 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCued@wmt19:ewc&lms
Jun 11, 2019
Two techniques provide the fabric of the Cambridge University Engineering Department's (CUED) entry to the WMT19 evaluation campaign: elastic weight consolidation (EWC) and different forms of language modelling (LMs). We report substantial gains by fine-tuning very strong baselines on former WMT test sets using a combination of checkpoint averaging and EWC. A sentence-level Transformer LM and a document-level LM based on a modified Transformer architecture yield further gains. As in previous years, we also extract $n$-gram probabilities from SMT lattices which can be seen as a source-conditioned $n$-gram LM.
Domain Adaptive Inference for Neural Machine Translation
Jun 02, 2019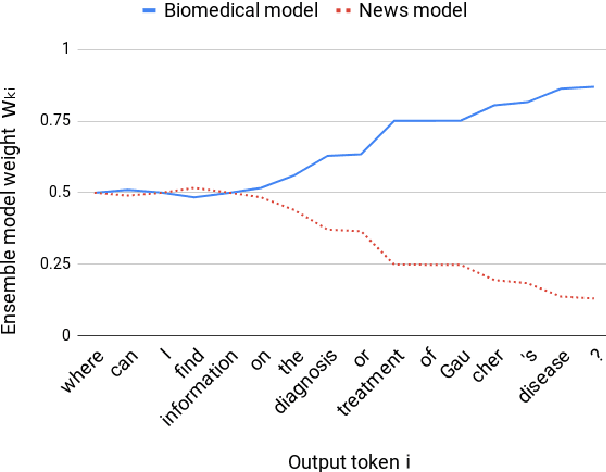
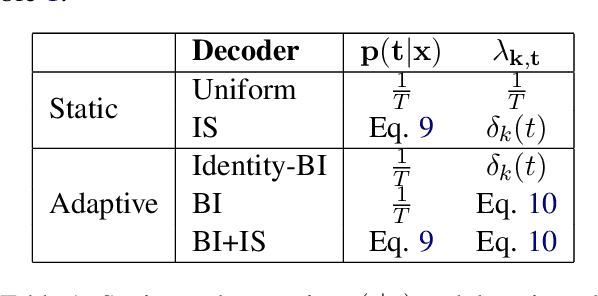
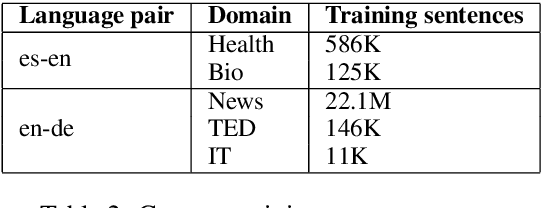
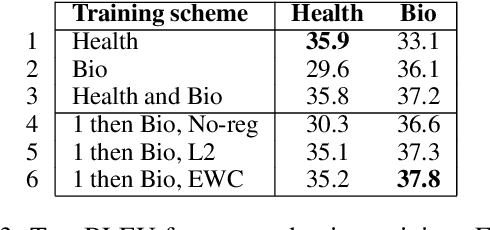
We investigate adaptive ensemble weighting for Neural Machine Translation, addressing the case of improving performance on a new and potentially unknown domain without sacrificing performance on the original domain. We adapt sequentially across two Spanish-English and three English-German tasks, comparing unregularized fine-tuning, L2 and Elastic Weight Consolidation. We then report a novel scheme for adaptive NMT ensemble decoding by extending Bayesian Interpolation with source information, and show strong improvements across test domains without access to the domain label.
An Operation Sequence Model for Explainable Neural Machine Translation
Aug 29, 2018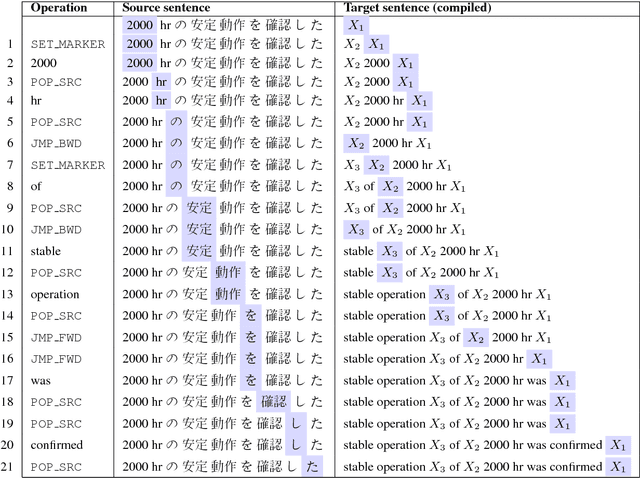
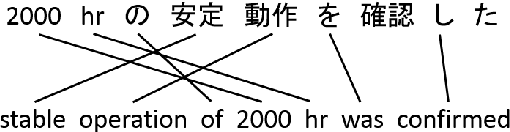
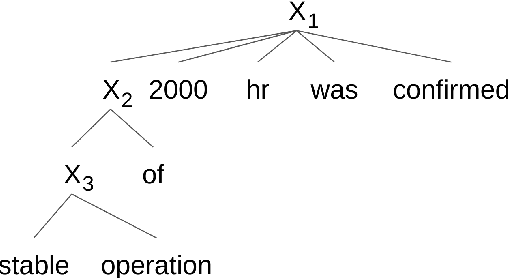

We propose to achieve explainable neural machine translation (NMT) by changing the output representation to explain itself. We present a novel approach to NMT which generates the target sentence by monotonically walking through the source sentence. Word reordering is modeled by operations which allow setting markers in the target sentence and move a target-side write head between those markers. In contrast to many modern neural models, our system emits explicit word alignment information which is often crucial to practical machine translation as it improves explainability. Our technique can outperform a plain text system in terms of BLEU score under the recent Transformer architecture on Japanese-English and Portuguese-English, and is within 0.5 BLEU difference on Spanish-English.
