 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Foundations of Graph-Based Bayesian Semi-Supervised Learning
Jul 03, 2022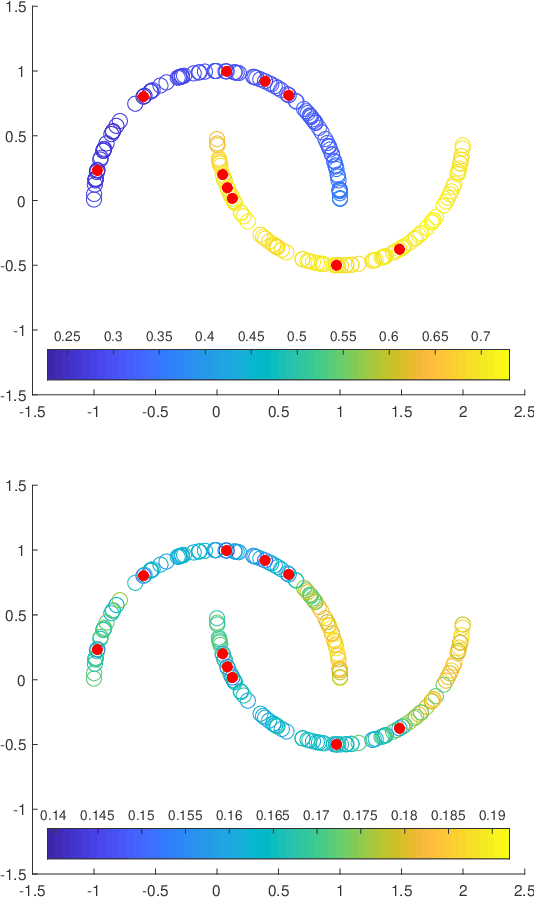
In recent decades, science and engineering have been revolutionized by a momentous growth in the amount of available data. However, despite the unprecedented ease with which data are now collected and stored, labeling data by supplementing each feature with an informative tag remains to be challenging. Illustrative tasks where the labeling process requires expert knowledge or is tedious and time-consuming include labeling X-rays with a diagnosis, protein sequences with a protein type, texts by their topic, tweets by their sentiment, or videos by their genre. In these and numerous other examples, only a few features may be manually labeled due to cost and time constraints. How can we best propagate label information from a small number of expensive labeled features to a vast number of unlabeled ones? This is the question addressed by semi-supervised learning (SSL). This article overviews recent foundational developments on graph-based Bayesian SSL, a probabilistic framework for label propagation using similarities between features. SSL is an active research area and a thorough review of the extant literature is beyond the scope of this article. Our focus will be on topics drawn from our own research that illustrate the wide range of mathematical tools and ideas that underlie the rigorous study of the statistical accuracy and computational efficiency of graph-based Bayesian SSL.
A Variational Inference Approach to Inverse Problems with Gamma Hyperpriors
Nov 29, 2021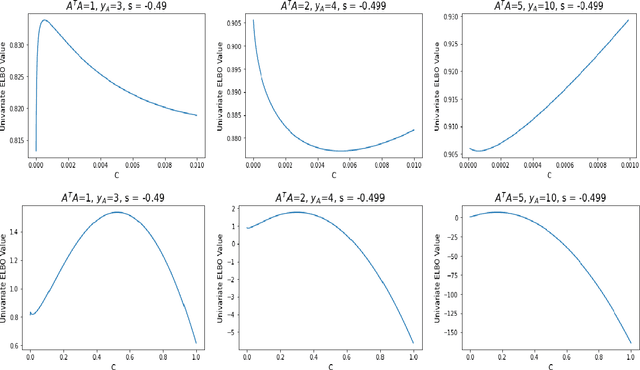

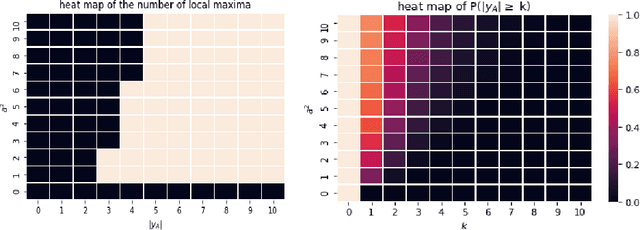
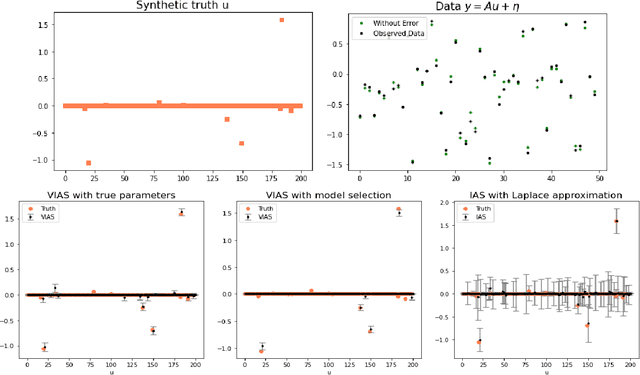
Hierarchical models with gamma hyperpriors provide a flexible, sparse-promoting framework to bridge $L^1$ and $L^2$ regularizations in Bayesian formulations to inverse problems. Despite the Bayesian motivation for these models, existing methodologies are limited to \textit{maximum a posteriori} estimation. The potential to perform uncertainty quantification has not yet been realized. This paper introduces a variational iterative alternating scheme for hierarchical inverse problems with gamma hyperpriors. The proposed variational inference approach yields accurate reconstruction, provides meaningful uncertainty quantification, and is easy to implement. In addition, it lends itself naturally to conduct model selection for the choice of hyperparameters. We illustrate the performance of our methodology in several computed examples, including a deconvolution problem and sparse identification of dynamical systems from time series data.
