 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearized Bregman Iterations for Sparse Spiking Neural Networks
Mar 17, 2026Spiking Neural Networks (SNNs) offer an energy efficient alternative to conventional Artificial Neural Networks (ANNs) but typically still require a large number of parameters. This work introduces Linearized Bregman Iterations (LBI) as an optimizer for training SNNs, enforcing sparsity through iterative minimization of the Bregman distance and proximal soft thresholding updates. To improve convergence and generalization, we employ the AdaBreg optimizer, a momentum and bias corrected Bregman variant of Adam. Experiments on three established neuromorphic benchmarks, i.e. the Spiking Heidelberg Digits (SHD), the Spiking Speech Commands (SSC), and the Permuted Sequential MNIST (PSMNIST) datasets, show that LBI based optimization reduces the number of active parameters by about 50% while maintaining accuracy comparable to models trained with the Adam optimizer, demonstrating the potential of convex sparsity inducing methods for efficient neuromorphic learning.
Lightweight LIF-only SNN accelerator using differential time encoding
May 16, 2025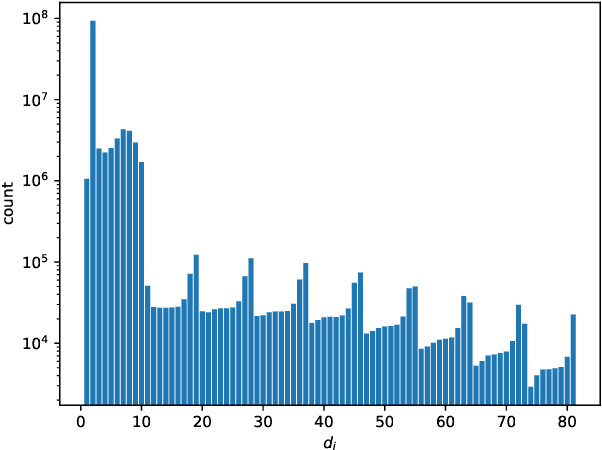
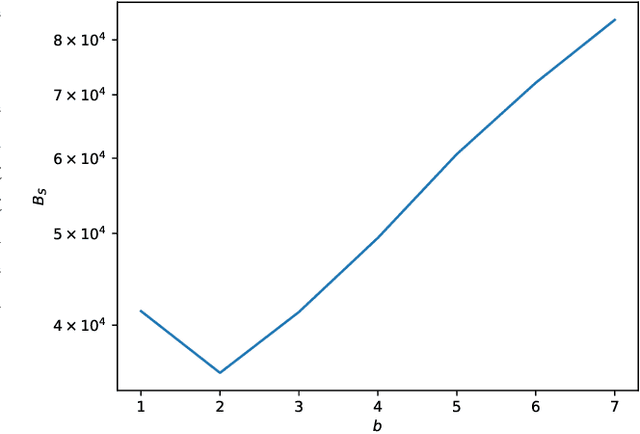
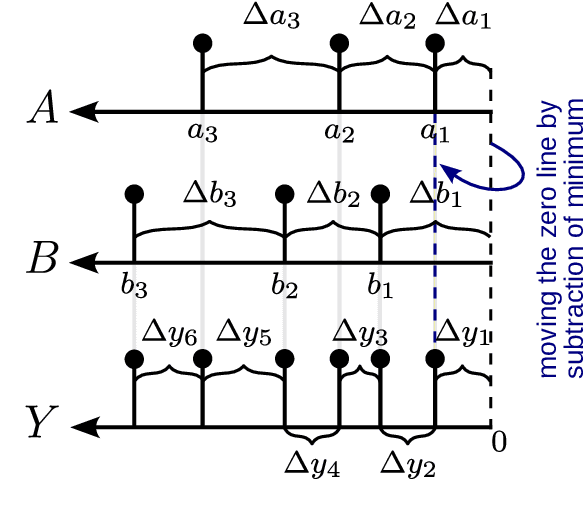
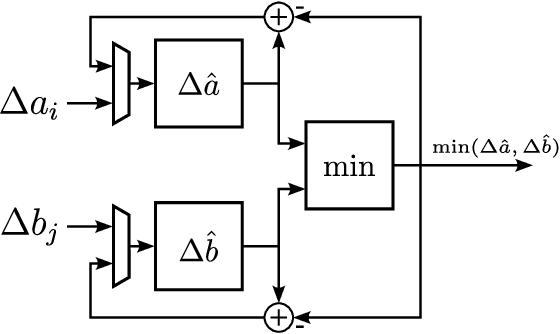
Spiking Neural Networks (SNNs) offer a promising solution to the problem of increasing computational and energy requirements for modern Machine Learning (ML) applications. Due to their unique data representation choice of using spikes and spike trains, they mostly rely on additions and thresholding operations to achieve results approaching state-of-the-art (SOTA) Artificial Neural Networks (ANNs). This advantage is hindered by the fact that their temporal characteristic does not map well to already existing accelerator hardware like GPUs. Therefore, this work will introduce a hardware accelerator architecture capable of computing feedforward LIF-only SNNs, as well as an accompanying encoding method to efficiently encode already existing data into spike trains. Together, this leads to a design capable of >99% accuracy on the MNIST dataset, with ~0.29ms inference times on a Xilinx Ultrascale+ FPGA, as well as ~0.17ms on a custom ASIC using the open-source predictive 7nm ASAP7 PDK. Furthermore, this work will showcase the advantages of the previously presented differential time encoding for spikes, as well as provide proof that merging spikes from different synapses given in differential time encoding can be done efficiently in hardware.
