 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness for Vision Transformer with a Simple Dynamic Scanning Augmentation
Nov 01, 2023



Vision Transformer (ViT) has demonstrated promising performance in computer vision tasks, comparable to state-of-the-art neural networks. Yet, this new type of deep neural network architecture is vulnerable to adversarial attacks limiting its capabilities in terms of robustness. This article presents a novel contribution aimed at further improving the accuracy and robustness of ViT, particularly in the face of adversarial attacks. We propose an augmentation technique called `Dynamic Scanning Augmentation' that leverages dynamic input sequences to adaptively focus on different patches, thereby maintaining performance and robustness. Our detailed investigations reveal that this adaptability to the input sequence induces significant changes in the attention mechanism of ViT, even for the same image. We introduce four variations of Dynamic Scanning Augmentation, outperforming ViT in terms of both robustness to adversarial attacks and accuracy against natural images, with one variant showing comparable results. By integrating our augmentation technique, we observe a substantial increase in ViT's robustness, improving it from $17\%$ to $92\%$ measured across different types of adversarial attacks. These findings, together with other comprehensive tests, indicate that Dynamic Scanning Augmentation enhances accuracy and robustness by promoting a more adaptive type of attention. In conclusion, this work contributes to the ongoing research on Vision Transformers by introducing Dynamic Scanning Augmentation as a technique for improving the accuracy and robustness of ViT. The observed results highlight the potential of this approach in advancing computer vision tasks and merit further exploration in future studies.
Symmetrical SyncMap for Imbalanced General Chunking Problems
Oct 16, 2023Recently, SyncMap pioneered an approach to learn complex structures from sequences as well as adapt to any changes in underlying structures. This is achieved by using only nonlinear dynamical equations inspired by neuron group behaviors, i.e., without loss functions. Here we propose Symmetrical SyncMap that goes beyond the original work to show how to create dynamical equations and attractor-repeller points which are stable over the long run, even dealing with imbalanced continual general chunking problems (CGCPs). The main idea is to apply equal updates from negative and positive feedback loops by symmetrical activation. We then introduce the concept of memory window to allow for more positive updates. Our algorithm surpasses or ties other unsupervised state-of-the-art baselines in all 12 imbalanced CGCPs with various difficulties, including dynamically changing ones. To verify its performance in real-world scenarios, we conduct experiments on several well-studied structure learning problems. The proposed method surpasses substantially other methods in 3 out of 4 scenarios, suggesting that symmetrical activation plays a critical role in uncovering topological structures and even hierarchies encoded in temporal data.
* 40 pages, 19 figures
A Survey on Reservoir Computing and its Interdisciplinary Applications Beyond Traditional Machine Learning
Jul 27, 2023Reservoir computing (RC), first applied to temporal signal processing, is a recurrent neural network in which neurons are randomly connected. Once initialized, the connection strengths remain unchanged. Such a simple structure turns RC into a non-linear dynamical system that maps low-dimensional inputs into a high-dimensional space. The model's rich dynamics, linear separability, and memory capacity then enable a simple linear readout to generate adequate responses for various applications. RC spans areas far beyond machine learning, since it has been shown that the complex dynamics can be realized in various physical hardware implementations and biological devices. This yields greater flexibility and shorter computation time. Moreover, the neuronal responses triggered by the model's dynamics shed light on understanding brain mechanisms that also exploit similar dynamical processes. While the literature on RC is vast and fragmented, here we conduct a unified review of RC's recent developments from machine learning to physics, biology, and neuroscience. We first review the early RC models, and then survey the state-of-the-art models and their applications. We further introduce studies on modeling the brain's mechanisms by RC. Finally, we offer new perspectives on RC development, including reservoir design, coding frameworks unification, physical RC implementations, and interaction between RC, cognitive neuroscience and evolution.
Generating Oscillation Activity with Echo State Network to Mimic the Behavior of a Simple Central Pattern Generator
Jun 19, 2023This paper presents a method for reproducing a simple central pattern generator (CPG) using a modified Echo State Network (ESN). Conventionally, the dynamical reservoir needs to be damped to stabilize and preserve memory. However, we find that a reservoir that develops oscillatory activity without any external excitation can mimic the behaviour of a simple CPG in biological systems. We define the specific neuron ensemble required for generating oscillations in the reservoir and demonstrate how adjustments to the leaking rate, spectral radius, topology, and population size can increase the probability of reproducing these oscillations. The results of the experiments, conducted on the time series simulation tasks, demonstrate that the ESN is able to generate the desired waveform without any input. This approach offers a promising solution for the development of bio-inspired controllers for robotic systems.
