 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Preference Multi-Objective Reinforcement Learning for Internet Network Management
Jun 16, 2025An internet network service provider manages its network with multiple objectives, such as high quality of service (QoS) and minimum computing resource usage. To achieve these objectives, a reinforcement learning-based (RL) algorithm has been proposed to train its network management agent. Usually, their algorithms optimize their agents with respect to a single static reward formulation consisting of multiple objectives with fixed importance factors, which we call preferences. However, in practice, the preference could vary according to network status, external concerns and so on. For example, when a server shuts down and it can cause other servers' traffic overloads leading to additional shutdowns, it is plausible to reduce the preference of QoS while increasing the preference of minimum computing resource usages. In this paper, we propose new RL-based network management agents that can select actions based on both states and preferences. With our proposed approach, we expect a single agent to generalize on various states and preferences. Furthermore, we propose a numerical method that can estimate the distribution of preference that is advantageous for unbiased training. Our experiment results show that the RL agents trained based on our proposed approach significantly generalize better with various preferences than the previous RL approaches, which assume static preference during training. Moreover, we demonstrate several analyses that show the advantages of our numerical estimation method.
N-gram Prediction and Word Difference Representations for Language Modeling
Sep 05, 2024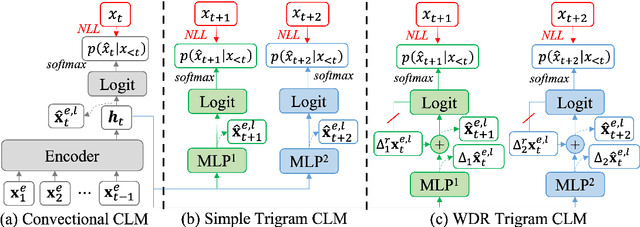
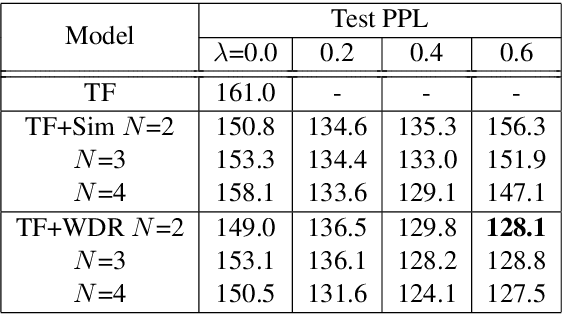

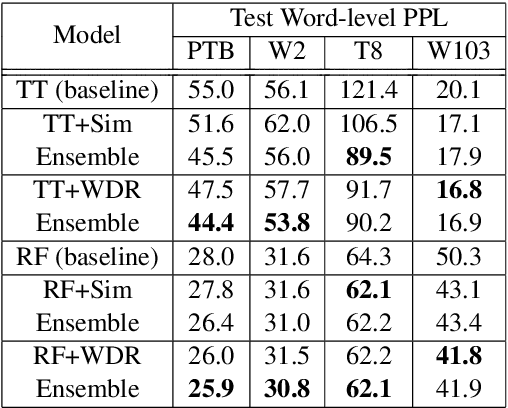
Causal language modeling (CLM) serves as the foundational framework underpinning remarkable successes of recent large language models (LLMs). Despite its success, the training approach for next word prediction poses a potential risk of causing the model to overly focus on local dependencies within a sentence. While prior studies have been introduced to predict future N words simultaneously, they were primarily applied to tasks such as masked language modeling (MLM) and neural machine translation (NMT). In this study, we introduce a simple N-gram prediction framework for the CLM task. Moreover, we introduce word difference representation (WDR) as a surrogate and contextualized target representation during model training on the basis of N-gram prediction framework. To further enhance the quality of next word prediction, we propose an ensemble method that incorporates the future N words' prediction results. Empirical evaluations across multiple benchmark datasets encompassing CLM and NMT tasks demonstrate the significant advantages of our proposed methods over the conventional CLM.