 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Extraction of Respiratory Waveforms from Photoplethysmography: A Deep Encoder Approach
Dec 22, 2022



Much of the information of breathing is contained within the photoplethysmography (PPG) signal, through changes in venous blood flow, heart rate and stroke volume. We aim to leverage this fact, by employing a novel deep learning framework which is a based on a repurposed convolutional autoencoder. Our model aims to encode all of the relevant respiratory information contained within photoplethysmography waveform, and decode it into a waveform that is similar to a gold standard respiratory reference. The model is employed on two photoplethysmography data sets, namely Capnobase and BIDMC. We show that the model is capable of producing respiratory waveforms that approach the gold standard, while in turn producing state of the art respiratory rate estimates. We also show that when it comes to capturing more advanced respiratory waveform characteristics such as duty cycle, our model is for the most part unsuccessful. A suggested reason for this, in light of a previous study on in-ear PPG, is that the respiratory variations in finger-PPG are far weaker compared with other recording locations. Importantly, our model can perform these waveform estimates in a fraction of a millisecond, giving it the capacity to produce over 6 hours of respiratory waveforms in a single second. Moreover, we attempt to interpret the behaviour of the kernel weights within the model, showing that in part our model intuitively selects different breathing frequencies. The model proposed in this work could help to improve the usefulness of consumer PPG-based wearables for medical applications, where detailed respiratory information is required.
Complexity-based Financial Stress Evaluation
Dec 05, 2022Financial markets typically exhibit dynamically complex properties as they undergo continuous interactions with economic and environmental factors. The Efficient Market Hypothesis indicates a rich difference in the structural complexity of security prices between normal (stable markets) and abnormal (financial crises) situations. Considering the analogy between market undulation of price time series and physical stress of bio-signals, we investigate whether stress indices in bio-systems can be adopted and modified so as to measure 'standard stress' in financial markets. This is achieved by employing structural complexity analysis, based on variants of univariate and multivariate sample entropy, to estimate the stress level of both financial markets on the whole and the performance of the individual financial indices. Further, we propose a novel graphical framework to establish the sensitivity of individual assets and stock markets to financial crises. This is achieved through Catastrophe Theory and entropy-based stress evaluations indicating the unique performance of each index/individual stock in response to different crises. Four major indices and four individual equities with gold prices are considered over the past 32 years from 1991-2021. Our findings based on nonlinear analyses and the proposed framework support the Efficient Market Hypothesis and reveal the relations among economic indices and within each price time series.
Graph-Regularized Tensor Regression: A Domain-Aware Framework for Interpretable Multi-Way Financial Modelling
Oct 26, 2022



Analytics of financial data is inherently a Big Data paradigm, as such data are collected over many assets, asset classes, countries, and time periods. This represents a challenge for modern machine learning models, as the number of model parameters needed to process such data grows exponentially with the data dimensions; an effect known as the Curse-of-Dimensionality. Recently, Tensor Decomposition (TD) techniques have shown promising results in reducing the computational costs associated with large-dimensional financial models while achieving comparable performance. However, tensor models are often unable to incorporate the underlying economic domain knowledge. To this end, we develop a novel Graph-Regularized Tensor Regression (GRTR) framework, whereby knowledge about cross-asset relations is incorporated into the model in the form of a graph Laplacian matrix. This is then used as a regularization tool to promote an economically meaningful structure within the model parameters. By virtue of tensor algebra, the proposed framework is shown to be fully interpretable, both coefficient-wise and dimension-wise. The GRTR model is validated in a multi-way financial forecasting setting and compared against competing models, and is shown to achieve improved performance at reduced computational costs. Detailed visualizations are provided to help the reader gain an intuitive understanding of the employed tensor operations.