Auto-differentiable Ensemble Kalman Filters
Jul 19, 2021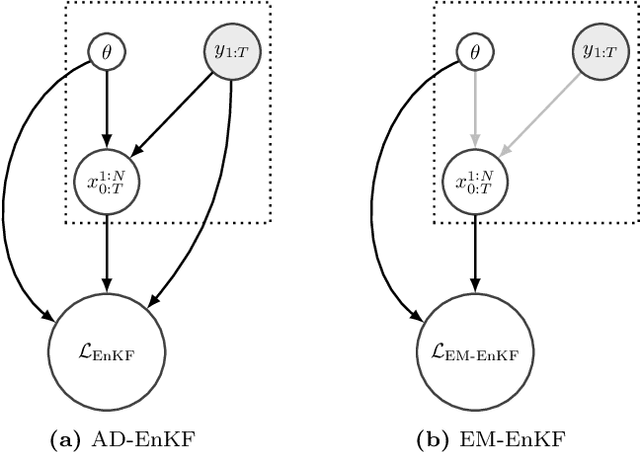
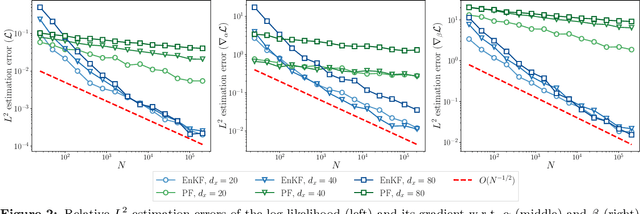
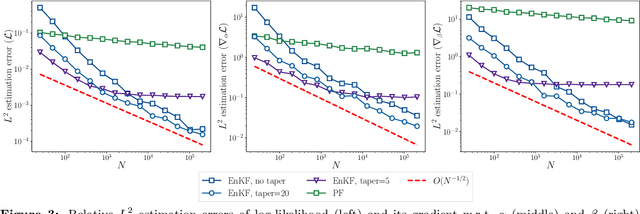
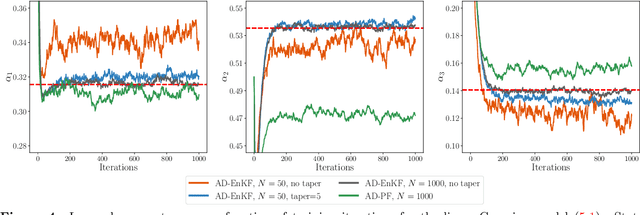
Data assimilation is concerned with sequentially estimating a temporally-evolving state. This task, which arises in a wide range of scientific and engineering applications, is particularly challenging when the state is high-dimensional and the state-space dynamics are unknown. This paper introduces a machine learning framework for learning dynamical systems in data assimilation. Our auto-differentiable ensemble Kalman filters (AD-EnKFs) blend ensemble Kalman filters for state recovery with machine learning tools for learning the dynamics. In doing so, AD-EnKFs leverage the ability of ensemble Kalman filters to scale to high-dimensional states and the power of automatic differentiation to train high-dimensional surrogate models for the dynamics. Numerical results using the Lorenz-96 model show that AD-EnKFs outperform existing methods that use expectation-maximization or particle filters to merge data assimilation and machine learning. In addition, AD-EnKFs are easy to implement and require minimal tuning.
