair method itself as a parameter to be optimized, the proposed adaptive repair method avoid any bias in repair choices. Moreover, this results in a repair method that adapt to the problem and will improve together with the solution during optimization. Experiments are conducted revealing that the proposed method is capable of surpassing exact method solutions on a simplified version of the problem with approximations as well as solve the otherwise intractable complete problem without simplifications. Moreover, since the proposed approach can be applied to other problems in general and it may not be obvious how to choose the constraint handling for a certain constraint, a guideline is provided explaining the reasoning behind. Thus, this paper open further possibilities to deal with the ever changing types of generation units and other similarly complex operation/schedule optimization problems with many difficult constraints.
Understanding the One-Pixel Attack: Propagation Maps and Locality Analysis
Feb 08, 2019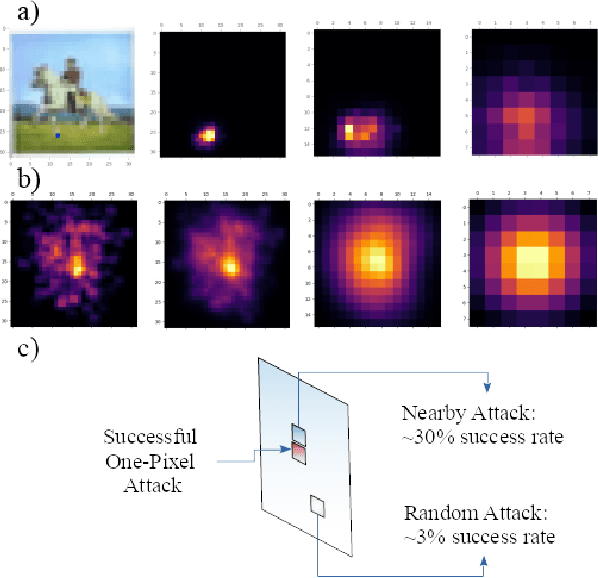

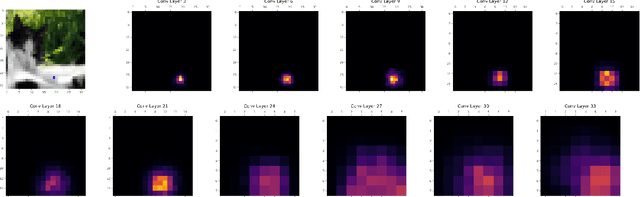
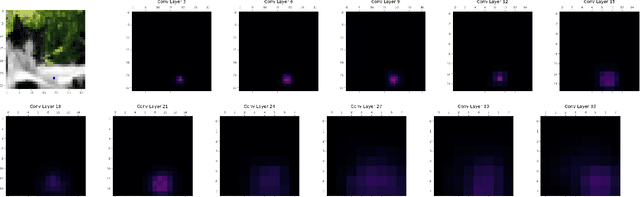
Deep neural networks were shown to be vulnerable to single pixel modifications. However, the reason behind such phenomena has never been elucidated. Here, we propose Propagation Maps which show the influence of the perturbation in each layer of the network. Propagation Maps reveal that even in extremely deep networks such as Resnet, modification in one pixel easily propagates until the last layer. In fact, this initial local perturbation is also shown to spread becoming a global one and reaching absolute difference values that are close to the maximum value of the original feature maps in a given layer. Moreover, we do a locality analysis in which we demonstrate that nearby pixels of the perturbed one in the one-pixel attack tend to share the same vulnerability, revealing that the main vulnerability lies in neither neurons nor pixels but receptive fields. Hopefully, the analysis conducted in this work together with a new technique called propagation maps shall shed light into the inner workings of other adversarial samples and be the basis of new defense systems to come.