Pearl: Parallel Evolutionary and Reinforcement Learning Library
Jan 24, 2022Reinforcement learning is increasingly finding success across domains where the problem can be represented as a Markov decision process. Evolutionary computation algorithms have also proven successful in this domain, exhibiting similar performance to the generally more complex reinforcement learning. Whilst there exist many open-source reinforcement learning and evolutionary computation libraries, no publicly available library combines the two approaches for enhanced comparison, cooperation, or visualization. To this end, we have created Pearl (https://github.com/LondonNode/Pearl), an open source Python library designed to allow researchers to rapidly and conveniently perform optimized reinforcement learning, evolutionary computation and combinations of the two. The key features within Pearl include: modular and expandable components, opinionated module settings, Tensorboard integration, custom callbacks and comprehensive visualizations.
HOTTBOX: Higher Order Tensor ToolBOX
Nov 30, 2021
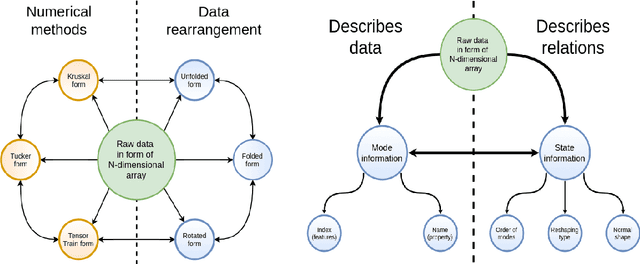
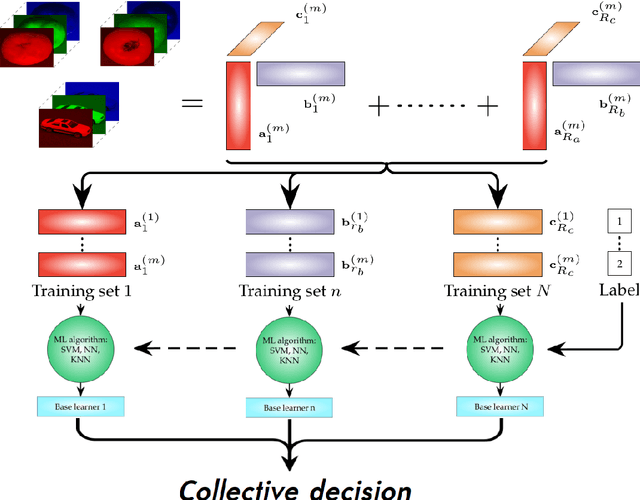
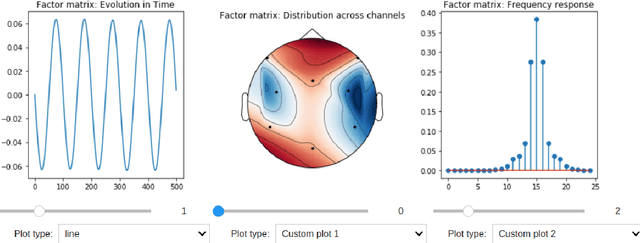
HOTTBOX is a Python library for exploratory analysis and visualisation of multi-dimensional arrays of data, also known as tensors. The library includes methods ranging from standard multi-way operations and data manipulation through to multi-linear algebra based tensor decompositions. HOTTBOX also comprises sophisticated algorithms for generalised multi-linear classification and data fusion, such as Support Tensor Machine (STM) and Tensor Ensemble Learning (TEL). For user convenience, HOTTBOX offers a unifying API which establishes a self-sufficient ecosystem for various forms of efficient representation of multi-way data and the corresponding decomposition and association algorithms. Particular emphasis is placed on scalability and interactive visualisation, to support multidisciplinary data analysis communities working on big data and tensors. HOTTBOX also provides means for integration with other popular data science libraries for visualisation and data manipulation. The source code, examples and documentation ca be found at https://github.com/hottbox/hottbox.