Dynamical Equations With Bottom-up Self-Organizing Properties Learn Accurate Dynamical Hierarchies Without Any Loss Function
Feb 04, 2023Self-organization is ubiquitous in nature and mind. However, machine learning and theories of cognition still barely touch the subject. The hurdle is that general patterns are difficult to define in terms of dynamical equations and designing a system that could learn by reordering itself is still to be seen. Here, we propose a learning system, where patterns are defined within the realm of nonlinear dynamics with positive and negative feedback loops, allowing attractor-repeller pairs to emerge for each pattern observed. Experiments reveal that such a system can map temporal to spatial correlation, enabling hierarchical structures to be learned from sequential data. The results are accurate enough to surpass state-of-the-art unsupervised learning algorithms in seven out of eight experiments as well as two real-world problems. Interestingly, the dynamic nature of the system makes it inherently adaptive, giving rise to phenomena similar to phase transitions in chemistry/thermodynamics when the input structure changes. Thus, the work here sheds light on how self-organization can allow for pattern recognition and hints at how intelligent behavior might emerge from simple dynamic equations without any objective/loss function.
Deep neural network loses attention to adversarial images
Jun 10, 2021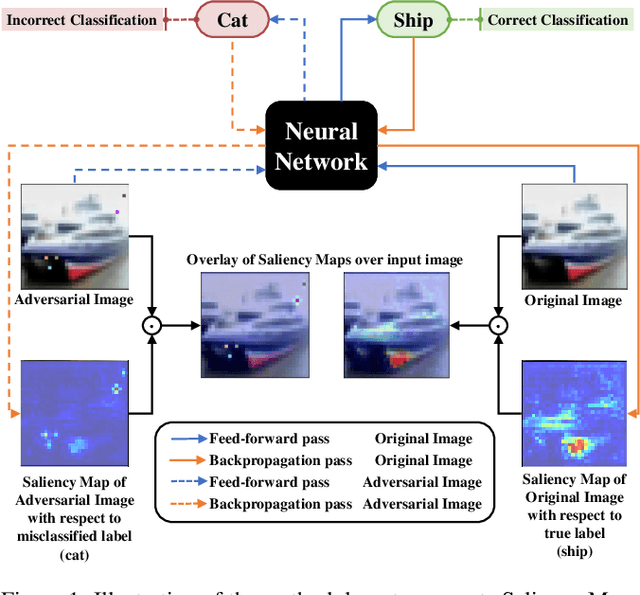



Adversarial algorithms have shown to be effective against neural networks for a variety of tasks. Some adversarial algorithms perturb all the pixels in the image minimally for the image classification task in image classification. In contrast, some algorithms perturb few pixels strongly. However, very little information is available regarding why these adversarial samples so diverse from each other exist. Recently, Vargas et al. showed that the existence of these adversarial samples might be due to conflicting saliency within the neural network. We test this hypothesis of conflicting saliency by analysing the Saliency Maps (SM) and Gradient-weighted Class Activation Maps (Grad-CAM) of original and few different types of adversarial samples. We also analyse how different adversarial samples distort the attention of the neural network compared to original samples. We show that in the case of Pixel Attack, perturbed pixels either calls the network attention to themselves or divert the attention from them. Simultaneously, the Projected Gradient Descent Attack perturbs pixels so that intermediate layers inside the neural network lose attention for the correct class. We also show that both attacks affect the saliency map and activation maps differently. Thus, shedding light on why some defences successful against some attacks remain vulnerable against other attacks. We hope that this analysis will improve understanding of the existence and the effect of adversarial samples and enable the community to develop more robust neural networks.