Universal Rules for Fooling Deep Neural Networks based Text Classification
Jan 22, 2019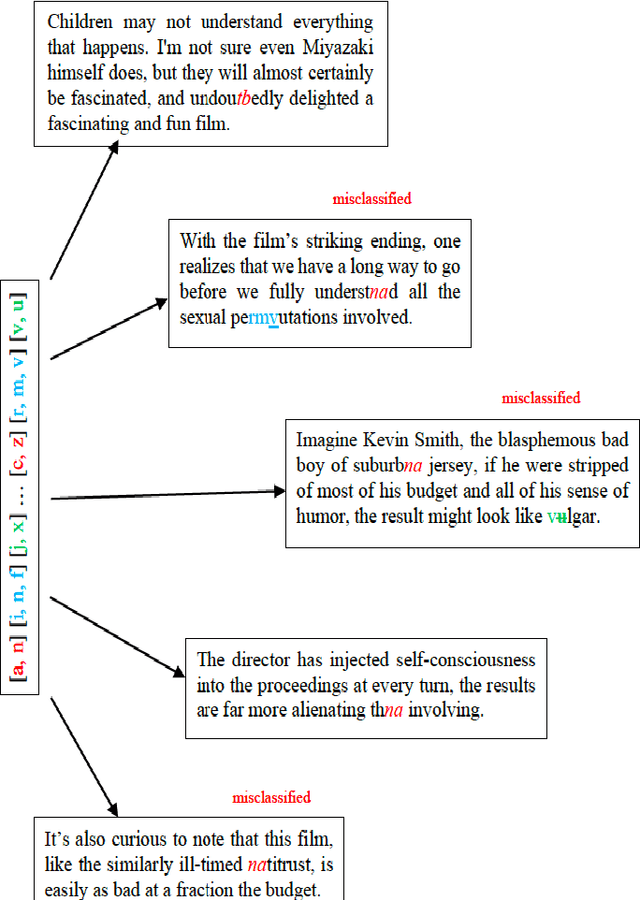
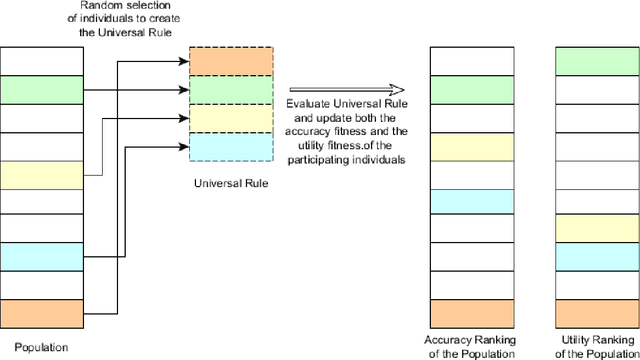
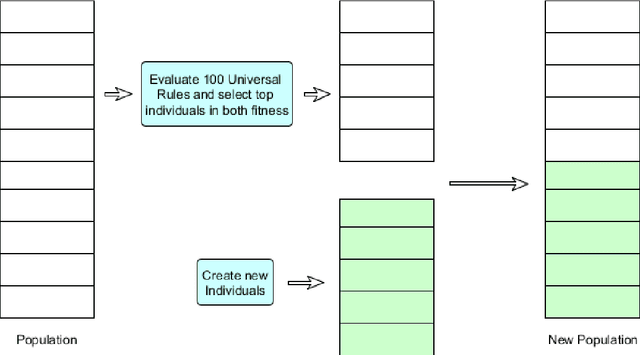
Recently, deep learning based natural language processing techniques are being extensively used to deal with spam mail, censorship evaluation in social networks, among others. However, there is only a couple of works evaluating the vulnerabilities of such deep neural networks. Here, we go beyond attacks to investigate, for the first time, universal rules, i.e., rules that are sample agnostic and therefore could turn any text sample in an adversarial one. In fact, the universal rules do not use any information from the method itself (no information from the method, gradient information or training dataset information is used), making them black-box universal attacks. In other words, the universal rules are sample and method agnostic. By proposing a coevolutionary optimization algorithm we show that it is possible to create universal rules that can automatically craft imperceptible adversarial samples (only less than five perturbations which are close to misspelling are inserted in the text sample). A comparison with a random search algorithm further justifies the strength of the method. Thus, universal rules for fooling networks are here shown to exist. Hopefully, the results from this work will impact the development of yet more sample and model agnostic attacks as well as their defenses, culminating in perhaps a new age for artificial intelligence.