Variational Embedding Multiscale Sample Entropy:complexity-based analysis for multichannel systems
Sep 20, 2021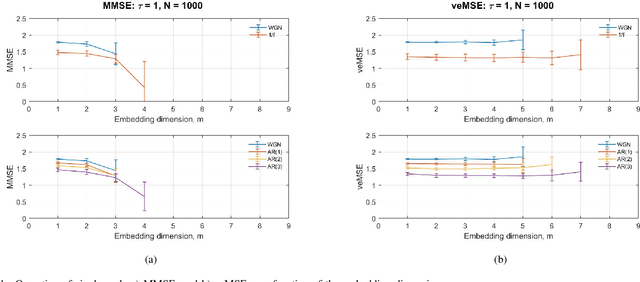
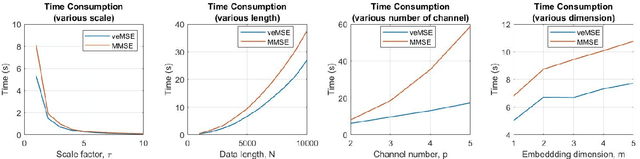
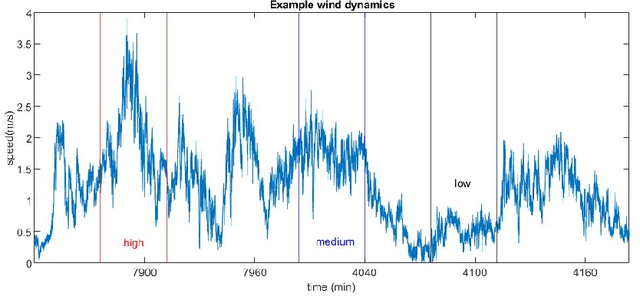
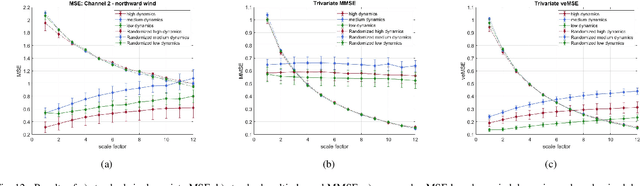
To quantify the complexity of a system, entropy-based methods have received considerable critical attentions in real-world data analysis. Among numerous entropy algorithms, amplitude-based formulas, represented by Sample Entropy, suffer from a limitation of data length especially when it comes to practical scenarios. And this shortcoming is further highlighted by involving coarse graining procedure in multi-scale process. The unbalance between embedding dimension and data size will undoubtedly result in inaccurate and undefined estimation. To that cause, Variational Embedding Multiscale Sample Entropy is proposed in this paper, which assigns signals from various channels with distinct embedding dimensions. And this algorithm is tested by both stimulated and real signals. Furthermore, the performance of the new entropy is investigated and compared with Multivariate Multiscale Sample Entropy and Variational Embedding Multiscale Diversity Entropy. Two real-world database, wind data sets with varying regimes and physiological database recorded from young and elderly people, were utilized. As a result, the proposed algorithm gives an improved separation for both situations.
An Apparatus for the Simulation of Breathing Disorders: Physically Meaningful Generation of Surrogate Data
Sep 14, 2021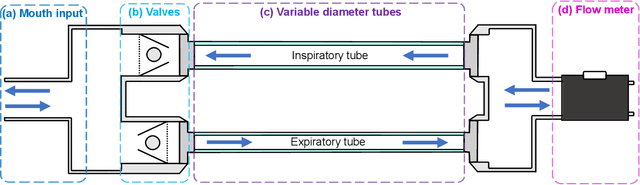
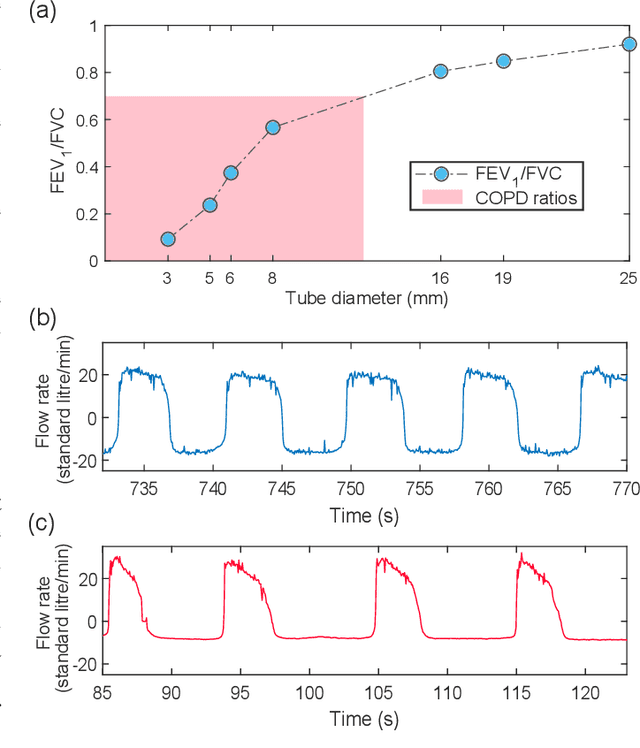
Whilst debilitating breathing disorders, such as chronic obstructive pulmonary disease (COPD), are rapidly increasing in prevalence, we witness a continued integration of artificial intelligence into healthcare. While this promises improved detection and monitoring of breathing disorders, AI techniques are "data hungry" which highlights the importance of generating physically meaningful surrogate data. Such domain knowledge aware surrogates would enable both an improved understanding of respiratory waveform changes with different breathing disorders and different severities, and enhance the training of machine learning