 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMOR: Automated Peer Review Generation with LLM Reasoning and Multi-Objective Reinforcement Learning
May 16, 2025AI-based peer review systems tend to produce shallow and overpraising suggestions compared to human feedback. Here, we evaluate how well a reasoning LLM trained with multi-objective reinforcement learning (REMOR) can overcome these limitations. We start by designing a multi-aspect reward function that aligns with human evaluation of reviews. The aspects are related to the review itself (e.g., criticisms, novelty) and the relationship between the review and the manuscript (i.e., relevance). First, we perform supervised fine-tuning of DeepSeek-R1-Distill-Qwen-7B using LoRA on PeerRT, a new dataset of high-quality top AI conference reviews enriched with reasoning traces. We then apply Group Relative Policy Optimization (GRPO) to train two models: REMOR-H (with the human-aligned reward) and REMOR-U (with a uniform reward). Interestingly, the human-aligned reward penalizes aspects typically associated with strong reviews, leading REMOR-U to produce qualitatively more substantive feedback. Our results show that REMOR-U and REMOR-H achieve more than twice the average rewards of human reviews, non-reasoning state-of-the-art agentic multi-modal AI review systems, and general commercial LLM baselines. We found that while the best AI and human reviews are comparable in quality, REMOR avoids the long tail of low-quality human reviews. We discuss how reasoning is key to achieving these improvements and release the Human-aligned Peer Review Reward (HPRR) function, the Peer Review Reasoning-enriched Traces (PeerRT) dataset, and the REMOR models, which we believe can help spur progress in the area.
Dataset Mention Extraction in Scientific Articles Using Bi-LSTM-CRF Model
May 21, 2024Datasets are critical for scientific research, playing an important role in replication, reproducibility, and efficiency. Researchers have recently shown that datasets are becoming more important for science to function properly, even serving as artifacts of study themselves. However, citing datasets is not a common or standard practice in spite of recent efforts by data repositories and funding agencies. This greatly affects our ability to track their usage and importance. A potential solution to this problem is to automatically extract dataset mentions from scientific articles. In this work, we propose to achieve such extraction by using a neural network based on a Bi-LSTM-CRF architecture. Our method achieves F1 = 0.885 in social science articles released as part of the Rich Context Dataset. We discuss the limitations of the current datasets and propose modifications to the model to be done in the future.
Claim Extraction in Biomedical Publications using Deep Discourse Model and Transfer Learning
Jul 01, 2019
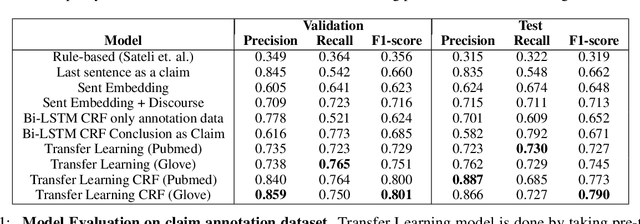
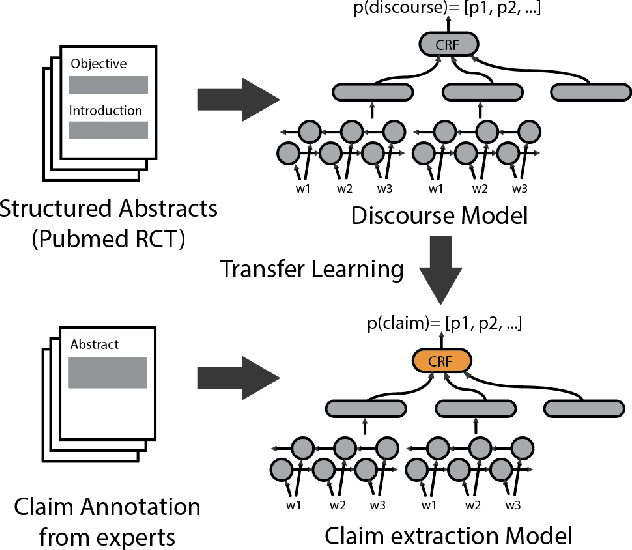
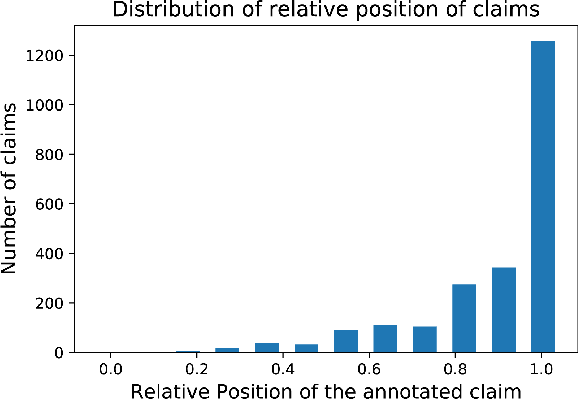
Claims are a fundamental unit of scientific discourse. The exponential growth in the number of scientific publications makes automatic claim extraction an important problem for researchers who are overwhelmed by this information overload. Such an automated claim extraction system is useful for both manual and programmatic exploration of scientific knowledge. In this paper, we introduce an online claim extraction system and a dataset of 1,500 scientific abstracts from the biomedical domain with expert annotations for each sentence indicating whether the sentence presents a scientific claim. We compare our proposed model with several baseline models including rule-based and deep learning techniques. Our transfer learning approach with a fine-tuning step allows us to bootstrap from a large discourse-annotated dataset (Pubmed-RCT) and obtains F1-score over 0.78 for claim detection while using a small annotated dataset of 750 papers. We show that using this pre-trained model based on the discourse prediction task improves F1-score by over 14 percent absolute points compared to a baseline model without discourse structure. We release a publicly accessible tool for discourse model, claim detection model, along with an annotation tool. We discuss further applications beyond Biomedical literature.