General Subpopulation Framework and Taming the Conflict Inside Populations
Jan 02, 2019Structured evolutionary algorithms have been investigated for some time. However, they have been under-explored specially in the field of multi-objective optimization. Despite their good results, the use of complex dynamics and structures make their understanding and adoption rate low. Here, we propose the general subpopulation framework that has the capability of integrating optimization algorithms without restrictions as well as aid the design of structured algorithms. The proposed framework is capable of generalizing most of the structured evolutionary algorithms, such as cellular algorithms, island models, spatial predator-prey and restricted mating based algorithms under its formalization. Moreover, we propose two algorithms based on the general subpopulation framework, demonstrating that with the simple addition of a number of single-objective differential evolution algorithms for each objective the results improve greatly, even when the combined algorithms behave poorly when evaluated alone at the tests. Most importantly, the comparison between the subpopulation algorithms and their related panmictic algorithms suggests that the competition between different strategies inside one population can have deleterious consequences for an algorithm and reveal a strong benefit of using the subpopulation framework. The code for SAN, the proposed multi-objective algorithm which has the current best results in the hardest benchmark, is available at the following https://github.com/zweifel/zweifel
Self Organizing Classifiers and Niched Fitness
Nov 20, 2018

Learning classifier systems are adaptive learning systems which have been widely applied in a multitude of application domains. However, there are still some generalization problems unsolved. The hurdle is that fitness and niching pressures are difficult to balance. Here, a new algorithm called Self Organizing Classifiers is proposed which faces this problem from a different perspective. Instead of balancing the pressures, both pressures are separated and no balance is necessary. In fact, the proposed algorithm possesses a dynamical population structure that self-organizes itself to better project the input space into a map. The niched fitness concept is defined along with its dynamical population structure, both are indispensable for the understanding of the proposed method. Promising results are shown on two continuous multi-step problems. One of which is yet more challenging than previous problems of this class in the literature.
* arXiv admin note: text overlap with arXiv:1811.08225
Self Organizing Classifiers: First Steps in Structured Evolutionary Machine Learning
Nov 20, 2018
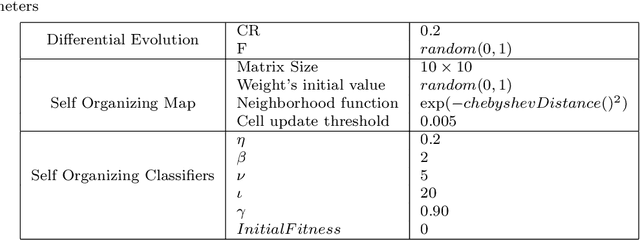
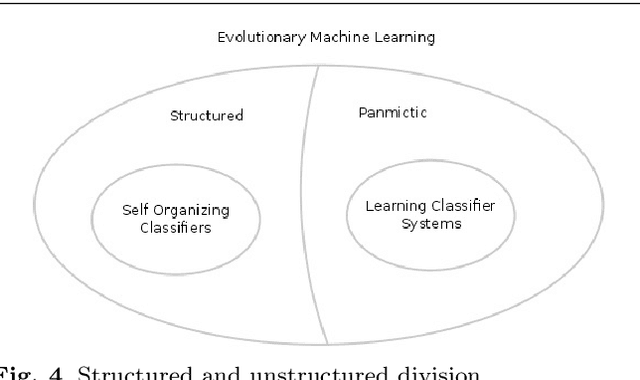
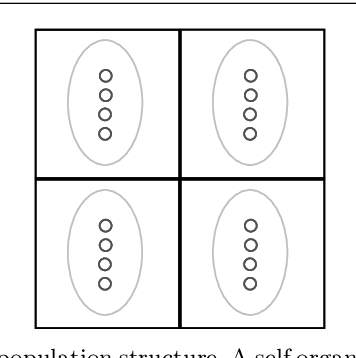
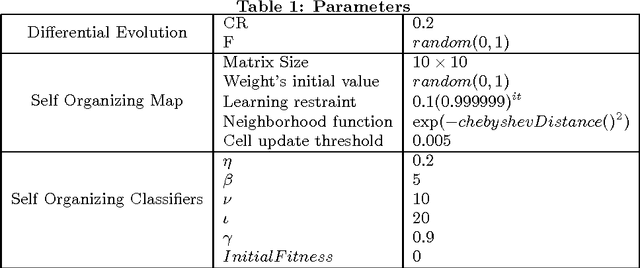
Learning classifier systems (LCSs) are evolutionary machine learning algorithms, flexible enough to be applied to reinforcement, supervised and unsupervised learning problems with good performance. Recently, self organizing classifiers were proposed which are similar to LCSs but have the advantage that in its structured population no balance between niching and fitness pressure is necessary. However, more tests and analysis are required to verify its benefits. Here, a variation of the first algorithm is proposed which uses a parameterless self organizing map (SOM). This algorithm is applied in challenging problems such as big, noisy as well as dynamically changing continuous input-action mazes (growing and compressing mazes are included) with good performance. Moreover, a genetic operator is proposed which utilizes the topological information of the SOM's population structure, improving the results. Thus, the first steps in structured evolutionary machine learning are shown, nonetheless, the problems faced are more difficult than the state-of-art continuous input-action multi-step ones.