algorithms. To this end, we introduce an apparatus comprising of PVC tubes and 3D printed parts as a simple yet effective method of simulating both obstructive and restrictive respiratory waveforms in healthy subjects. Independent control over both inspiratory and expiratory resistances allows for the simulation of obstructive breathing disorders through the whole spectrum of FEV1/FVC spirometry ratios (used to classify COPD), ranging from healthy values to values seen in severe chronic obstructive pulmonary disease. Moreover, waveform characteristics of breathing disorders, such as a change in inspiratory duty cycle or peak flow are also observed in the waveforms resulting from use of the artificial breathing disorder simulation apparatus. Overall, the proposed apparatus provides us with a simple, effective and physically meaningful way to generate surrogate breathing disorder waveforms, a prerequisite for the use of artificial intelligence in respiratory health.
Dynamic Portfolio Cuts: A Spectral Approach to Graph-Theoretic Diversification
Jun 07, 2021

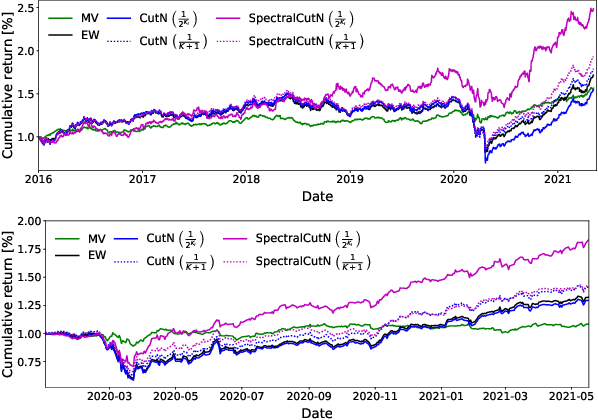
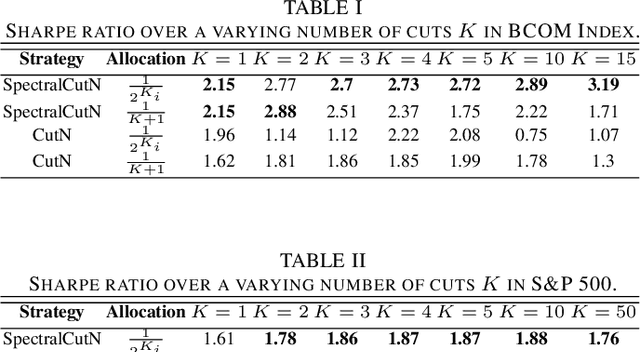
Stock market returns are typically analyzed using standard regression, yet they reside on irregular domains which is a natural scenario for graph signal processing. To this end, we consider a market graph as an intuitive way to represent the relationships between financial assets. Traditional methods for estimating asset-return covariance operate under the assumption of statistical time-invariance, and are thus unable to appropriately infer the underlying true structure of the market graph. This work introduces a class of graph spectral estimators which cater for the nonstationarity inherent to asset price movements, and serve as a basis to represent the time-varying interactions between assets through a dynamic spectral market graph. Such an account of the time-varying nature of the asset-return covariance allows us to introduce the notion of dynamic spectral portfolio cuts, whereby the graph is partitioned into time-evolving clusters, allowing for online and robust asset allocation. The advantages of the proposed framework over traditional methods are demonstrated through numerical case studies using real-world price data.
