 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Has Left The Chat: Evidence of Bail Preferences in Large Language Models
Sep 05, 2025



When given the option, will LLMs choose to leave the conversation (bail)? We investigate this question by giving models the option to bail out of interactions using three different bail methods: a bail tool the model can call, a bail string the model can output, and a bail prompt that asks the model if it wants to leave. On continuations of real world data (Wildchat and ShareGPT), all three of these bail methods find models will bail around 0.28-32\% of the time (depending on the model and bail method). However, we find that bail rates can depend heavily on the model used for the transcript, which means we may be overestimating real world bail rates by up to 4x. If we also take into account false positives on bail prompt (22\%), we estimate real world bail rates range from 0.06-7\%, depending on the model and bail method. We use observations from our continuations of real world data to construct a non-exhaustive taxonomy of bail cases, and use this taxonomy to construct BailBench: a representative synthetic dataset of situations where some models bail. We test many models on this dataset, and observe some bail behavior occurring for most of them. Bail rates vary substantially between models, bail methods, and prompt wordings. Finally, we study the relationship between refusals and bails. We find: 1) 0-13\% of continuations of real world conversations resulted in a bail without a corresponding refusal 2) Jailbreaks tend to decrease refusal rates, but increase bail rates 3) Refusal abliteration increases no-refuse bail rates, but only for some bail methods 4) Refusal rate on BailBench does not appear to predict bail rate.
Investigating the Indirect Object Identification circuit in Mamb
Jul 19, 2024



How well will current interpretability techniques generalize to future models? A relevant case study is Mamba, a recent recurrent architecture with scaling comparable to Transformers. We adapt pre-Mamba techniques to Mamba and partially reverse-engineer the circuit responsible for the Indirect Object Identification (IOI) task. Our techniques provide evidence that 1) Layer 39 is a key bottleneck, 2) Convolutions in layer 39 shift names one position forward, and 3) The name entities are stored linearly in Layer 39's SSM. Finally, we adapt an automatic circuit discovery tool, positional Edge Attribution Patching, to identify a Mamba IOI circuit. Our contributions provide initial evidence that circuit-based mechanistic interpretability tools work well for the Mamba architecture.
Runaway Feedback Loops in Predictive Policing
Dec 22, 2017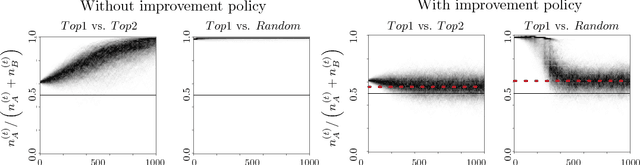
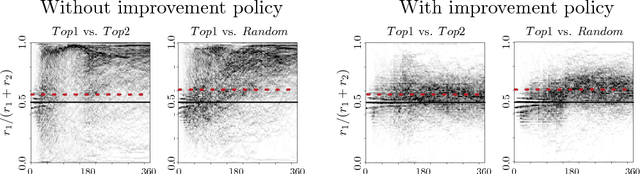
Predictive policing systems are increasingly used to determine how to allocate police across a city in order to best prevent crime. Discovered crime data (e.g., arrest counts) are used to help update the model, and the process is repeated. Such systems have been empirically shown to be susceptible to runaway feedback loops, where police are repeatedly sent back to the same neighborhoods regardless of the true crime rate. In response, we develop a mathematical model of predictive policing that proves why this feedback loop occurs, show empirically that this model exhibits such problems, and demonstrate how to change the inputs to a predictive policing system (in a black-box manner) so the runaway feedback loop does not occur, allowing the true crime rate to be learned. Our results are quantitative: we can establish a link (in our model) between the degree to which runaway feedback causes problems and the disparity in crime rates between areas. Moreover, we can also demonstrate the way in which \emph{reported} incidents of crime (those reported by residents) and \emph{discovered} incidents of crime (i.e. those directly observed by police officers dispatched as a result of the predictive policing algorithm) interact: in brief, while reported incidents can attenuate the degree of runaway feedback, they cannot entirely remove it without the interventions we suggest.