Contingency Training
Nov 20, 2018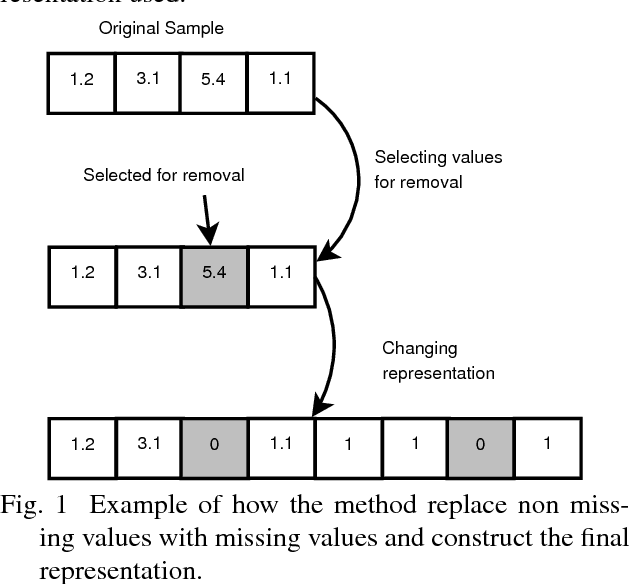
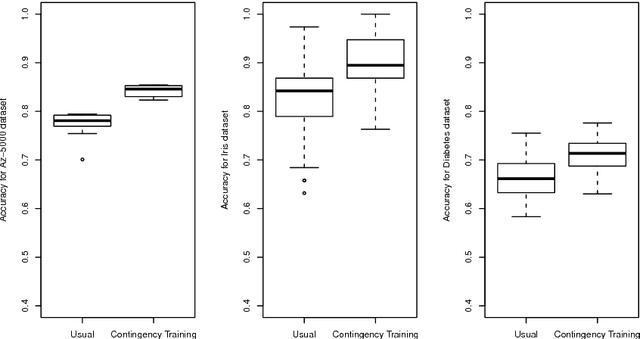
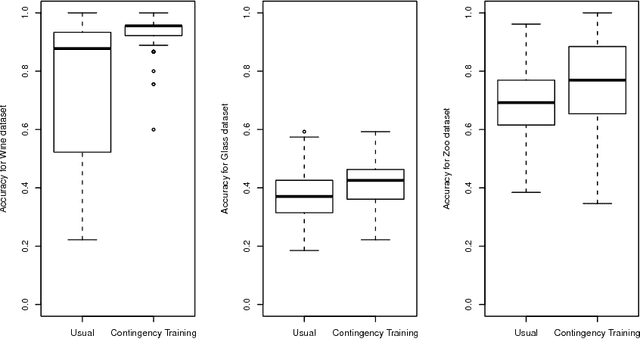
When applied to high-dimensional datasets, feature selection algorithms might still leave dozens of irrelevant variables in the dataset. Therefore, even after feature selection has been applied, classifiers must be prepared to the presence of irrelevant variables. This paper investigates a new training method called Contingency Training which increases the accuracy as well as the robustness against irrelevant attributes. Contingency training is classifier independent. By subsampling and removing information from each sample, it creates a set of constraints. These constraints aid the method to automatically find proper importance weights of the dataset's features. Experiments are conducted with the contingency training applied to neural networks over traditional datasets as well as datasets with additional irrelevant variables. For all of the tests, contingency training surpassed the unmodified training on datasets with irrelevant variables and even outperformed slightly when only a few or no irrelevant variables were present.