Spiking Neural Network Accelerator Architecture for Differential-Time Representation using Learned Encoding
Jan 14, 2025



Spiking Neural Networks (SNNs) have garnered attention over recent years due to their increased energy efficiency and advantages in terms of operational complexity compared to traditional Artificial Neural Networks (ANNs). Two important questions when implementing SNNs are how to best encode existing data into spike trains and how to efficiently process these spike trains in hardware. This paper addresses both of these problems by incorporating the encoding into the learning process, thus allowing the network to learn the spike encoding alongside the weights. Furthermore, this paper proposes a hardware architecture based on a recently introduced differential-time representation for spike trains allowing decoupling of spike time and processing time. Together these contributions lead to a feedforward SNN using only Leaky-Integrate and Fire (LIF) neurons that surpasses 99% accuracy on the MNIST dataset while still being implementable on medium-sized FPGAs with inference times of less than 295us.
Soil analysis with machine-learning-based processing of stepped-frequency GPR field measurements: Preliminary study
Apr 24, 2024Ground Penetrating Radar (GPR) has been widely studied as a tool for extracting soil parameters relevant to agriculture and horticulture. When combined with Machine-Learning-based (ML) methods, high-resolution Stepped Frequency Countinuous Wave Radar (SFCW) measurements hold the promise to give cost effective access to depth resolved soil parameters, including at root-level depth. In a first step in this direction, we perform an extensive field survey with a tractor mounted SFCW GPR instrument. Using ML data processing we test the GPR instrument's capabilities to predict the apparent electrical conductivity (ECaR) as measured by a simultaneously recording Electromagnetic Induction (EMI) instrument. The large-scale field measurement campaign with 3472 co-registered and geo-located GPR and EMI data samples distributed over ~6600 square meters was performed on a golf course. The selected terrain benefits from a high surface homogeneity, but also features the challenge of only small, and hence hard to discern, variations in the measured soil parameter. Based on the quantitative results we suggest the use of nugget-to-sill ratio as a performance metric for the evaluation of end-to-end ML performance in the agricultural setting and discuss the limiting factors in the multi-sensor regression setting. The code is released as open source and available at https://opensource.silicon-austria.com/xuc/soil-analysis-machine-learning-stepped-frequency-gpr.
SNN Architecture for Differential Time Encoding Using Decoupled Processing Time
Nov 24, 2023Spiking neural networks (SNNs) have gained attention in recent years due to their ability to handle sparse and event-based data better than regular artificial neural networks (ANNs). Since the structure of SNNs is less suited for typically used accelerators such as GPUs than conventional ANNs, there is a demand for custom hardware accelerators for processing SNNs. In the past, the main focus was on platforms that resemble the structure of multiprocessor systems. In this work, we propose a lightweight neuron layer architecture that allows network structures to be directly mapped onto digital hardware. Our approach is based on differential time coding of spike sequences and the decoupling of processing time and spike timing that allows the SNN to be processed on different hardware platforms. We present synthesis and performance results showing that this architecture can be implemented for networks of more than 1000 neurons with high clock speeds on a State-of-the-Art FPGA. We furthermore show results on the robustness of our approach to quantization. These results demonstrate that high-accuracy inference can be performed with bit widths as low as 4.