Posterior Contraction Rates for Graph-Based Semi-Supervised Classification
Aug 26, 2020This paper studies Bayesian nonparametric estimation of a binary regression function in a semi-supervised setting. We assume that the features are supported on a hidden manifold, and use unlabeled data to construct a sequence of graph-based priors over the regression function restricted to the given features. We establish contraction rates for the corresponding graph-based posteriors, interpolated to be supported over regression functions on the underlying manifold. Minimax optimal contraction rates are achieved under certain conditions. Our results provide novel understanding on why and how unlabeled data are helpful in Bayesian semi-supervised classification.
Local Regularization of Noisy Point Clouds: Improved Global Geometric Estimates and Data Analysis
Apr 06, 2019
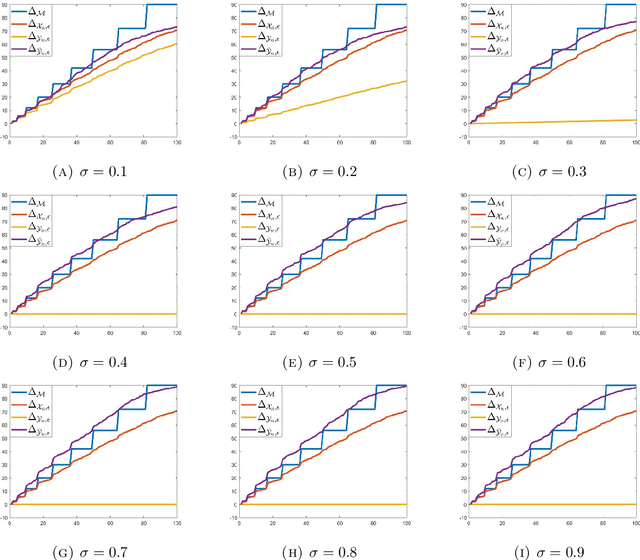

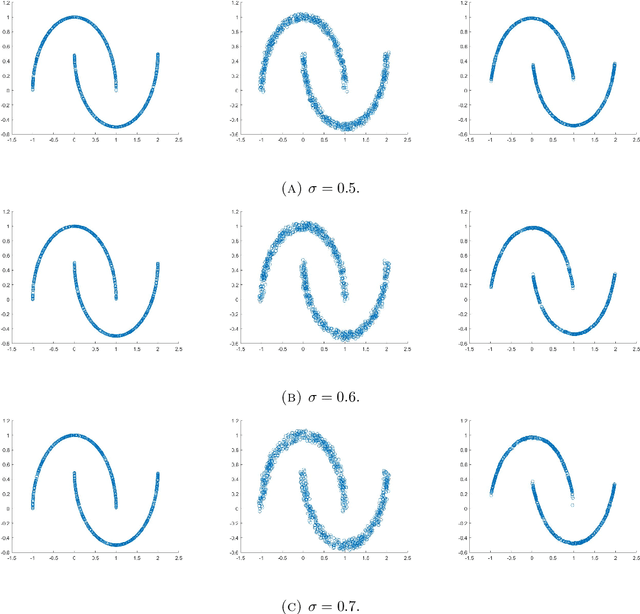
Several data analysis techniques employ similarity relationships between data points to uncover the intrinsic dimension and geometric structure of the underlying data-generating mechanism. In this paper we work under the model assumption that the data is made of random perturbations of feature vectors lying on a low-dimensional manifold. We study two questions: how to define the similarity relationship over noisy data points, and what is the resulting impact of the choice of similarity in the extraction of global geometric information from the underlying manifold. We provide concrete mathematical evidence that using a local regularization of the noisy data to define the similarity improves the approximation of the hidden Euclidean distance between unperturbed points. Furthermore, graph-based objects constructed with the locally regularized similarity function satisfy better error bounds in their recovery of global geometric ones. Our theory is supported by numerical experiments that demonstrate that the gain in geometric understanding facilitated by local regularization translates into a gain in classification accuracy in simulated and real data.