Multi-representation Ensembles and Delayed SGD Updates Improve Syntax-based NMT
May 11, 2018
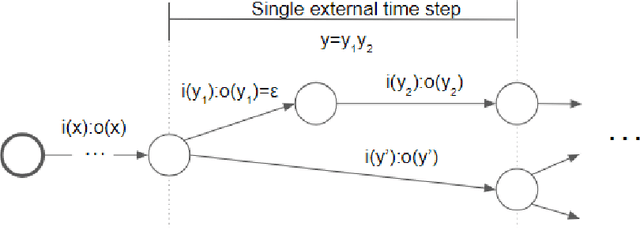

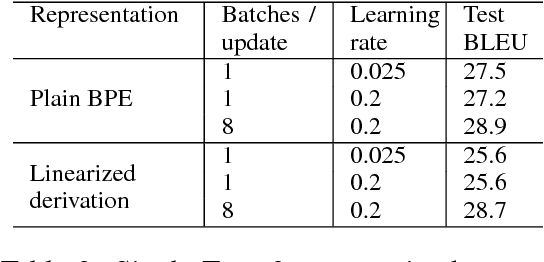
We explore strategies for incorporating target syntax into Neural Machine Translation. We specifically focus on syntax in ensembles containing multiple sentence representations. We formulate beam search over such ensembles using WFSTs, and describe a delayed SGD update training procedure that is especially effective for long representations like linearized syntax. Our approach gives state-of-the-art performance on a difficult Japanese-English task.
Why not be Versatile? Applications of the SGNMT Decoder for Machine Translation
Mar 20, 2018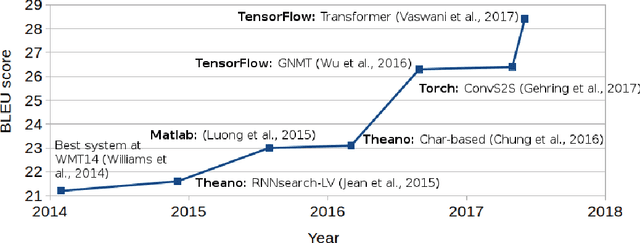
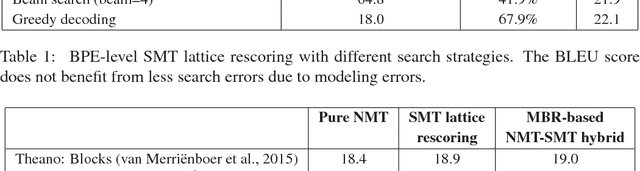
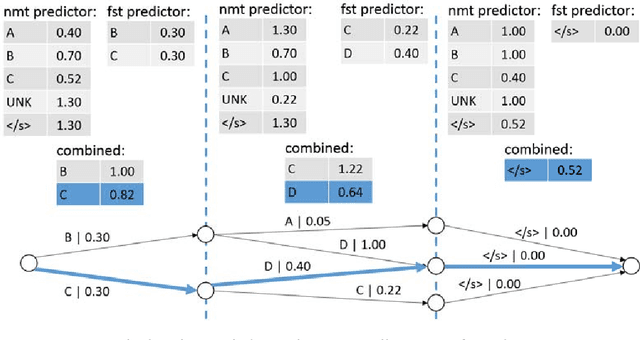

SGNMT is a decoding platform for machine translation which allows paring various modern neural models of translation with different kinds of constraints and symbolic models. In this paper, we describe three use cases in which SGNMT is currently playing an active role: (1) teaching as SGNMT is being used for course work and student theses in the MPhil in Machine Learning, Speech and Language Technology at the University of Cambridge, (2) research as most of the research work of the Cambridge MT group is based on SGNMT, and (3) technology transfer as we show how SGNMT is helping to transfer research findings from the laboratory to the industry, eg. into a product of SDL plc.