A high-reproducibility and high-accuracy method for automated topic classification
Feb 03, 2014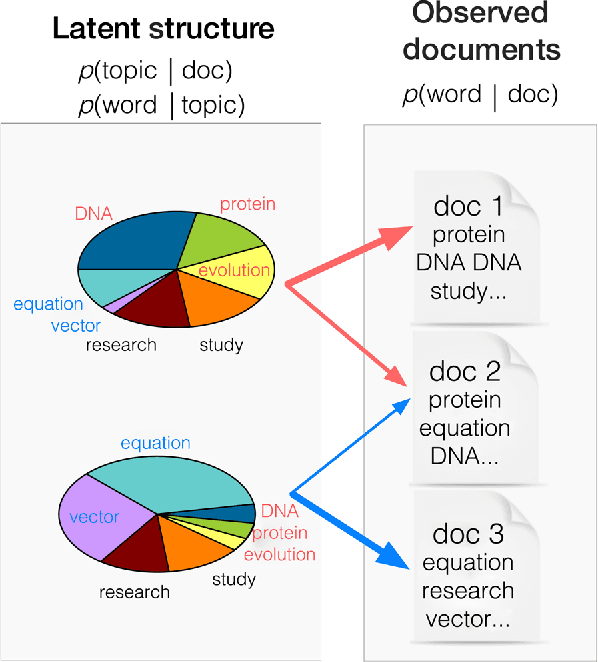
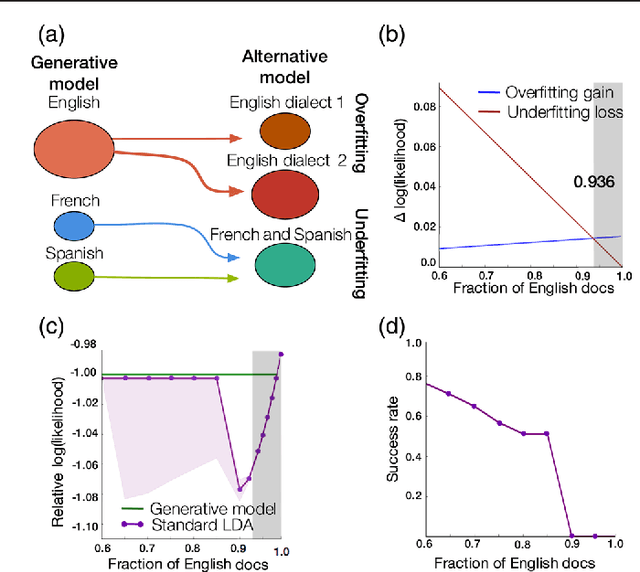
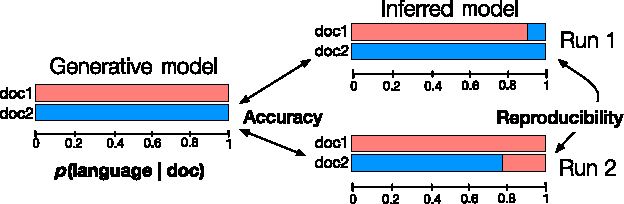
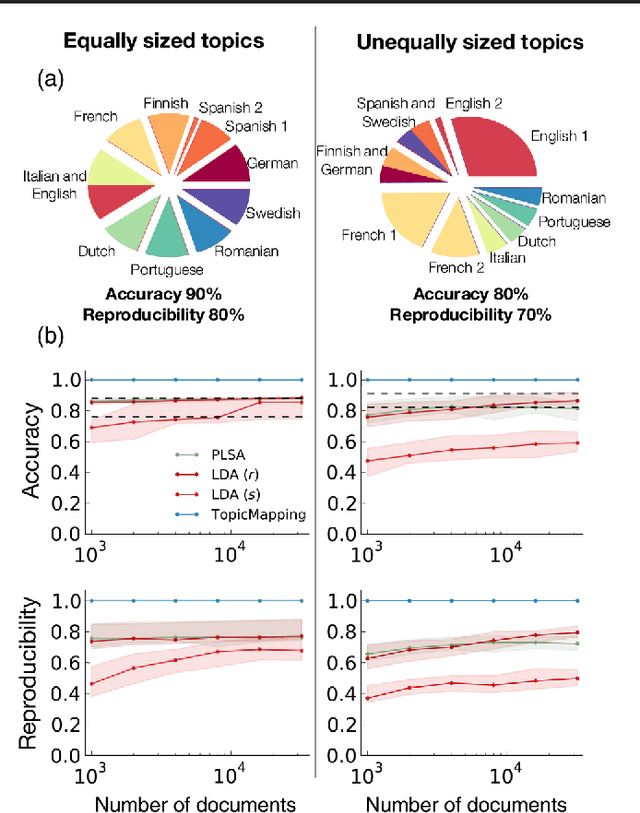
Much of human knowledge sits in large databases of unstructured text. Leveraging this knowledge requires algorithms that extract and record metadata on unstructured text documents. Assigning topics to documents will enable intelligent search, statistical characterization, and meaningful classification. Latent Dirichlet allocation (LDA) is the state-of-the-art in topic classification. Here, we perform a systematic theoretical and numerical analysis that demonstrates that current optimization techniques for LDA often yield results which are not accurate in inferring the most suitable model parameters. Adapting approaches for community detection in networks, we propose a new algorithm which displays high-reproducibility and high-accuracy, and also has high computational efficiency. We apply it to a large set of documents in the English Wikipedia and reveal its hierarchical structure. Our algorithm promises to make "big data" text analysis systems more reliable.