Perceptual Deep Neural Networks: Adversarial Robustness through Input Recreation
Sep 08, 2020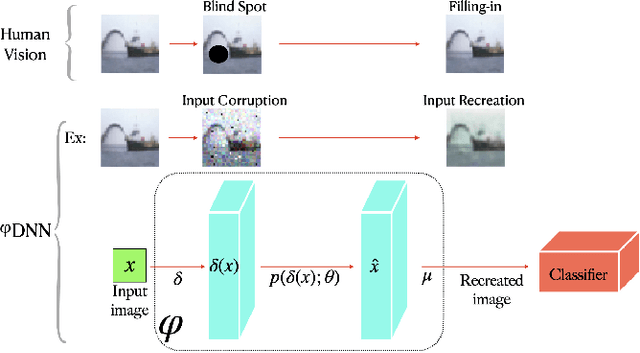
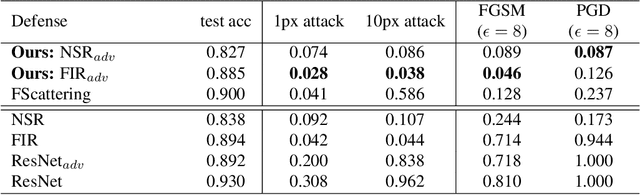
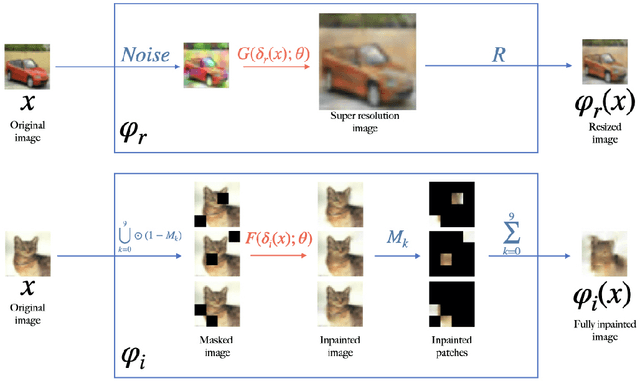
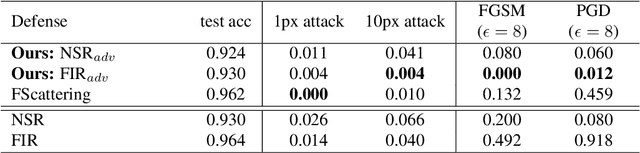
Adversarial examples have shown that albeit highly accurate, models learned by machines, differently from humans,have many weaknesses. However, humans' perception is also fundamentally different from machines, because we do not see the signals which arrive at the retina but a rather complex recreation of them. In this paper, we explore how machines could recreate the input as well as investigate the benefits of such an augmented perception. In this regard, we propose Perceptual Deep Neural Networks ($\varphi$DNN) which also recreate their own input before further processing. The concept is formalized mathematically and two variations of it are developed (one based on inpainting the whole image and the other based on a noisy resized super resolution recreation). Experiments reveal that $\varphi$DNNs can reduce attacks' accuracy substantially, surpassing state-of-the-art defenses in 87% of the tests for adversarial training variations and 100% of the tests when only comparing with other pre-processing type of defenses. Moreover, the recreation process intentionally corrupts the input image. Interestingly, we show by ablation tests that corrupting the input is, although counter-intuitive,beneficial. This suggests that the blind-spot in vertebrates might also be, analogously, the precursor of visual robustness. Thus, $\varphi$DNNs reveal that input recreation has strong benefits for artificial neural networks similar to biological ones, shedding light into the importance of the blind-spot and starting an area of perception models for robust recognition in artificial intelligence.
Continual General Chunking Problem and SyncMap
Jun 16, 2020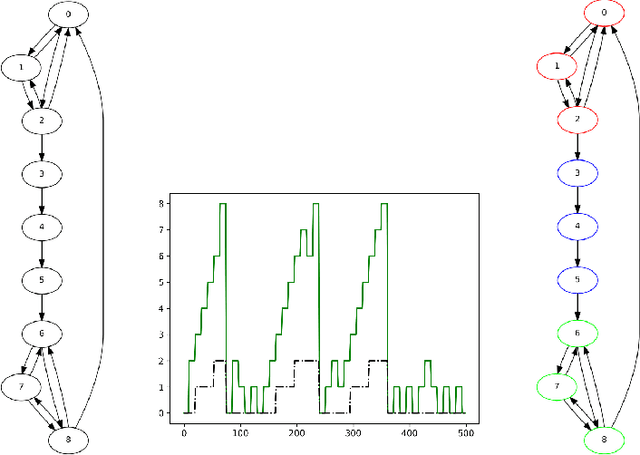
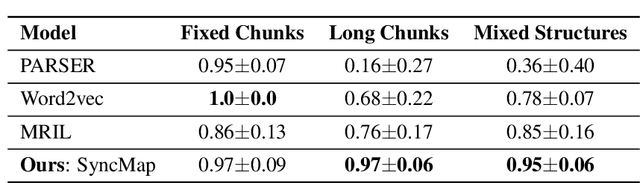
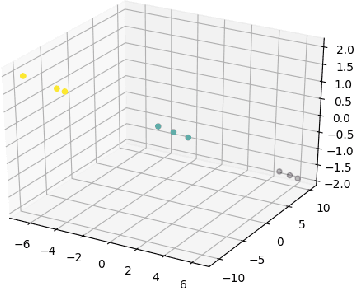
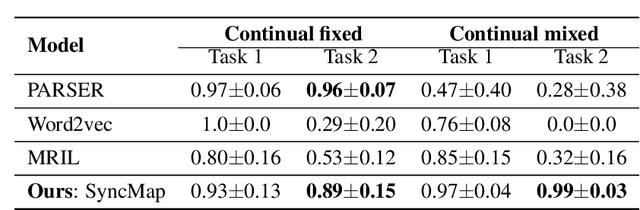
Humans possess an inherent ability to chunk sequences into their constituent parts. In fact, this ability is thought to bootstrap language skills to the learning of image patterns which might be a key to a more animal-like type of intelligence. Here, we propose a continual generalization of the chunking problem (an unsupervised problem), encompassing fixed and probabilistic chunks, discovery of temporal and causal structures and their continual variations. Additionally, we propose an algorithm called SyncMap that can learn and adapt to changes in the problem by creating a dynamic map which preserves the correlation between variables. Results of SyncMap suggest that the proposed algorithm learn near optimal solutions, despite the presence of many types of structures and their continual variation. When compared to Word2vec, PARSER and MRIL, SyncMap surpasses or ties with the best algorithm on $77\%$ of the scenarios while being the second best in the remaing $23\%$.
