 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Word Sense Disambiguation with CLIP through Dual-Channel Text Prompting and Image Augmentations
Feb 06, 2026Ambiguity poses persistent challenges in natural language understanding for large language models (LLMs). To better understand how lexical ambiguity can be resolved through the visual domain, we develop an interpretable Visual Word Sense Disambiguation (VWSD) framework. The model leverages CLIP to project ambiguous language and candidate images into a shared multimodal space. We enrich textual embeddings using a dual-channel ensemble of semantic and photo-based prompts with WordNet synonyms, while image embeddings are refined through robust test-time augmentations. We then use cosine similarity to determine the image that best aligns with the ambiguous text. When evaluated on the SemEval-2023 VWSD dataset, enriching the embeddings raises the MRR from 0.7227 to 0.7590 and the Hit Rate from 0.5810 to 0.6220. Ablation studies reveal that dual-channel prompting provides strong, low-latency performance, whereas aggressive image augmentation yields only marginal gains. Additional experiments with WordNet definitions and multilingual prompt ensembles further suggest that noisy external signals tend to dilute semantic specificity, reinforcing the effectiveness of precise, CLIP-aligned prompts for visual word sense disambiguation.
Isolated Sign Language Recognition with Segmentation and Pose Estimation
Dec 16, 2025
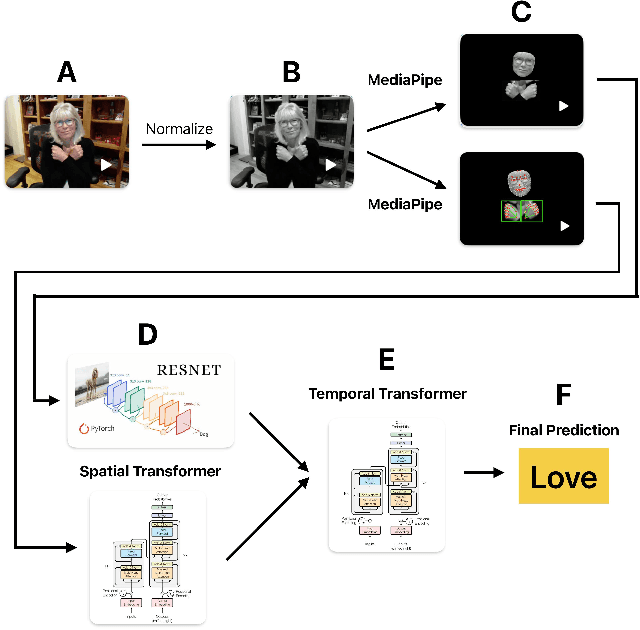
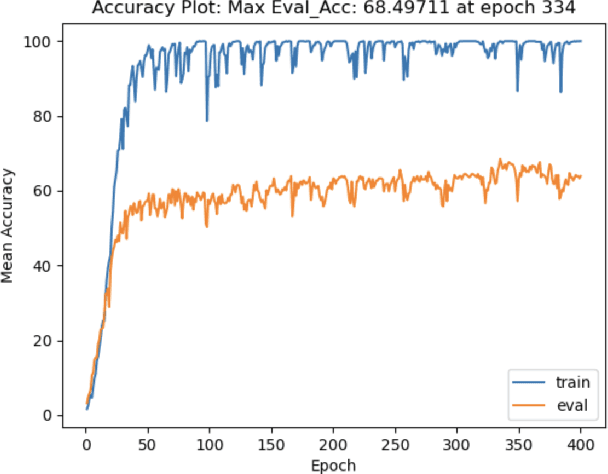
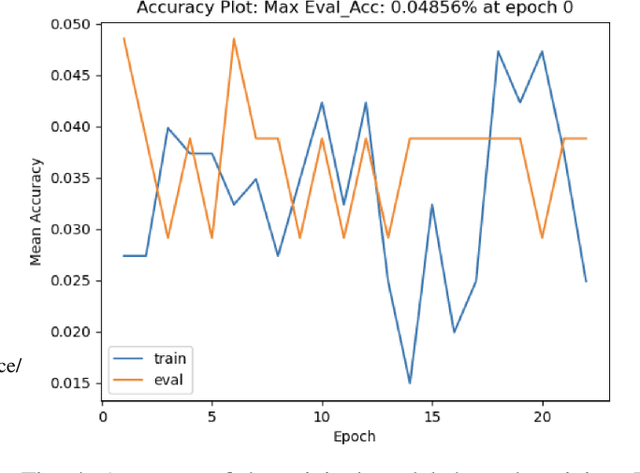
The recent surge in large language models has automated translations of spoken and written languages. However, these advances remain largely inaccessible to American Sign Language (ASL) users, whose language relies on complex visual cues. Isolated sign language recognition (ISLR) - the task of classifying videos of individual signs - can help bridge this gap but is currently limited by scarce per-sign data, high signer variability, and substantial computational costs. We propose a model for ISLR that reduces computational requirements while maintaining robustness to signer variation. Our approach integrates (i) a pose estimation pipeline to extract hand and face joint coordinates, (ii) a segmentation module that isolates relevant information, and (iii) a ResNet-Transformer backbone to jointly model spatial and temporal dependencies.
DQN Performance with Epsilon Greedy Policies and Prioritized Experience Replay
Nov 05, 2025



We present a detailed study of Deep Q-Networks in finite environments, emphasizing the impact of epsilon-greedy exploration schedules and prioritized experience replay. Through systematic experimentation, we evaluate how variations in epsilon decay schedules affect learning efficiency, convergence behavior, and reward optimization. We investigate how prioritized experience replay leads to faster convergence and higher returns and show empirical results comparing uniform, no replay, and prioritized strategies across multiple simulations. Our findings illuminate the trade-offs and interactions between exploration strategies and memory management in DQN training, offering practical recommendations for robust reinforcement learning in resource-constrained settings.