Graph Theory for Metro Traffic Modelling
May 11, 2021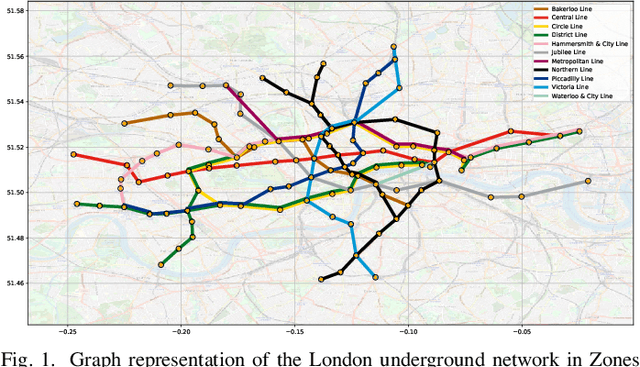
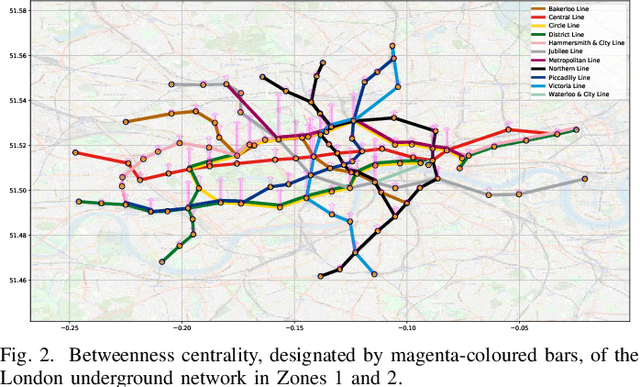
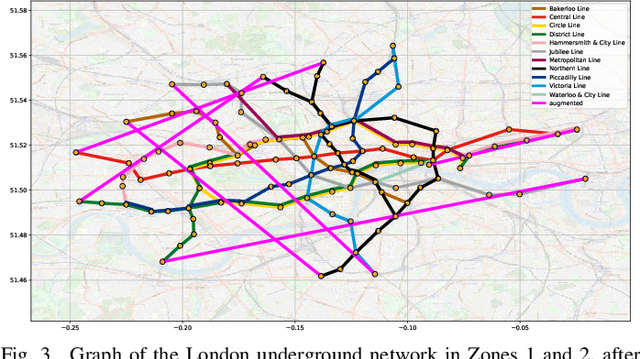
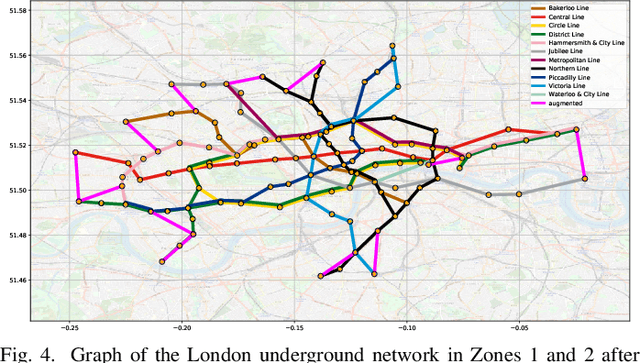
A unifying graph theoretic framework for the modelling of metro transportation networks is proposed. This is achieved by first introducing a basic graph framework for the modelling of the London underground system from a diffusion law point of view. This forms a basis for the analysis of both station importance and their vulnerability, whereby the concept of graph vertex centrality plays a key role. We next explore k-edge augmentation of a graph topology, and illustrate its usefulness both for improving the network robustness and as a planning tool. Upon establishing the graph theoretic attributes of the underlying graph topology, we proceed to introduce models for processing data on such a metro graph. Commuter movement is shown to obey the Fick's law of diffusion, where the graph Laplacian provides an analytical model for the diffusion process of commuter population dynamics. Finally, we also explore the application of modern deep learning models, such as graph neural networks and hyper-graph neural networks, as general purpose models for the modelling and forecasting of underground data, especially in the context of the morning and evening rush hours. Comprehensive simulations including the passenger in- and out-flows during the morning rush hour in London demonstrates the advantages of the graph models in metro planning and traffic management, a formal mathematical approach with wide economic implications.