Variational Characterizations of Local Entropy and Heat Regularization in Deep Learning
Jan 29, 2019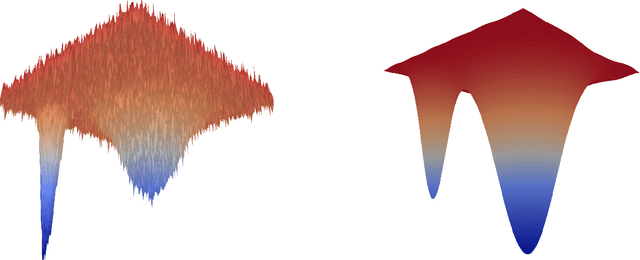
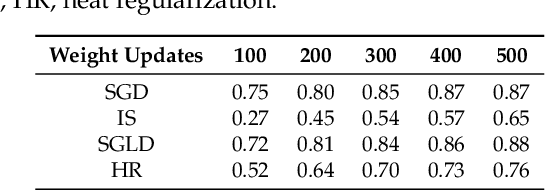
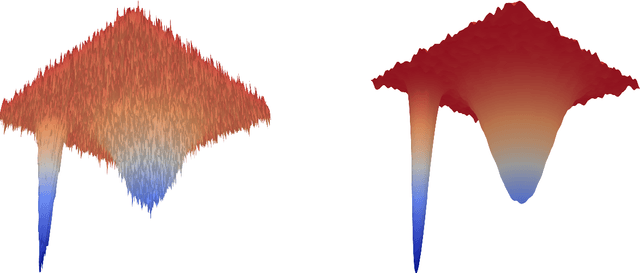
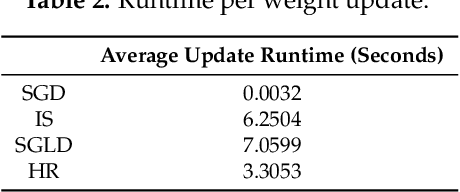
The aim of this paper is to provide new theoretical and computational understanding on two loss regularizations employed in deep learning, known as local entropy and heat regularization. For both regularized losses we introduce variational characterizations that naturally suggest a two-step scheme for their optimization, based on the iterative shift of a probability density and the calculation of a best Gaussian approximation in Kullback-Leibler divergence. Under this unified light, the optimization schemes for local entropy and heat regularized loss differ only over which argument of the Kullback-Leibler divergence is used to find the best Gaussian approximation. Local entropy corresponds to minimizing over the second argument, and the solution is given by moment matching. This allows to replace traditional back-propagation calculation of gradients by sampling algorithms, opening an avenue for gradient-free, parallelizable training of neural networks.
On the Consistency of Graph-based Bayesian Learning and the Scalability of Sampling Algorithms
Oct 20, 2017

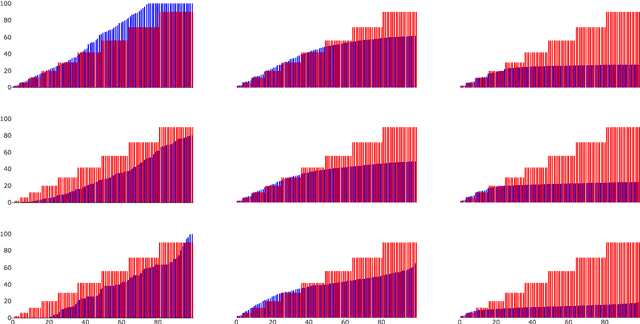
A popular approach to semi-supervised learning proceeds by endowing the input data with a graph structure in order to extract geometric information and incorporate it into a Bayesian framework. We introduce new theory that gives appropriate scalings of graph parameters that provably lead to a well-defined limiting posterior as the size of the unlabeled data set grows. Furthermore, we show that these consistency results have profound algorithmic implications. When consistency holds, carefully designed graph-based Markov chain Monte Carlo algorithms are proved to have a uniform spectral gap, independent of the number of unlabeled inputs. Several numerical experiments corroborate both the statistical consistency and the algorithmic scalability established by the theory.
Continuum Limit of Posteriors in Graph Bayesian Inverse Problems
Jun 22, 2017We consider the problem of recovering a function input of a differential equation formulated on an unknown domain $M$. We assume to have access to a discrete domain $M_n=\{x_1, \dots, x_n\} \subset M$, and to noisy measurements of the output solution at $p\le n$ of those points. We introduce a graph-based Bayesian inverse problem, and show that the graph-posterior measures over functions in $M_n$ converge, in the large $n$ limit, to a posterior over functions in $M$ that solves a Bayesian inverse problem with known domain. The proofs rely on the variational formulation of the Bayesian update, and on a new topology for the study of convergence of measures over functions on point clouds to a measure over functions on the continuum. Our framework, techniques, and results may serve to lay the foundations of robust uncertainty quantification of graph-based tasks in machine learning. The ideas are presented in the concrete setting of recovering the initial condition of the heat equation on an unknown manifold.