Evolving Robust Neural Architectures to Defend from Adversarial Attacks
Jun 27, 2019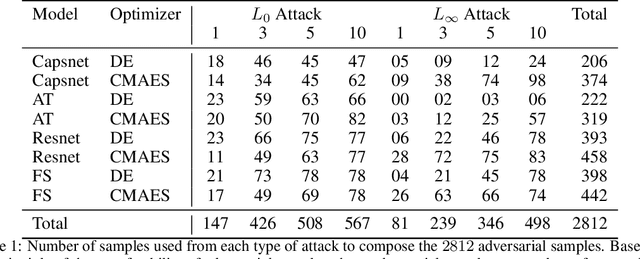
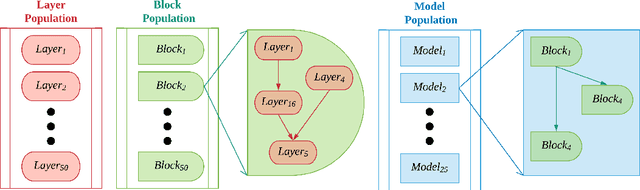
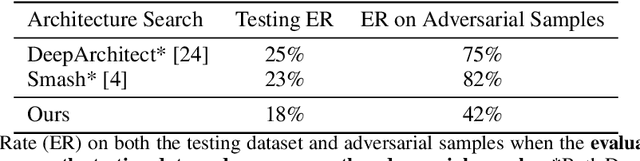

Deep neural networks were shown to misclassify slightly modified input images. Recently, many defenses have been proposed but none have improved consistently the robustness of neural networks. Here, we propose to use attacks as a function evaluation to automatically search for architectures that can resist such attacks. Experiments on neural architecture search algorithms from the literature show that although their accurate results, they are not able to find robust architectures. Most of the reason for this lies in their limited search space. By creating a novel neural architecture search with options for dense layers to connect with convolution layers and vice-versa as well as the addition of multiplication, addition and concatenation layers in the search space, we were able to evolve an architecture that is $58\%$ accurate on adversarial samples. Interestingly, this inherent robustness of the evolved architecture rivals state-of-the-art defenses such as adversarial training while being trained only on the training dataset. Moreover, the evolved architecture makes use of some peculiar traits which might be useful for developing even more robust ones. Thus, the results here demonstrate that more robust architectures exist as well as opens up a new range of possibilities for the development and exploration of deep neural networks using automatic architecture search. Code available at http://bit.ly/RobustArchitectureSearch.
Uncovering Why Deep Neural Networks Lack Robustness: Representation Metrics that Link to Adversarial Attacks
Jun 20, 2019



Neural networks have been shown vulnerable to adversarial samples. Slightly perturbed input images are able to change the classification of accurate models, showing that the representation learned is not as good as previously thought. To aid the development of better neural networks, it would be important to evaluate to what extent are current neural networks' representations capturing the existing features. Here we propose a test that can evaluate neural networks using a new type of zero-shot test, entitled Raw Zero-Shot. This test is based on the principle that some features are present on unknown classes and that unknown classes can be defined as a combination of previous learned features without learning bias. To evaluate the soft-labels of unknown classes, two metrics are proposed. One is based on clustering validation techniques (Davies-Bouldin Index) and the other is based on soft-label distance of a given correct soft-label. Experiments show that such metrics are in accordance with the robustness to adversarial attacks and might serve as a guidance to build better models as well as be used in loss functions to improve the models directly. Interestingly, the results suggests that dynamic routing networks such as CapsNet have better representation while some DNNs might be trading off representation quality for accuracy. Code available at http://bit.ly/RepresentationMetrics.