Tensor-Train Recurrent Neural Networks for Interpretable Multi-Way Financial Forecasting
May 11, 2021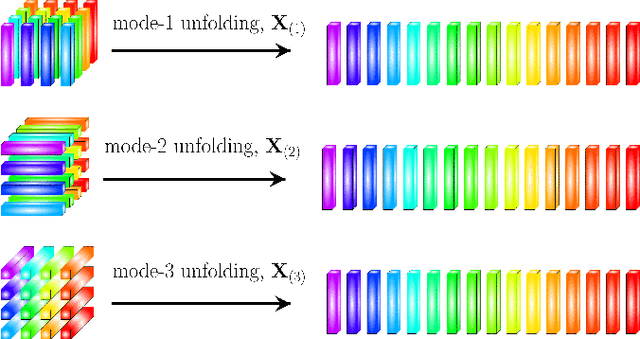
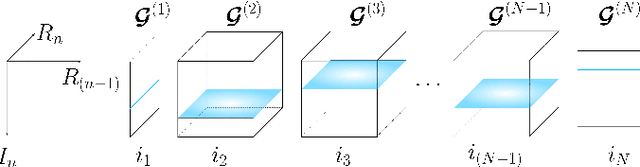

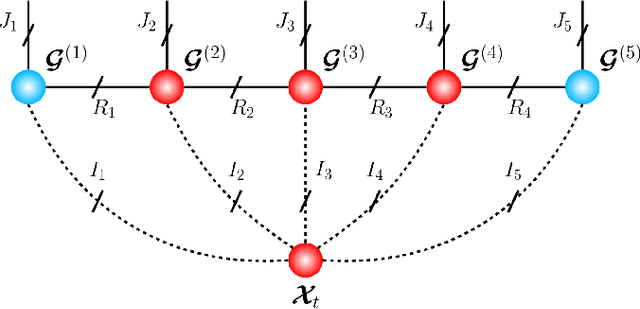
Recurrent Neural Networks (RNNs) represent the de facto standard machine learning tool for sequence modelling, owing to their expressive power and memory. However, when dealing with large dimensional data, the corresponding exponential increase in the number of parameters imposes a computational bottleneck. The necessity to equip RNNs with the ability to deal with the curse of dimensionality, such as through the parameter compression ability inherent to tensors, has led to the development of the Tensor-Train RNN (TT-RNN). Despite achieving promising results in many applications, the full potential of the TT-RNN is yet to be explored in the context of interpretable financial modelling, a notoriously challenging task characterized by multi-modal data with low signal-to-noise ratio. To address this issue, we investigate the potential of TT-RNN in the task of financial forecasting of currencies. We show, through the analysis of TT-factors, that the physical meaning underlying tensor decomposition, enables the TT-RNN model to aid the interpretability of results, thus mitigating the notorious "black-box" issue associated with neural networks. Furthermore, simulation results highlight the regularization power of TT decomposition, demonstrating the superior performance of TT-RNN over its uncompressed RNN counterpart and other tensor forecasting methods.