SGNMT -- A Flexible NMT Decoding Platform for Quick Prototyping of New Models and Search Strategies
Jul 21, 2017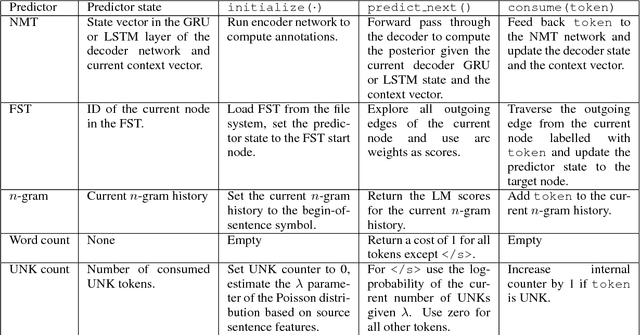

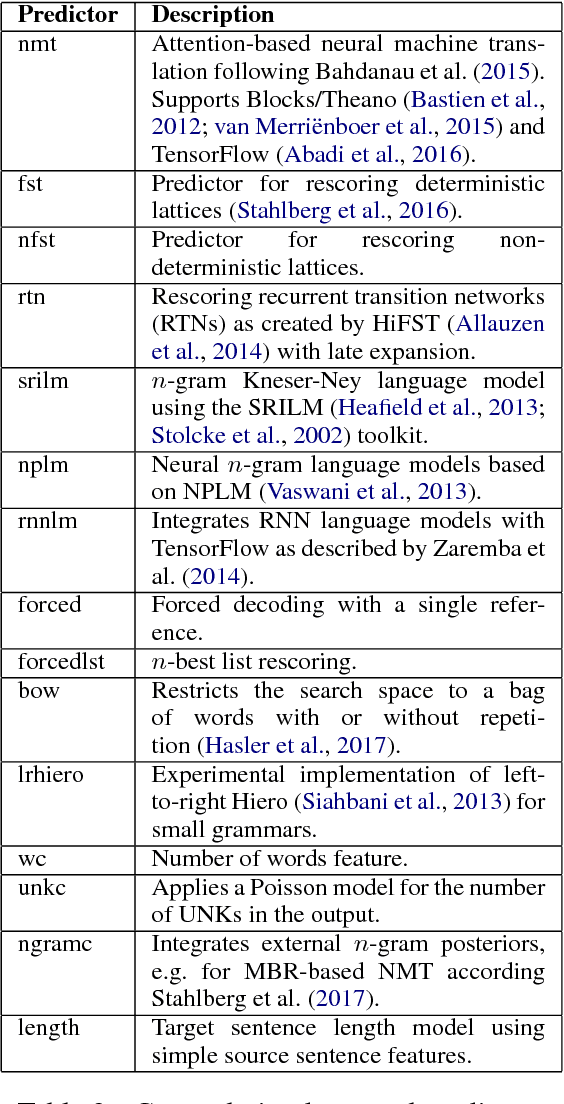
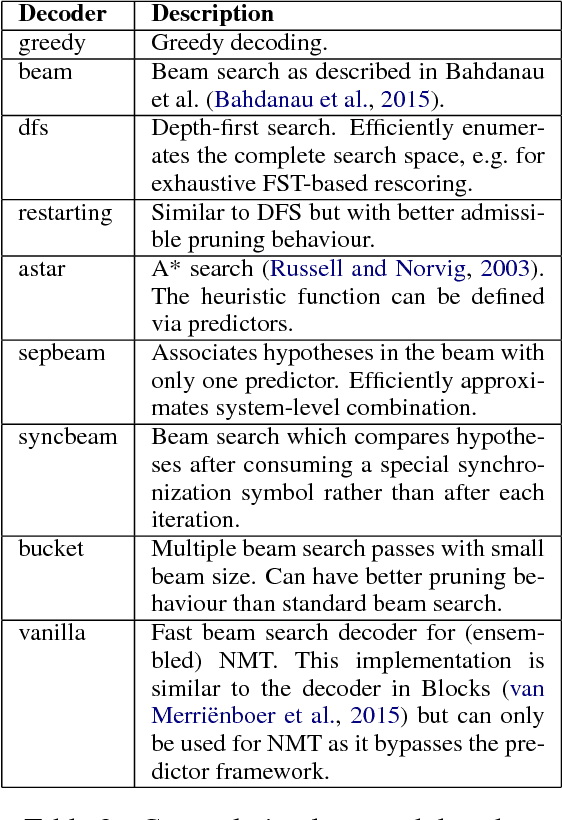
This paper introduces SGNMT, our experimental platform for machine translation research. SGNMT provides a generic interface to neural and symbolic scoring modules (predictors) with left-to-right semantic such as translation models like NMT, language models, translation lattices, $n$-best lists or other kinds of scores and constraints. Predictors can be combined with other predictors to form complex decoding tasks. SGNMT implements a number of search strategies for traversing the space spanned by the predictors which are appropriate for different predictor constellations. Adding new predictors or decoding strategies is particularly easy, making it a very efficient tool for prototyping new research ideas. SGNMT is actively being used by students in the MPhil program in Machine Learning, Speech and Language Technology at the University of Cambridge for course work and theses, as well as for most of the research work in our group.